/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
Xes – принятый повсеместно для Process Mining формат логов, написанный на языке XML.
XML – язык разметки документов в форматах xml, xes, rss, xhtml, fb2, широко используемый во всех областях IT. Этот формат не табличный и требует предварительной обработки перед комфортным просмотром.
Пример такой разметки xes файла, открытого в блокноте:

Любой документ в формате XML начинается с корневого элемента – это обязательная часть документа. Он может включать вложенные в него элементы и символьные данные.
Вложенные элементы, в свою очередь, могут включать вложенные элементы и символьные данные и так далее. Символьные данные бывают трех типов – тэги (названия элементов), атрибуты (характеристики элементов в виде пар ключ-значение) и привязанный к элементам текст. Получается, что схема данных хранится вместе с самими данными в виде структуры связей между элементами, и может быть неочевидна на первый взгляд.
Часто к XML файлам прилагаются описания схемы данных, помогающие при извлечении информации – они могут быть на сайте, с которого была скачана xml, или в текстовом поле корневого элемента, но бывает так что этой схемы нет, или она применима не ко всем элементам, или описывает не все типы символьных данных. Схема данных xes статична и расположена по ссылке
Если схема данных известна, данные нетрудно извлечь неавтоматическим способом, как было описано ранее в статье NTA
Но бывает так что схема данных неизвестна, поэтому решение нужно универсальное.
Когда мы говорим о парсинге, мы подразумеваем запись символьных данных из документа в формате xml в таблицу. Иерархические связи между элементами, порой, гораздо сложнее, чем таблица, поэтому для автоматического извлечения данных придется эти связи тем или иным образом учитывать и раскладывать в строки таблицы, записывая отдельные символьные данные в разные колонки (далее – фичи).
Проблема же неизвестной глубины вложенности легко решается при помощи рекурсии. Этот процесс мы тоже освещали в другой стате NTA
Мы будем проверять каждый элемент на наличие вложенных элементов, и если они будут, то мы будем проверять их на наличие вложенных элементов и так далее. Важным плюсом табличного подхода будет возможность исправить все ошибки чтения, кодировки, форматов времени и прочего, что может помешать нам использовать xes файл в чувствительных к этому программных продуктах. В качестве примера публично доступных логов используем информацию с соревнований BPIC 2020
Для автоматической обработки мы просто предположим, что каждому элементу, вложенному в корневой элемент, соответствует одна строка таблицы. Возникнет проблема повторяющихся фич, ведь более глубоко вложенные элементы повторяются. Решить эту проблему можно несколькими путями – просто игнорировать повторения, склеивать их в одну строку, дописывать их в list внутри ячейки таблицы или даже создавать новые строки или столбцы. Наиболее универсальным решением является запись в list, поскольку структура результирующей таблицы (в данном случае, pandas dataframe) не будет нарушенной, при этом данные сохранят гибкость обработки.
import xml.etree.cElementTree as et
import pandas as pd
name="PrepaidTravelCost.xes_"
tree=et.parse(name)
root=tree.getroot()
depth = 0
element_list = []
for i in range(1,len(root)):
tempdict = {}
tempdict = recursive_xml_parse(root[i],tempdict,depth)
element_list.append(tempdict)
xml_df = pd.DataFrame(element_list,dtype = "str")
xml_df.T
При помощи встроенной библиотеки xml.etree получим список элементов, входящих в корневой элемент root. Одной ячейке результирующей таблицы будет соответствовать один из этих элементов. Для превращения их содержимого в строку к каждому из них применится рекурсивная функция recursive_xml_parse:
def recursive_xml_parse(xml_node,global_dict,depth):
depth = depth+1
tempdict_inner = xml_node.attrib #extract information from element
tempdict_inner["tag"+str(depth)] = xml_node.tag #also extract tag and text.
if (xml_node.text!=None):
tempdict_inner["text"+str(depth)] = xml_node.text
#check if global dictionary has keys that we just extracted
for key,value in tempdict_inner.items():
if key in global_dict.keys():
try: #try to append value if key exists
global_dict[key].append(value)
except: #create list if not
global_dict[key] = [global_dict[key],value]
else: #add key if it wasnt in global dictionary
global_dict[key] = value
for xml_inner_node in xml_node: #call recursively
global_dict = recursive_xml_parse(xml_inner_node,tempdict,depth)
return global_dict
Она работает в рамках одного элемента xes файла, извлекая его атрибуты, тэг и текст, дописывая их в словарь, каждый ключ которого будет являться колонкой в таблице. Если ключ повторяется, функция присоединяет новые значения в список к старым. Поскольку у тэга нет содержимого, само его название записывается в колонку tag с номером глубины вложенности.
Результат обработки приведен ниже. Для наглядности колонки транспонированы:
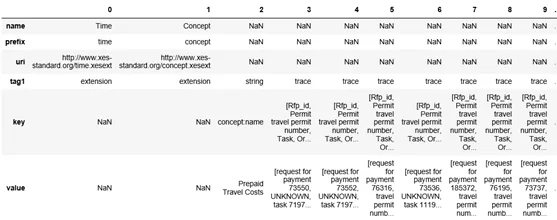
Видно, что важные для Process Mining данные находятся в атрибутах key и value, при этом все прочие атрибуты нам не пригодится. Для получения пригодного для process mining датасета достаточно лишь присвоить каждому значению списков из колонки key соответствующие значения списков из колонки value:
templist = []
xml_df_cut = xml_df[3:]
for x in range(3,len(xml_df_cut)):
tempdict = {}
for y in range(len(xml_df_cut["key"])):
try:
tempdict[xml_df_cut["key"][x][y]] = xml_df_cut["value"][x][y]
except:
pass
templist.append(tempdict)
df = pd.DataFrame(templist)
df.head().T
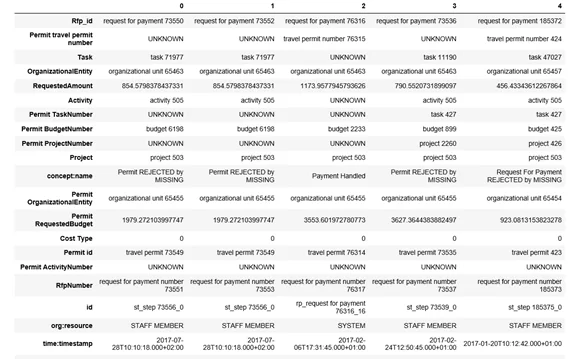
Полученная таблица гораздо нагляднее исходного файла, при этом ее можно с тем же успехом использовать в Process Mining, как и xes файл, а также сохранить в excel. На этом же этапе можно исправить понимаемый не всеми программами формат даты:
df["fixed_timestamp"] = pd.to_datetime(df["time:timestamp"],utc=True).dt.date.astype("str")Этот код так же сработает и для любого другого xml файла – вот пример парсинга единого реестра малого и среднего бизнеса, размещенного по ссылке
Скачаем один файл и прогоним его через тот же код, изменив лишь
name = "VO_RRMSPSV_0000_9965_20200513_0a81f9cc-dc17-4f8e-b30b-f524338ed8bd.xml"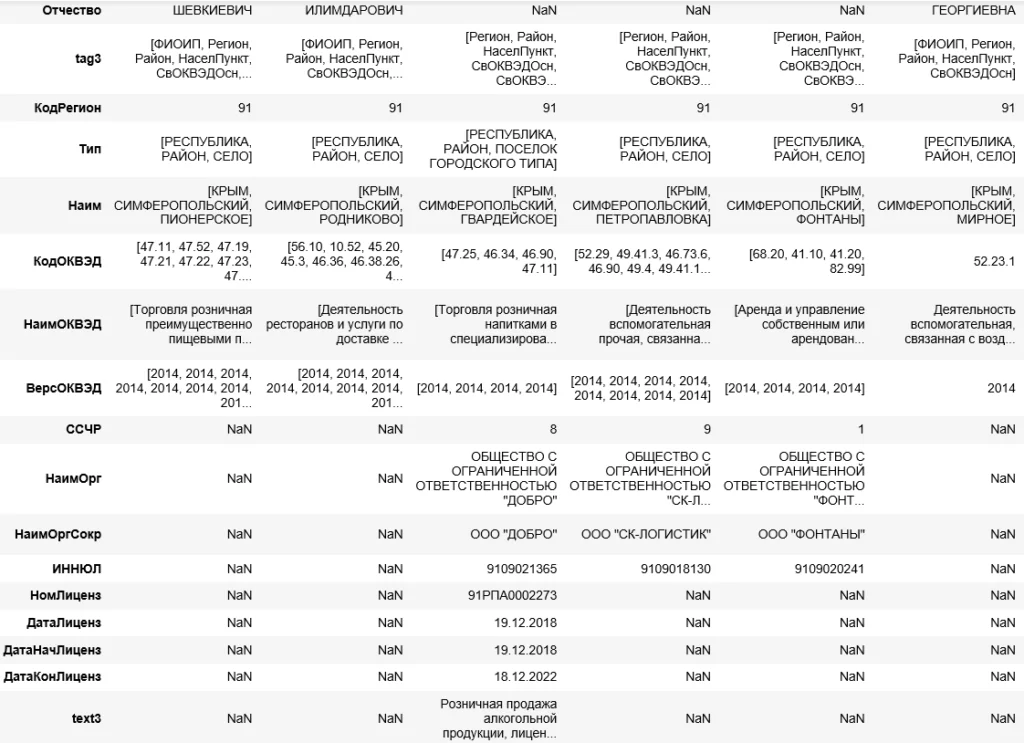
Видно, что решение для xes файлов оказалось настолько универсальным, что сработало и для другого формата документа. Таким образом можно получить табличное представление любого файла на языке XML – xml, xes, rss, xhtml, fb2. – примеры в jupyter notebook по ссылке ниже.