/img/star (2).png.webp)






/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 7 мин.
Накопление данных для дальнейшего анализа и исследования — это процесс создания (очистки, преобразования) данных, загрузки в базу данных, хранения, поддержания в актуальном состоянии этих данных с возможностью выполнения определенных функциональных задач СУБД SQL Server. И все нужные данные должны извлекаться быстро и в достаточном объеме по запросу пользователя СУБД.
То, как выполняется генерация данных и затем вставка их в таблицы SQL Server, может отразиться не только на рациональности обслуживания БД, но и на ее производительности. Важность данного вопроса нередко упускается из виду пользователями СУБД. Если не принимать это во внимание, то в дальнейшем могут возникнуть трудности для администраторов и разработчиков, участвующих в сопровождении и обслуживании базы данных.
В данной статье предлагаю обратить внимание на некоторые способы создания и добавления данных в БД, которые могут помочь оптимизировать SQL-скрипты, дизайн БД, уменьшить вероятность ошибок при создании и обслуживании объектов БД для ваших задач.
Создадим небольшую тестовую таблицу, в которую в дальнейшем будут добавляться некоторые регистрационные данные клиента:
create table client
(client_id int not null identity(1,1) constraint pk_client primary key clustered
,client_name varchar(100) not null
,client_registry date not null
,client_addr varchar(1000) not null
,client_type varchar(10) not null
,client_comment varchar(500) null
,client_valid bit not null
);
Вставка данных с помощью явного указания столбцов.
Первый простой пример вставки – используем оператор insert с явным указанием всех столбцов таблицы client:
insert into client
(client_name,client_registry,client_addr,client_type,client_comment,client_valid)
values
('Иванов Иван И.'
,'2021.02.01'
,'г.N-ск, ул.Большая, д №n'
,'Резидент'
,'Индивидуальный предприниматель'
,1);
Вставка данных с исключением столбцов из списка.
Теперь вставим еще данные в таблицу, исключив некоторые столбцы из списка. Для этого примера можно использовать столбцы, допускающие значение NULL, в нашем случае это client_comment, или столбцы, имеющие значения по умолчанию.
insert into client
(client_name,client_registry,client_addr,client_type,client_valid)
values
('Александров Александр А.'
,'2021.02.02'
,'г.M-ск, пер.Малая, д №m'
,'Резидент'
,1);
Проверим работу этих скриптов:
select * from client;

Видно, что для второй строки (client_id = 2) в скрипте при вставке не указан столбец client_comment и в таблице было назначено значение NULL для него.
Далее, для демонстрации примера вставки данных, добавим в столбец client_comment ограничение по умолчанию:
alter table client
add constraint df_client_comment default ('NO COMMENT') for client_comment;
Теперь, имея это ограничение, продемонстрируем еще одну вставку данных insert, где опускается столбец client_comment
insert into client
(client_name,client_registry,client_addr,client_type,client_valid)
values
('Федоров Федор Ф.'
,'2021.02.02'
,'г.M-ск, ул.Пятая, д №xx'
,'Резидент'
,0);
select * from client;

Преимущество вставки данных с явным указанием списка столбцов в том, что точно прописывается, какие из этих столбцов заполняются и какие данные помещаются в определенный столбец. Явно указанный список столбцов при вставке затрудняет случайное исключение столбцов. Причем, если столбец исключен из списка вставки – будет назначено значение NULL.. Если столбец NOT NULL и без ограничения по умолчанию будет исключен из списка, то при вставке данных будет выдана ошибка:

Недостаток этого способа — это неудобство сопровождения в сценариях, где схема таблицы может часто меняться.
Вставка данных без явного списка столбцов.
Другой способ вставки данных в созданную таблицу без списка столбцов можно выполнить так:
insert into client
select
'Фамилия Имя О.'
,'2021.02.03'
,'г.MMM, ул.Большая, д №mmm'
,'Резидент'
,'Владелец бизнеса'
,1;
Плюс этого способа — это то, что он быстрый и требует меньшего обслуживания, т.к. здесь нет необходимости указывать и поддерживать список столбцов при вставке. Недостаток — если неверно сопоставить вставляемые данные столбцам, получаем сообщение об ошибке (например, не указываем данные для столбца client_comment):
insert into client
select
'Фамилия Имя О.'
,'2021.02.03'
,'г.MMM, ул.Большая, д №mmm'
,'Резидент'
,1;

Используйте этот способ, если удобство более простого синтаксиса в вашем уникальном проекте преобладает перед недостатком, который может возникнуть от нарушения кода в будущем, например, при изменении схемы таблицы. Можно улучшить этот код, добавив псевдонимы ко всем столбцам, в которые вставляются данные:
insert into client
select
'ФИО' as client_name
,'2021.02.04' as client_registry
,'г.MMM, пр.Широкий, д №y' as client_addr
,'Резидент' as client_type
,'Социальный работник' as client_comment
,0 as client_valid;
или указать комментарий:
insert into client
select
'ФИО_2' -- фио клиента
,'2021.02.04' -- дата регистрации
,'г.M_2, пр.Широкий, д №y/2' -- адрес клиента
,'Резидент' -- тип клиента
,'Свободный художник' -- комментарий
,1 -- код активности;
Вставка данных с помощью select into.
Другой пример кода — создание временной таблицы и выбор данных в ней как часть одного оператора.
select
'Петров Петр П.' as employee_name
,'PetrovPP' as user_login
,'Отдел разработки' AS Department
,1 as active
into #employee_inf;
Данный способ может быть удобным и в случае использования постоянных таблиц, если сценарий проекта предполагает это.
Временная таблица создается «на лету» с указанными в коде именами столбцов. Причем SQL Server автоматически определяет тип данных для столбцов.
Чтобы посмотреть тип данных и размер столбцов этой временной таблицы выполним код:
select
tables.name as TableName,
columns.name as ColumnName,
columns.max_length as ColumnLength,
types.name AS TypeName
from TempDB.sys.tables
inner join TempDB.sys.columns
on tables.object_id = columns.object_id
inner join TempDB.sys.types
on types.user_type_id = columns.user_type_id
where tables.name like '#employee_inf%';
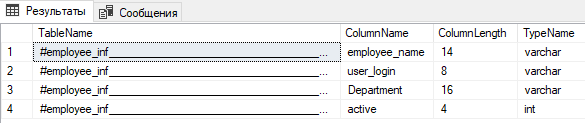
Размеры столбцов соответствуют минимально необходимым размерам вставляемых данных. Это может быть удобно, если в дальнейшем не потребуется добавлять дополнительно новые данные в эту временную таблицу. В противном случае необходимо быть уверенным, что новые добавляемые данные не превысят уже определенные размеры столбцов. Однако, можно заранее определить тип данных и размер столбцов самостоятельно:
select
cast('Петров Петр П.' as varchar(50)) as employee_name
,cast('PetrovPP' as varchar(25)) as user_login
,cast('Отдел разработки' as varchar(25)) as Department
,cast(1 as bit) as active
into #employee_inf;
Select into удобен, когда вставляются в таблицу данные, отличающиеся раз от раза или часто меняется схема данных, и это приводит к некоторым сложностям обслуживания списка столбцов. К недостатку можно отнести то, что результирующая таблица не имеет индексов и ограничений, их необходимо создать в дальнейшем дополнительно. Но, если для вашего сценария в этом нет необходимости, то использование select into в таком случае — это способ сократить код и применять его при возможном изменении определения данных или базовой схемы вашего проекта.
Вставка данных, используя хранимую процедуру.
Следующий код использует хранимую процедуру sys.sp_who2 для возврата данных в созданную временную таблицу:
create table #table_process
( sp_id varchar(100)
,t_status varchar(100)
,t_login varchar(100)
,t_hostname varchar(100)
,t_blkby varchar(100)
,t_dbname varchar(100)
,t_command varchar(100)
,t_cputime varchar(100)
,t_diskit varchar(100)
,t_latbatch varchar(100)
,t_programname varchar(100)
,t_spid2 varchar(100)
,t_requestid varchar(100))
insert into #table_process
exec sys.sp_who2;
select * from #table_process;
drop table #table_process;
Таким образом в приведенном примере выполнение хранимой процедуры sys.sp_who2 возвращает список текущих соединений SQL Server. Создав заранее временную таблицу #table_process и вставив эти данные в нее, получим возможность фильтрации набора результатов по необходимым критериям. Так же это можно применить и для постоянной таблицы.
В ряде существующих методов вставки данных выбирайте тот, который больше отвечает требованиям вашего проекта:
insert с явным списком столбцов для приложений, в которых списки столбцов, входные и выходные данные меняются не часто;
insert без указания списка столбцов – для сценариев, в которых столбцы могут быть неизвестны заранее или меняются довольно часто;
select into для создания временной структуры данных, и далее для вставки временных данных в постоянную таблицу с использованием формального списка столбцов.