/img/star (2).png.webp)



/img/news (2).png.webp)
/img/event.png.webp)
Время прочтения: 3 мин.
Каждый раз после обучения модели дата-саентисту хотелось бы видеть краткий отчет по своей модели, над которой он работал. Это можно, конечно, делать руками, заготовив отдельный шаблон, но он, скорее всего, не будет универсальным решением в данной ситуации. Python, пожалуй, главный язык программирования в анализе данных и хорош он тем, что существует очень много библиотек, которые могут закрыть большинство ваших потребностей, связанных с анализом данных и машинным обучением. Поэтому сегодня рассмотрим библиотеку для создания таких отчетов. evidently помогает оценивать и контролировать модели в производственной среде, путем создания интерактивных отчетов в формате html или JSON из обычных CSV файлов или датафреймов. Давайте создадим свой первый отчет.
Установим саму библиотеку:
!pip install evidentlyДля начала импортируем pandas и sklearn (в качестве датасета возьмем стандартные «Ирисы Фишера», которые знакомы многим):
import pandas as pd
from sklearn import datasets, model_selection, neighbors
И, соответственно, evidently:
from evidently.dashboard import Dashboard
from evidently.tabs import ClassificationPerformanceTab
from evidently.model_profile import Profile
from evidently.profile_sections import ClassificationPerformanceProfileSection
Получаем данные:
iris = datasets.load_iris()
iris_df = pd.DataFrame(iris.data, columns = iris.feature_names)
Делим на тренировочную и тестовую части:
X_train, X_test, y_train, y_test = model_selection.train_test_split(iris_df, iris.target, random_state = 17)Возьмем модель k (в нашем случае k = 3) ближайших соседей и обучим на тренировочной части:
model = neighbors.KNeighborsClassifier(n_neighbors = 3)
model.fit(X_train, y_train)
Делаем предсказания и получаем результаты:
train_pred = model.predict(X_train)
test_pred = model.predict(X_test)
X_train['target'] = y_train
X_train['pred'] = train_pred
X_test['target'] = y_test
X_test['pred'] = test_pred
Добавим в соответствующие колонки сорт цветка:
X_train['target'] = X_train['target'].apply(lambda x: iris.target_names[x])
X_train['prediction'] = X_train['pred'].apply(lambda x: iris.target_names[x])
X_test['target'] = X_test['target'].apply(lambda x: iris.target_names[x])
X_test['prediction'] = X_test['pred'].apply(lambda x: iris.target_names[x])
Теперь подготовим информацию для самого отчета, создадим словарь, в который запишем какие столбцы являются целевыми и тд:
iris_columns = {}
iris_columns['target'] = 'target'
iris_columns['prediction'] = 'prediction'
iris_columns['numerical_features'] = iris.feature_names
Создаем дэшборд и передаем туда полученные данные, после чего сохраняем в html:
iris_dashboard = Dashboard(tabs=[ClassificationPerformanceTab])
iris_dashboard.calculate(X_train, X_test, column_mapping = iris_columns)
iris_dashboard.save('iris_dashboard.html')
Немного о результатах. Мы получили отчет в формате html (довольно тяжеловесный – 9 Мб), графики которого построены с помощью plotly. Отчет включает в себя:
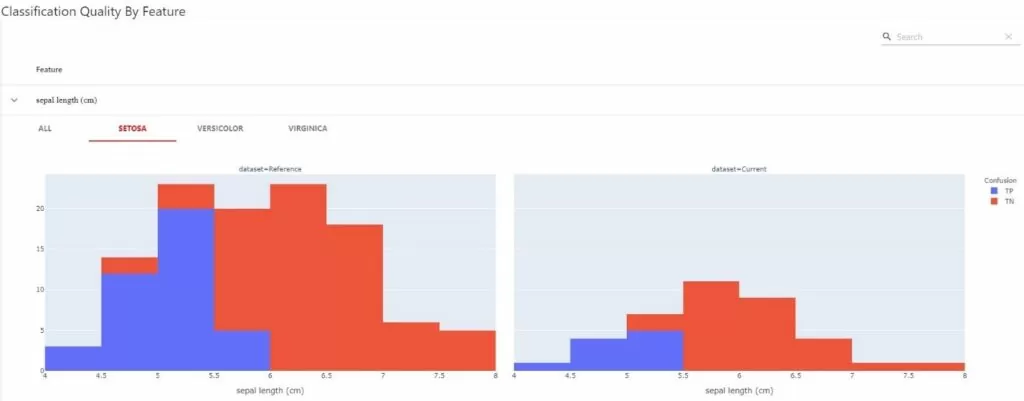
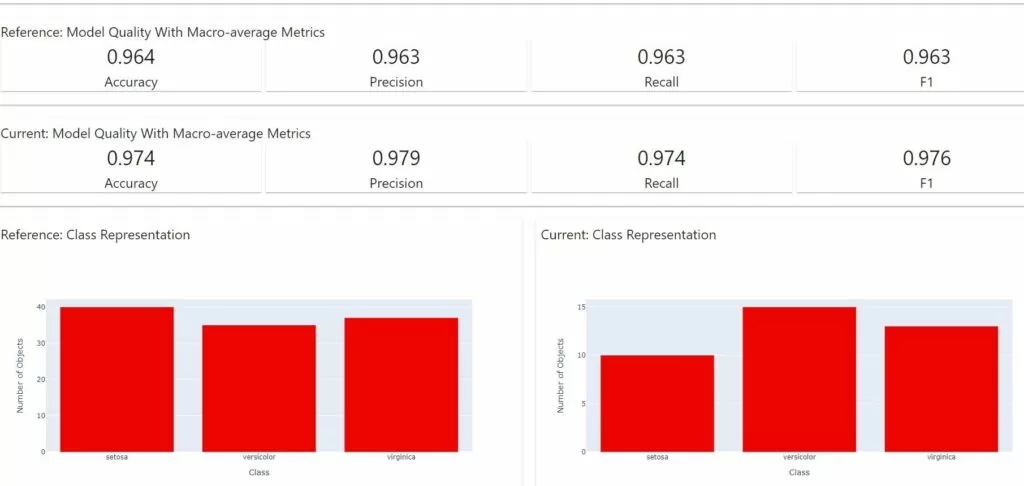
- Основные метрики и распределение таргетов по классам в тренировочной и тестовой части
2. Матрицы
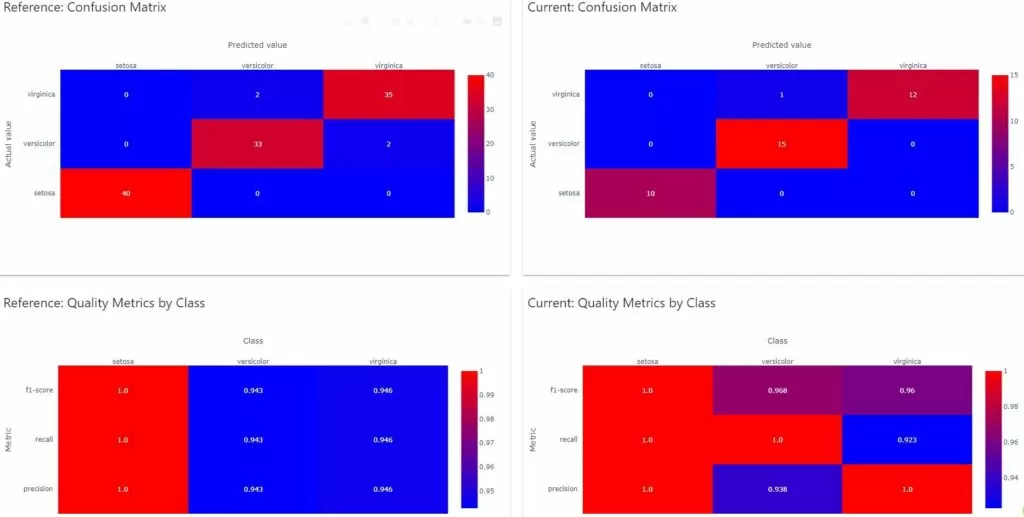
3. TP/TN в разрезе классов