/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 6 мин.
В данном посте я показываю способ обработки json строк с помощью языка программирования scala, когда схема файла заранее неизвестна или может быть изменена.
ВВЕДЕНИЕ
При работе с базами данных довольно часто возникает ситуация, когда столбец содержит статический json файл. Json формат основан на коллекции пар «ключ-значение» и может хранить различные типы данных, такие как строки, числа, логические значения, объекты и массивы. Если структура прописана, то чтобы распаковать эти данные по столбцам достаточно воспользоваться встроенной в spark функцией — from_json() или обратиться через ‘название поля’.’название ключа’.
Но что делать, если json является динамическим? Динамические json отличаются от статических json тем, что их структура, вложенность и длина могут сильно различаться между разными json. Мне стало интересно разобраться, как можно облегчить нахождение определенных ключей в нескольких динамических json. В данном посте я хочу поделиться своим вариантом обработки json строк на языке программирования scala. Результатом работы является датафрейм или файл, в котором хранится путь к тегу, его ключ и значение для одного заданного json файла.
1 АЛГОРИТМ РЕШЕНИЯ ЗАДАЧИ
Ключи среди пар ключ-значение при обработке могут дублироваться, поэтому необходимо хранить путь до ключа, который позволит однозначно их различать. Для этого удобно представить строку json в виде дерева. Деревья в программировании обеспечивают эффективное представление и организацию данных, особенно когда требуется иерархическое хранение или быстрый доступ к информации. Дерево состоит из узлов, связанных между собой отношениями родитель-потомок.
Рассмотрим основные компоненты дерева, которые я использовала при написании данного материала.
- Узел (Node): объект или элемент, хранящий какие-либо данные и имеющий одного или несколько детей (подчиненных узлов). Каждый узел, кроме корневого, имеет родительский узел.
- Корень (Root): верхний узел дерева, не имеющий родительского узла.
- Лист (Leaf): узел, не имеющий детей (потомков) — самый нижний уровень иерархии.
- Путь (Path): последовательность узлов, соединенных ребрами от корня к конечному узлу.
Разберем на примере задачу нахождения пути.
Рассмотрим json:
[{
"id": 1,
"first_name": "Jeanette",
"last_name": "Penddreth",
"email": "jpenddreth0@census.gov",
"gender": "Female",
"ip_address": "26.58.193.2"
}, {
"id": 2,
"first_name": "Giavani",
"last_name": "Frediani",
"email": "gfrediani1@senate.gov",
"gender": "Male",
"ip_address": "229.179.4.212"
}, {
"id": 3,
"first_name": "Noell",
"last_name": "Bea",
"email": "nbea2@imageshack.us",
"gender": "Female",
"ip_address": "180.66.162.255"
}, {
"id": 4,
"first_name": "Willard",
"last_name": "Valek",
"email": "wvalek3@vk.com",
"gender": "Male",
"ip_address": "67.76.188.26"
}]
Представим его в виде дерева:
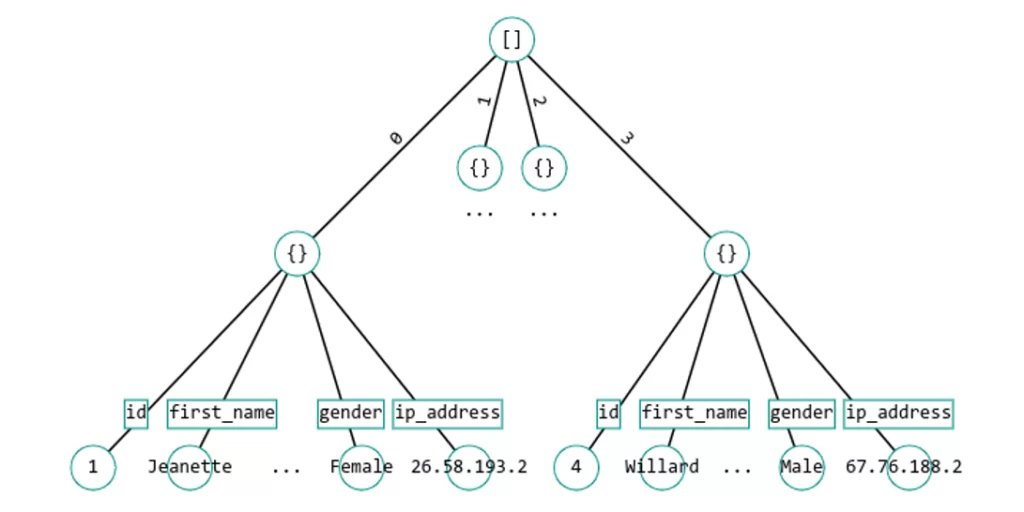
Обойдем дерево в глубину.

Получаем следующие пути:

2 ОПИСАНИЕ ОСНОВНЫХ ФУНКЦИЙ СКРИПТА
Для запуска кода я использую spark-shell. Для этого необходимо поставить spark, например, воспользовавшись этой инструкцией.
Для определения пути к текущему узлу необходимо обрабатывать 3 случая:
- путем для корневого узла является сам ключ,
- путь для массива записывается в формате:
‘путь до родительского узла'[‘индекс в массиве’],
- путь в остальных случаях записывается в формате:
‘путь до родительского узла’/’ключ текущего узла’.
private def buildPath(path: String, key: String): String = {
var newPath: String = null
if (path.isEmpty) return key
if (!key.isEmpty && key.charAt(0) == '[') newPath = path + key
else newPath = path + "/" + key
newPath
}
Если обрабатывать разные типы данных одним способом, то получится неверный результат. Поэтому, при чтении json строк, нужно определять тип узла и в соответствии с ним вызывать подходящий ему метод обработки. Всего можно выделить 3 метода.
- Если перед нами массив, то вызываем метод parseArray.
private def parseArray(outArray: java.util.List[Tuple3[String, String, String]], arrayNode: ArrayNode, path: String, key: String): Unit = {
val newPath = buildPath(path, key)
// для пустого массива добавляем значение '[]'
if (arrayNode.size == 0) {
outArray.add(new Tuple3[String, String, String](newPath, key, "[]"))
return
}
// обрабатываем все значения из массива
for (i <- 0 until arrayNode.size) {
addKeys(outArray, arrayNode.get(i), newPath, "[" + i + "]")
}
}
2. Если перед нами json объект, то вызываем метод parseObject.
private def parseObject(outArray: java.util.List[Tuple3[String, String, String]], objectNode: ObjectNode, path: String, key: String): Unit = {
val newPath = buildPath(path, key)
// для пустого объекта добавляем значение '{}'
if (objectNode.size == 0) {
outArray.add(new Tuple3[String, String, String](newPath, key, "{}"))
return
}
// обрабатываем дочерние узлы
val iterator = objectNode.fields
while (iterator.hasNext) {
val entry = iterator.next
val entryKey = entry.getKey
addKeys(outArray, entry.getValue, newPath, entryKey)
}
}
3. Для остальных случаев используем метод обработки значений (листьев дерева json)
private def parseValue(outArray: java.util.List[Tuple3[String, String, String]], valueNode: ValueNode, path: String, key: String): Unit = {
val newPath = buildPath(path, key)
// если с плавающей точкой число, складываем как double
if (valueNode.isFloatingPointNumber) outArray.add(new Tuple3[String, String, String](newPath, key, String.valueOf(valueNode.asDouble)))
// если булевое, то как булевое
else if (valueNode.isBoolean) outArray.add(new Tuple3[String, String, String](newPath, key, String.valueOf(valueNode.asBoolean)))
// если целое, то как целое
else if (valueNode.isIntegralNumber) outArray.add(new Tuple3[String, String, String](newPath, key, String.valueOf(valueNode.asLong)))
// в иных - как строку, заменяя пустые строки на null
else {
val text = valueNode.asText
outArray.add(new Tuple3[String, String, String](newPath, key, if (text == null || text.trim.isEmpty) "null"
else text.trim))
}
}
Теперь добавим ограничения, обработку особых случаев, добавим название json и получим полный скрипт.
3 ЗАПУСК СКРИПТА И РЕЗУЛЬТАТЫ
Запускаем в консоли spark-shell и вставляем наш скрипт.
Запустим json, который рассмотрели в примере выше:

Теперь запустим json большего размера — 13 мб.
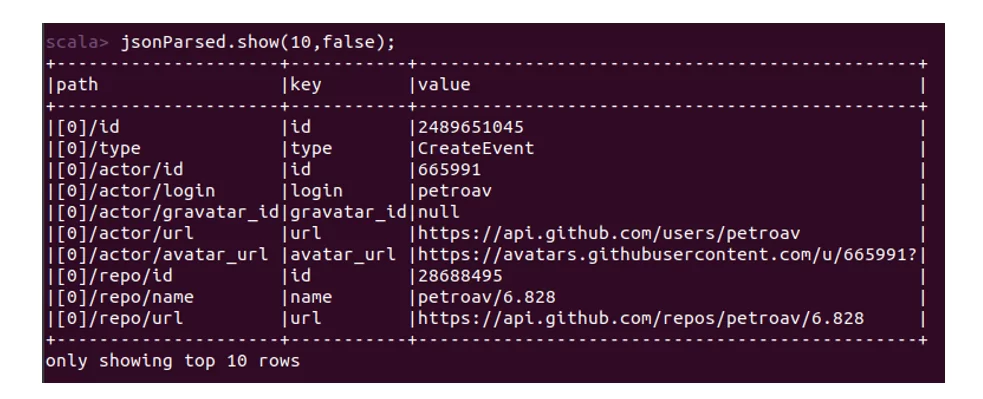
В данном посте я показала на примере, как можно обрабатывать json строки путем создания датафрейма: путь, ключ и значение.