/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 7 мин.
Иногда специфику работы дата-инженера можно описать следующей картинкой

И сейчас я расскажу почему: в одном проекте было необходимо использовать датасет, представляющий из себя около 5 млн. статей и связанных с ними сущностей (авторы, издательства, и т.д).
Отмечу, что перед командой стояла задача адаптировать и загрузить этот датасет в PostgreSQL. При адаптации датасета необходимо было сохранить все связи между сущностями «Статья»-«Автор», «Статья»-«Издательство», «Статья»-«Ключевое слово». Можно поспорить, что такой датасет можно сразу загрузить в MongoDB, ведь она является документоориентированной СУБД и гораздо лучше заточена для работы со слабоструктурированными сущностями, но в команде не было достаточных навыков работы с ней.
Датасеты поставляются в формате одного JSON-файла. Ниже привожу выдержку из описания датасета, составленного его авторами – с полной версией можно ознакомиться на странице датасета.
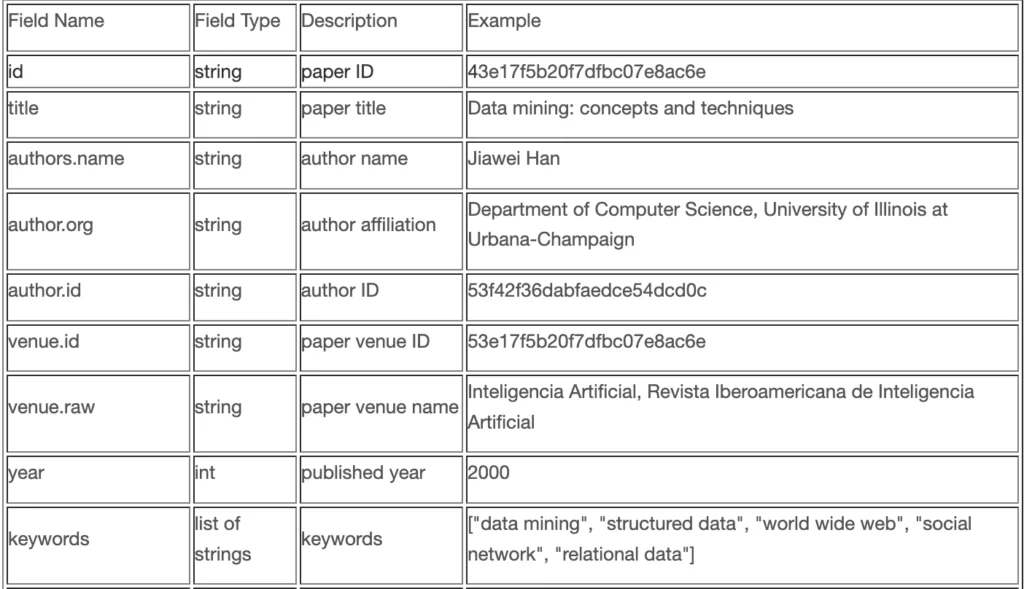
Какой вывод можно сделать из этого описания? У датасета есть структура, и она, на первый взгляд, кажется простой — создаётся впечатление, что датасет можно легко трансформировать в любой нужный нам вид. При его преобразовании в валидный для реляционных СУБД вид, достаточно будет извлечь отдельные столбцы, образовать связи между таблицами путем извлечения пар их ID. Так думал и я, решив, что преобразование этого датасета не займет много времени.
Первое, с чем пришлось столкнуться – впечатляющий размер датасета (17 ГБ) и встречающиеся иногда невалидные (нарушен синтаксис, баланс скобок) JSON-записи.
Второе — записи в датасете слабоструктурированы. Слабоструктурированные сущности в данном контексте – это сущности, под хранение которых нет чётко и однозначно описанной структуры данных, как в тех же реляционных СУБД. В соседних записях половина атрибутов может быть общей для всех, а другая половина — быть уникальной для данной конкретной записи.
Таким образом, требовалось понять, что датасет из себя представляет и провести разведочный анализ. Было решено подгружать датасет в pandas с разбивкой по группам строк (чанкам), т.к.:
- Сырой JSON-файл размером в 17 ГБ целиком не загрузить как в текстовый редактор, так и в словарь через библиотеку json. В pandas через доп.параметр chunksize этот момент можно контролировать.
- Неясно, сколько на самом деле атрибутов, как они форматированы в JSON, насколько сложно их будет читать в сыром виде. Pandas хотя бы на верхнем уровне может представить записи в виде таблицы с плоской структурой.
Как и ожидалось, связанные со статьей сущности (авторы, издания), оформлены не в виде плоской структуры (одна строка – одна статья – один автор), а в виде вложенных списков внутри столбцов таблицы:
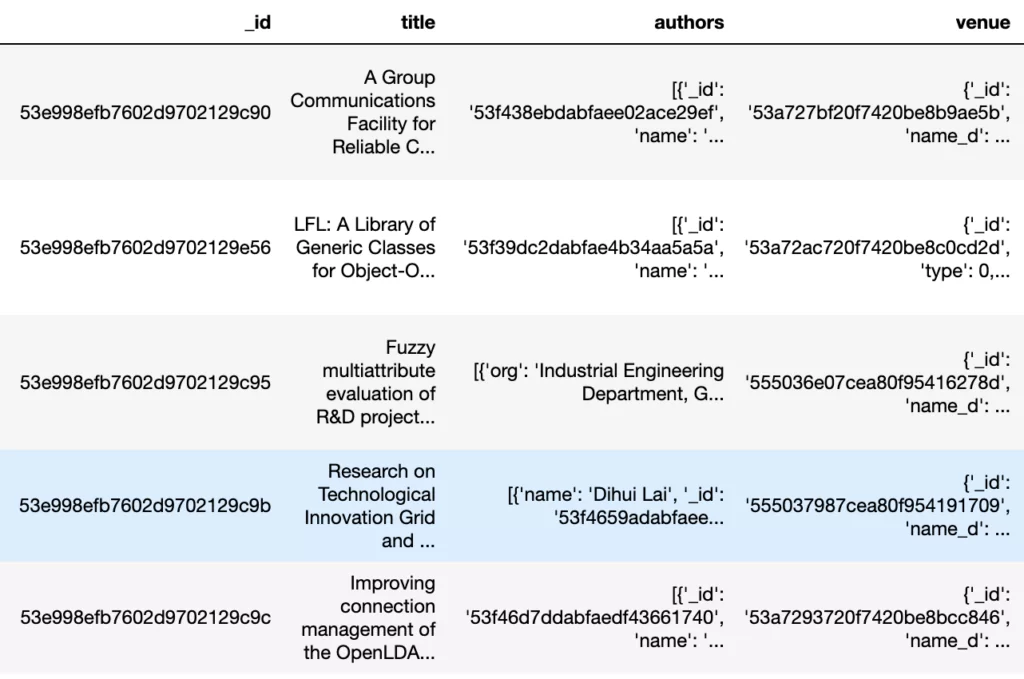
Для того чтобы такие отношения между статьями и авторами, изданиями корректно отразить в реляционной СУБД, нам необходимо выровнять сущности, нормализовать и правильно смоделировать связь «Многие-ко-многим».
Если эти термины незнакомы, покажу на пальцах, как это работает. Допустим, что имеется следующая таблица:
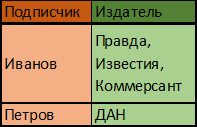
И нужно придерживаться следующего порядка действий:
- Преобразую таблицу в первую нормальную форму (1НФ):
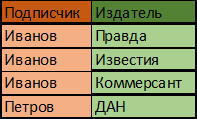
В новой структуре таблицы одной связи будет соответствовать ровно одна строка.
2. Дополнительно присвою каждому из значений столбцов уникальный ID:
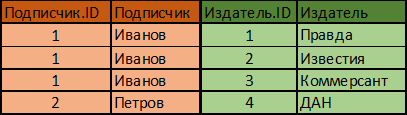
3. Разбиваю таблицу на две, а для их связи создаю дополнительную таблицу, в которой будут храниться пары ID подписчиков и издателей:

Естественно, пример, который я привёл выше, является сильно упрощенным «объяснением на пальцах», однако он позволяет продемонстрировать, что будет происходить дальше. Теперь я реализую это на Python:
import itertools
import pandas as pd
# читаем json порциями по 10000 записей
chunks = pd.read_json(raw_data_line, chunksize=10000, lines = True)
lst_authors = []
lst_paper_author = []
lst_venues = []
lst_references = []
i=0
# цикл обработки
for chunk in chunks:
chunk.fillna('', inplace = True)
#АВТОРЫ
paper_author_tuples = [([x[0]], x[1])
for x in list(zip(chunk['_id'], chunk['authors'].fillna('')))
if x[1] != '']
paper_author_pairs = [item for x in paper_author_tuples
for item in list(itertools.product(x[0],x[1]))]
paper_author_pairs = [(x[0], {k:v for k,v in x[1].items()
if k in ['_id', 'name', 'org']})
for x in paper_author_pairs ]
paper_author_pairs = fix_ids(paper_author_pairs)
paper_author = [{'paper_id': x[0], 'author_id': x[1]['_id']}
for x in paper_author_pairs]
authors = [x[1] for x in paper_author_pairs]
lst_paper_author.extend(paper_author)
lst_authors.extend(authors)
# Издательства (venues)
# аналогичная обработка, только у одной статьи не много издательств, а одно
# references
if 'references' in chunk:
references_tuples = [([x[0]], x[1])
for x in list(zip(chunk['_id'], chunk['references']))
if x[1] != '']
references_pairs = [item for x in references_tuples
for item in list(itertools.product(x[0],x[1]))]
lst_references.extend(references_pairs)
del chunk['references']
del chunk['authors']
chunk.to_csv(f'clearsets\\papers-{i}.csv', sep='\t', encoding='utf-8')
i+=1
# формируем csv с уникальными авторами и их id
pd.DataFrame(lst_authors).drop_duplicates(subset='_id').to_csv(f'clearsets\\authors.csv', sep='\t', encoding='utf-8')
# формируем csv со связями статей и авторов
pd.DataFrame(lst_paper_author).to_csv(f'clearsets\\paper_author.csv', sep='\t', encoding='utf-8')
# формируем csv со ссылками статей друг на друга
pd.DataFrame(lst_references).to_csv(f'clearsets\\references.csv', sep='\t', encoding='utf-8')
Пояснения к отдельным вызовам функций я прикрепил в комментариях. В целом, логика работы с датасетом соответствует той, что я описывал ранее.
# извлекаем пары значений (id статьи, [все авторы в статье])
paper_author_tuples = [([x[0]], x[1])
for x in list(zip(chunk['_id'], chunk['authors'].fillna('')))
if x[1] != '']
# раскрытие списков на вторых позициях кортежей
# создание уникальных пар (один id статьи, один автор)
paper_author_pairs = [item for x in paper_author_tuples
for item in list(itertools.product(x[0],x[1]))]
# фильтрация ключей в авторах, очистка от ненужных атрибутов
paper_author_pairs = [(x[0], {k:v for k,v in x[1].items()
if k in ['_id', 'name', 'org']})
for x in paper_author_pairs ]
# пары айдишников для связи авторов и статей
paper_author = [{'paper_id': x[0], 'author_id': x[1]['_id']}
for x in paper_author_pairs]
authors = [x[1] for x in paper_author_pairs]
lst_paper_author.extend(paper_author)
lst_authors.extend(authors)
Попробую выполнить этот код.

Оказывается, у некоторых авторов нет даже ID, о чем нам красноречиво сигнализирует эта ошибка.

Чтобы обойти этот недостаток датасета, напишу функцию генерации недостающих ID и интегрирую её в обработку.
import uuid
def fix_ids(pairs):
for pair in pairs:
if '_id' not in pair[1]:
pair[1]['_id'] = uuid.uuid4().hex[:24]
return pairs
# создаем отсутствующие айдишники
paper_author_pairs = fix_ids(paper_author_pairs)
Выбор 24-символьного UUID обусловлен тем, что этот формат ID уже применяется в датасете, и у меня нет особой потребности переделывать их под какой-то другой формат.
За скобками я оставил дополнительный скрипт, который проверяет уникальность каждого ID – поскольку ID будут использоваться как первичные ключи таблиц, необходимо исключить их дублирование. Хотя эта проверка у меня не выявила дублирования (кстати, СУБД тоже нормально приняла датасет). Этими проверками пренебрегать не стоит.
После того как датасет обработан, остается залить его в заранее подготовленные таблицы и можно спокойно им пользоваться.

Подведу итоги.
Когда вы сталкиваетесь с большим ненормализованным датасетом, да еще и в формате JSON, который нужно переложить в связанные SQL-таблицы, необходимо:
- Читать датасет по чанкам;
- Анализировать датасет на качество, смотреть на атрибуты;
- Нормализовать датасет, раскрывать связи между сущностями и следить за их целостностью.
В целом, знание этих пунктов позволит сразу адаптировать датасет под реляционные СУБД и значительно сократить время, затраченное на его обработку, ведь со структурной точки зрения его не потребуется переделывать бессчётное количество раз. А для всего остального – есть функционал SQL. Удачи!