/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 7 мин.
Друзья! Сегодня расскажу, как я использовал функции и процедуры в Greenplum и как мне удалось существенно оптимизировать запрос с использованием функции.
Итак, задача была следующая: выгрузить информацию по арендным ставкам определённых классов офисов (A, A+, B, B+, C, C+), расположенных в разных регионах, за период с 2017 года по настоящее время из базы данных организации, содержащей сведения об арендаторах, адресах офисов и их типах, арендных ставках.
При выполнении такого запроса, меня ожидали следующие проблемы:
- длительное выполнение запроса;
- необходимость повторного написания запроса при изменении требований к получению информации (например, при необходимости выгрузки дополнительных столбцов);
- возможные ошибки при многократном использовании одних и тех же запросов в разных частях кода.
Немного поясню, что такое функции и процедуры в SQL.
Функции и процедуры представляют собой блок кода или запросов, хранящихся в базе данных, которые можно использовать повторно. Т.е. вместо того, чтобы раз за разом писать одни и те же запросы, мы просто группируем и сохраняем их в памяти СУБД. Основная разница между ними в том, что функция возвращает значение, а процедура нет.
В SQL функции помогают обрабатывать, группировать и изменять данные. Например, можно создать функцию для выборки данных из таблицы по определённым условиям или для подсчёта суммы данных по определённому критерию. Функции можно использовать для автоматизации рутинных задач.
Для решения своей задачи я использовал следующий SQL-запрос:
select region,
city,
street,
house,
building,
building_class,
square, created_dt,
deal_type,
offer_type
from information_db.table
where created_dt>'2017-04-12'
and building_class in ('B','B+','A','A+','C','C+')
and deal_type ='rent'
and offer_type like '%office%'
and region in ('Москва','Свердловская область','Новосибирская область')
group by offer_type,
building_class,
deal_type,
region,
city,
street,
house,
building,
deal_type,
offer_ type, square,
created_dt
order by created_dt asc
;
Ниже буду ссылаться на этот запрос, как — «SQL-запрос».
Также данную задачу можно решить с использованием функции:
CREATE FUNCTION get_category_ordersq()
RETURNS TABLE (region_1 TEXT,
city_1 text,
street_1 text,
house_1 text,
building_1 text,
building_class_1 text,
square_1 text,
created_dt_1 text,
deal_type_1 text,
offer_type_1 text) AS $$
BEGIN
RETURN QUERY
«SQL-запрос»
END;
$$ LANGUAGE plpgsql;
Чтобы не приходилось запускать один и тот же запрос, я использовал функцию get_category_ordersq() для вызова, это позволило минимизировать ошибки при повторном выполнении запроса, и сократить время его выполнения.
select * from get_category_ordersq();В SQL используются процедуры для создания, изменения и удаления функций, что как раз можно делать в СУБД Greenplum. Так, для создания функции get_category_ordersq();я использовал следующую процедуру:
CREATE FUNCTION get_category_ordersq()
RETURNS TABLE (region_1 TEXT,
city_1 text,
street_1 text,
house_1 text,
building_1 text,
building_class_1 text,
square_1 text,
created_dt_1 text,
deal_type_1 text,
offer_type_1 text) AS $$
BEGIN
RETURN QUERY
«SQL-запрос»
END;
$$ LANGUAGE plpgsql;
Процедура CREATE FUNCTION используется для создания или замены существующей функции. Она принимает имя функции, список аргументов и тип возвращаемого значения. Затем она определяет тело функции и заключённое в блок $$ … $$. В работе я использовал не только процедуру создания, но и другие процедуры: ALTER FUNCTION- для изменения существующих функций, DROP FUNCTION- для удаления функций, SHOW FUNCTION -для отображения информации о функциях.
Сравнение нескольких вариантов решения задачи
Хочу продемонстрировать решение своей задачи, с использованием следующих методов: простого запроса, запроса с функцией, анализируя их с помощью команд explain, explain analyze.
Решение с помощью простого запроса
Для выполнения задачи с помощью запроса я использовал «SQL-запрос».
При выполнении запроса данные были получены за 25 c. Выясню, как они были выбраны для запроса, нужно ли использовать какой-то оптимизатор или он уже используется.
План запроса
Для анализа того, какой оптимизатор использовал Greenplum, и как выполнялся запрос, поможет команда explain, который позволяет получить информацию о предварительном плане выполнения SQL-кода:
explain «SQL-запрос»Результат:
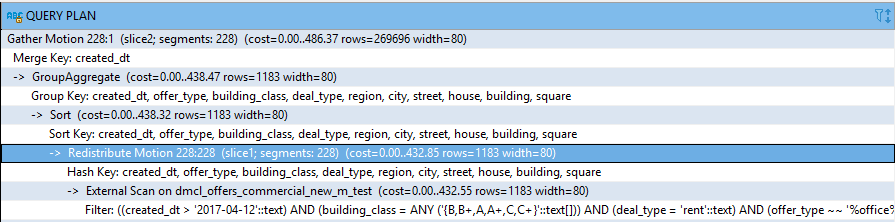
Как видим, сначала СУБД ожидает полное получение информации от БД на выполнение запроса, а уже затем использует группировку информации.
Действительный план выполнения запроса
Для того, чтобы получить информацию о том, сколько времени затратит сервер на выполнение запроса, я использовал команду explain analyze, который позволяет мне узнать информацию о том, как он будет выполнен в базе данных.
begin;
explain analyze
«SQL-запрос»
rollback;
Результат:

Разница в выполнении запроса связана с нагрузкой на сервер или с тем, что может быть неправильно оптимизирован запрос.
Решение с помощью запроса функции
Решить задачу можно также с помощью функции SQL следующим образом:
CREATE FUNCTION get_category_ordersq()
RETURNS TABLE (region_1 TEXT,
city_1 text,
street_1 text,
house_1 text,
building_1 text,
building_class_1 text,
square_1 text,
created_dt_1 text,
deal_type_1 text,
offer_type_1 text) AS $$
BEGIN
RETURN QUERY
«SQL-запрос»
END;
$$ LANGUAGE plpgsql;
select * from get_category_ordersq();
Результат выполнения запроса 26 с. Опишу, как были выбраны данные для запроса, нужно ли использовать какой-то оптимизатор или он уже используется в функции.
Предварительный план выполнения запроса функции
Здесь, при выполнении данного запроса, я использовал команду explain, который помог мне проанализировать результат выполнения функции:
explain select * from get_category_ordersq();Результат:

Можно заметить, что применяется метод function scan, который используется для сканирования таблицы с целью отбора нужных строк. Посмотрим сколько понадобится времени (планового и фактического) на выполнение запроса серверу.
Действительный план выполнения запроса функции
Здесь я использовал команду explain analyze, чтобы получить информацию о том, как будет выполнен следующий SQL-код на сервере:
begin;
explain analyze
select * from get_category_ordersq();
rollback;
Результат запроса:

Из-за большого количества данных в таблице запрос выполнялся дольше, чем планировалось. Возможно, разница связана с разными подходами во время запроса. Решить такую проблему можно с помощью оптимизации функции для эффективной работы.
Решение с помощью запроса функции с оптимизатором
Для того чтобы оптимизировать функцию, можно использовать оптимизаторы, которые встроены в Greenplum, но я использовал GPORCA. Как правило, оптимизатор GROPCA лучше встроенного, он немного видоизменяет план запроса, подробнее здесь
CREATE FUNCTION get_category_ordersq()
RETURNS TABLE (region_1 TEXT,
city_1 text,
street_1 text,
house_1 text,
building_1 text,
building_class_1 text,
square_1 text,
created_dt_1 text,
deal_type_1 text,
offer_type_1 text) AS $$
BEGIN
set local optimizer = on;
RETURN QUERY
«SQL-запрос»
END;
$$ LANGUAGE plpgsql;
select * from get_category_ordersq();
Используя GROPCA, я добился существенной оптимизации функции, что видно по результатам запроса:

Сравнение и выводы разных подходов к задаче
| Обычный запрос | Запрос с функцией | Запрос с оптимизатором | Запрос с оптимизатором в функции | |
| Плановое время выполнения | 24.145 мс | 3.788 мс | 28.305 мс | 3.9 мс |
| Затраченное время выполнения(тест 1) | 27370.227 мс | 26084.936 мс | 17174.397 мс | 11123.617 мс |
| Затраченное время выполнения(тест 2) | 21489.038 мс | 20080.203 мс | 16469.331 мс | 13146.614 мс |
| Затраченное время выполнения(тест 3) | 26444.144 мс | 17237.300 мс | 18737.174 мс | 9521.363 мс |
| Среднее | 25101.135 мс | 21134.145 мс | 17460.301 мс | 11263.865 мс |
Напомню, что я использовал обычный запрос и запрос с функцией, при этом сравнивал, сколько времени затратит запрос по предварительному и действительному плану выполнения.
При проверке исключено влияние кэша запросов. Указанно среднее время выполнения запроса (так как для исключения влияния мгновенной нагрузки на кластер было произведено пять измерений (для каждого значения))
Для ускорения работы функции и запроса я использовал оптимизатор GROPCA, который корректирует план выполнения запроса и более рационально использует ресурсы, что сказалось на времени выполнения. Использование оптимизаторов в работе экономитвремя на исполнении запроса, так как он помогает СУБД наиболее эффективно спланировать выполнение.
При решении моей задачи использование оптимизатора помогло сократить время на выполнение запроса с функцией на 46%, а обычный запрос на 30%.
При написании функции рекомендую сразу указывать оптимизатор, чтобы избавить себя от необходимости указывать его перед каждым запросом. Всем успехов!