/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)
Время прочтения: 9 мин.
Тут нам на помощь и приходят графоориентированные БД. Существует достаточно большое количество реализаций баз данных на основе графов, но сегодня речь пойдет о набирающем популярность GRAKN.AI
GRAKN.AI является дедуктивной базой данных в виде графа знаний, которая использует машинное мышление для упрощения задач обработки данных для приложений ИИ. Это интуитивная и выразительная схема данных, с конструкциями для определения иерархий, гипер-сущностей, гипер-отношений и правил, для создания богатых моделей знаний.
Основным преимуществом GRAKN.AI перед конкурентами является указанная выше возможность машинного мышления, реализованного на уровне правил, благодаря чему БД способна выводить одни факты из других. Приведу пример:
Допустим Вам известны 2 факта: «поэт Пушкин А. С. родился в Москве» и «Москва – столица России». Зная это Вы можете вывести 3ий факт – «Пушкин — русский поэт». Для Вас этот вывод кажется простым и очевидным. Человеку в принципе свойственно обобщать вещи и строить причинно-следственные связи. К сожалению, для машины подобные рассуждения не всегда доступны в силу многих факторов. Однако именно способность обобщать и связывать фрагменты знаний в целостную картину — это то, без чего невозможно существование интеллекта, в том числе и искусственного. По этой же причине разработчики GRAKN.AI уделяют особое внимание наделению их продукта возможностью «мыслить логически».
Давайте посмотрим, как с помощью GRAKN.AI можно «выжать» из имеющихся данных чуть больше информации, чем имеем на первый взгляд.
Предположим, мы аудиторы в неком «Grakn-Банк» и наша задача выявить случаи, когда при устройстве на работу новые сотрудники умалчивают о том, что в банке уже работает их близкий родственник. Подобный факт может повлечь конфликт интересов.
Для того, чтобы подступиться к задаче сперва нужно подумать, как будет выглядеть наш граф:
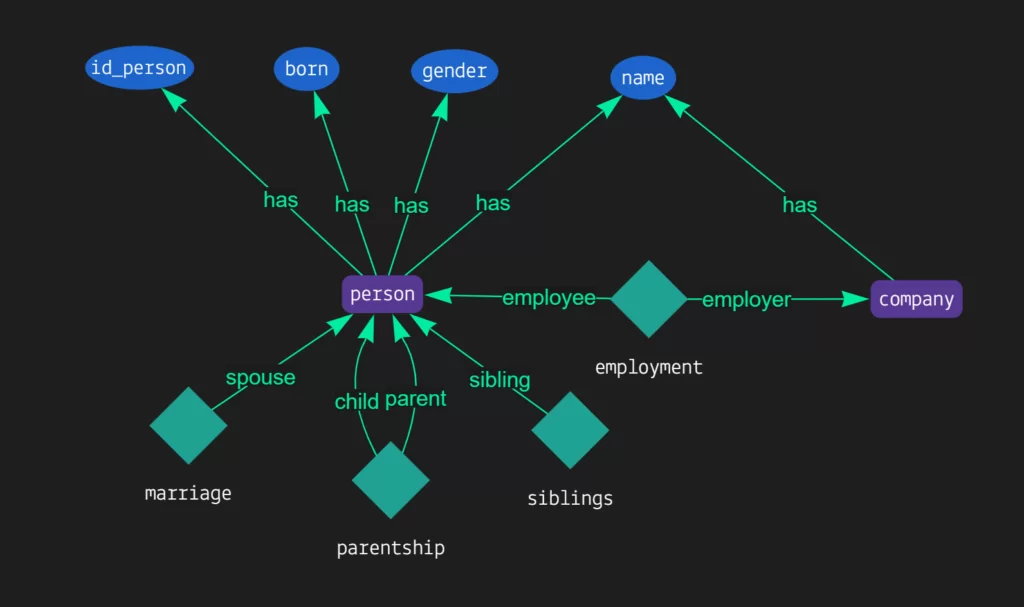
Мы не будем сильно усложнять структуру. Чтобы разобраться как все это работает достаточно объявить 4 свойства (атрибута), 2 сущности и 4 вида отношений:
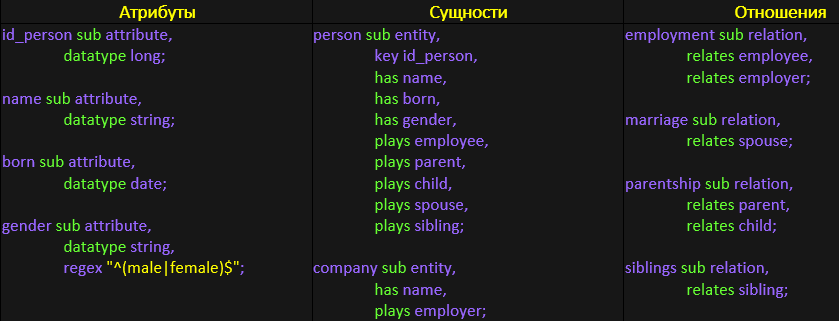
Attributes
На атрибутах подробно останавливаться смысла нет, всё и так предельно ясно. Мы просто указываем какой тип данных соответствует необходимому свойству. В случае с полем «gender» мы дополнительно говорим, что диапазон значений сводится к «male» и «female»
Entities
В нашей модели человек имеет 4 атрибута: id, ФИО, пол и дату рождения. Также о человеке можно сказать, что он может иметь роль работника (employee), быть родителем (parent) и ребенком (child), супругом (spouse), либо быть чьим-то братом/сестрой (sibling). С сущностью организаций проще. Об организации в данном случае достаточно знать, что у нее есть название и она может являться работодателем (employer).
Relations
Отношения можно условно разделить на 2 категории: трудовые отношения (employment) и близкие родственники (marriage, parentship, siblings). Кроме того, отношения могут иметь иерархию (employment, parentship) или же быть равноправными (marriage, siblings). Так, например, в трудовых отношениях одна сторона является работодателем, а другая работником, а в брачных отношениях обе стороны – супруги.
Конечно же, в реальной жизни сущности имеют гораздо больше атрибутов (например, у организации есть еще и ИНН), а отношения могут быть гораздо более многогранными (родительские отношения можно расширить до отношения мать-отец-сын-дочь, а не просто отношение между родителем и ребенком). Однако и текущего концепта хватит для иллюстрации основных принципов.
Со структурой определились, давайте теперь наполним наш граф. У нас есть 3 таблицы в реляционной БД:
- Persons – таблица с персональными данными. Сюда входят как данные о сотрудниках организации, так и данные о их родственниках (о которых сообщают сотрудники).
| id | name | sex | born | work_id |
| 1 | Иванов А. | male | 01.01.1980 | 1001 |
| 2 | Иванова Б. | female | 01.05.1982 | 1002 |
| 3 | Иванова В. | female | 05.05.2002 | |
| 4 | Петров А. | male | 06.09.1990 | 1001 |
| 5 | Петров Б. | male | 14.03.1963 | 1003 |
| 6 | Смирнова Н. | female | 25.07.1983 | 1001 |
| 7 | Орлов С. | male | 18.14.1988 | 1002 |
2. Organizations – таблица с данными об организациях
| id | name |
| 1001 | Grakn-Банк |
| 1002 | ОАО Ромашка |
| 1003 | ЗАО Комфорт |
3.Relations – таблица с родственными связями между людьми
| id | worker_id | relative_id | relative_kind |
| 100001 | 1 | 2 | spouse |
| 100002 | 1 | 3 | child |
| 100003 | 4 | 5 | parent |
| 100004 | 6 | 7 | sibling |
Для перехода от табличного представления к графориентированному нам нужно представить имеющиеся данные на понятном для GRAKN.AI языке – GraQL. Давайте разберемся с основными моментами этого языка. Для понимания структуры запросов рассмотрим следующий пример:

- каждое утверждение начинается с переменной (V), представляющей ссылку на сущность или отношение. Переменная начинается со знака доллара — $.
- за переменной следует разделенный запятыми список свойств (Р1, P2, P3). В данном примере свойство P3 мы передаём в переменную $phone;
- для определения типа понятия используется оператор «isa», для определения свойства используется оператор «has»
- завершение утверждения помечается точкой с запятой;
Существует некоторая свобода в формировании и составлении наших утверждений. Например, мы могли бы написать наш запрос так:
$p isa person;
$p has name 'Bob';
$p has phone-number $phone;Следуя этим принципам представим имеющиеся данные в следующем виде:
- Persons
| id | name | sex | born | work_id |
| 1 | Иванов А. | male | 01.01.1980 | 1001 |
$1 isa person, has name "Иванов А.", has gender "male", has born 1980-01-01, has id_person 1;Ссылка на место работы work_id в данном случае не является атрибутом человека, необходимо рассматривать ее часть отношения между person и organization
2.Organizations
| id | name |
| 1001 | Grakn-Банк |
$1001 isa company, has name "Grakn-Банк";После внесения персональных данных и данных по организациям можно перейти к перечислению отношений между этими данными:
| id | name | sex | born | work_id |
| 1 | Иванов А. | male | 01.01.1980 | 1001 |
(employee: $1, employer: $1001) isa employment;В итоге получаем следующий скрипт:
insert
$1 isa person, has name "Иванов А.", has gender "male", has born 1980-01-01, has id_person 1;
$2 isa person, has name "Иванова Б.", has gender "female", has born 1982-05-01, has id_person 2;
$3 isa person, has name "Иванова В.", has gender "female", has born 2002-05-05, has id_person 3;
$4 isa person, has name "Петров А.", has gender "male", has born 1990-09-06, has id_person 4;
$5 isa person, has name "Петров Б.", has gender "male", has born 1963-03-14, has id_person 5;
$6 isa person, has name "Смирнова Н.", has gender "female", has born 1983-07-25, has id_person 6;
$7 isa person, has name "Орлов С.", has gender "male", has born 1988-04-18, has id_person 7;
$1001 isa company, has name "Grakn-Банк";
$1002 isa company, has name "ОАО Ромашка";
$1003 isa company, has name "ЗАО Комфорт";
(employee: $1, employer: $1001) isa employment;
(employee: $2, employer: $1002) isa employment;
(employee: $4, employer: $1001) isa employment;
(employee: $5, employer: $1003) isa employment;
(employee: $6, employer: $1001) isa employment;
(employee: $7, employer: $1002) isa employment;
(spouse: $1, spouse: $2) isa marriage;
(parent: $1, child: $3) isa parentship;
(child: $4, parent: $5) isa parentship;
(sibling: $6, sibling: $7) isa siblings;
Эти же данные, но в графической форме:
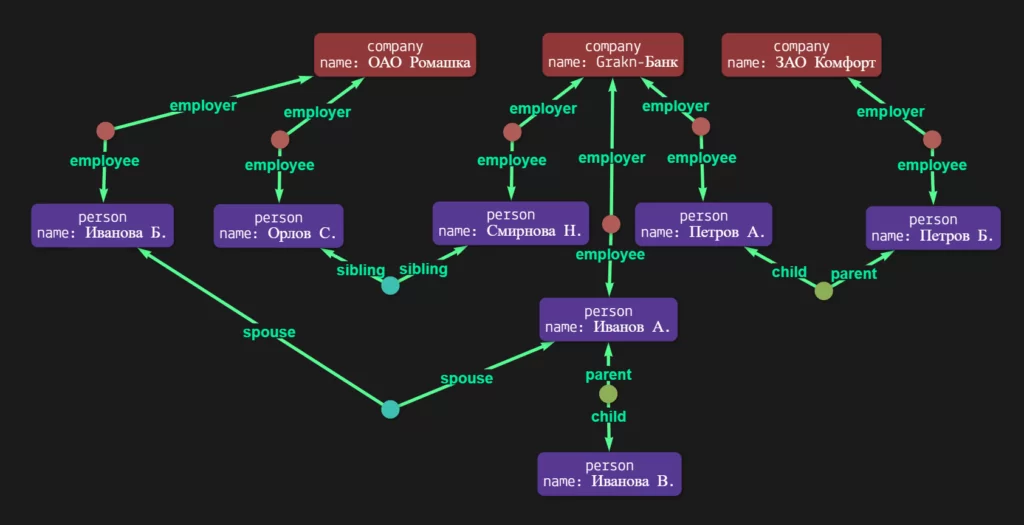
Пока в нашем «Grakn-Банк» все хорошо — у нас трудится 3 человека, Иванов А., Петров А. и Смирнова Н. У всех троих нет родственников, работающих в банке.
А теперь представим ситуацию: дочь одного из сотрудников, Иванова А. выросла, сменила фамилию (стала Сидорова В.) и решила устроиться на работу к отцу. Зная, что правилами банка это запрещено, она решила не сообщать о родственных связях с сотрудником банка, указав в анкете только мать Иванову Б.:
insert
$1 isa person, has name "Сидорова В.", has gender "female", has born 2002-05-05, has id_person 8;
match
$x isa person, has name "Иванова Б.", has gender "female", has born 1982-05-01, has id_person 2;
$y isa person, has name "Сидорова В.", has gender "female", has born 2002-05-05, has id_person 8;
insert
(child: $y, parent: $x) isa parentship;
Если мы обратимся к графу с запросом родственников Сидоровой В., работающих в банке, то как и следовало ожидать получим пустое множество:

И действительно, с точки зрения принимающего на работу персонала все хорошо: у Сидровой В. только одна родственная связь, эта связь с матерью, мать не работает в банке. Конфликта интересов не выявлено.
Но мы то с вами внимательные аудиторы и сразу заметили, что мать Сидоровой В. одновременно является женой Иванова А., а он работает в банке. Значит по косвенным признакам можно догадаться, что Сидорова В. и сотрудник банка Иванов А. являются близкими родственниками:
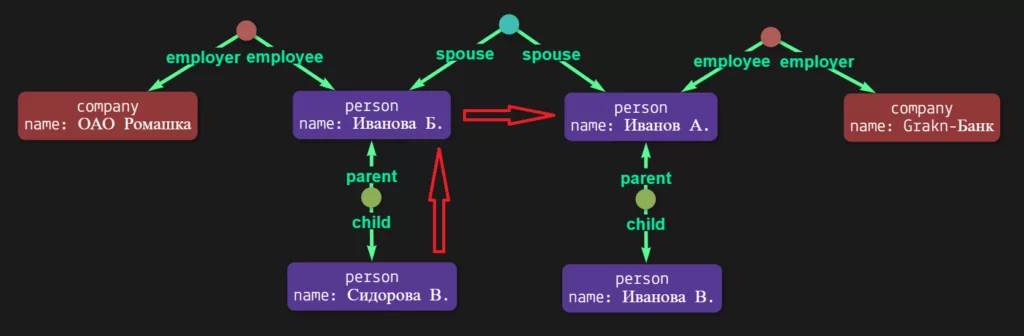
Для того, чтобы граф самостоятельно находил подобные, не указанные, родственные связи нужно научить наш граф «рассуждать логически». Необходимо задать простое правило:
parents-rule sub rule,
when {
($x, $y) isa marriage; #если X и Y - супруги
(parent: $x, child: $z) isa parentship; #и у X является родителем для Z
}, then {
(parent: $y, child: $z) isa parentship; #то и Y является родителем для Z
};
Давайте посмотрим, как изменился наш граф после применения к нему данного логического правила:
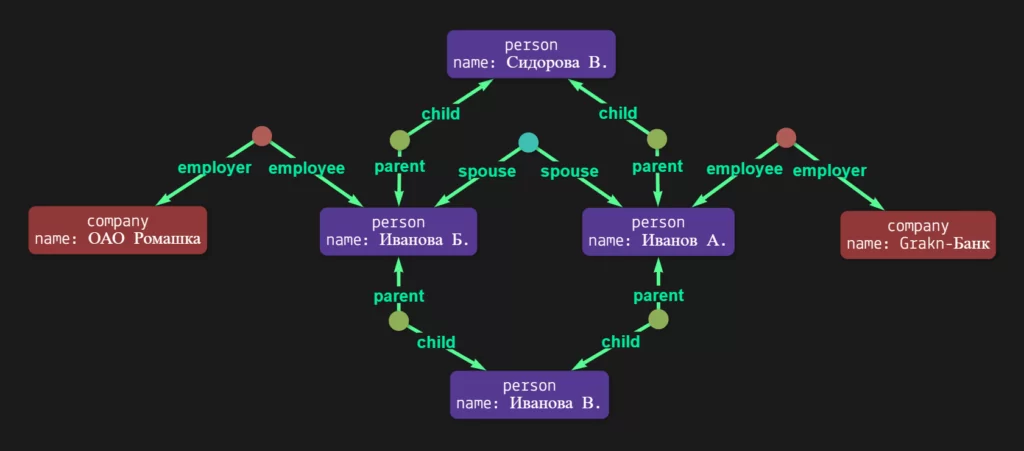
Отлично, теперь мы видим, что на основе объявленного правила граф связал Иванова А. и Сидорову В. родительскими отношениями, используя при этом брачные отношения между Ивановым А. и Ивановой Б. Давайте еще раз обратимся к графу с запросом родственников Сидоровой В., работающих в банке:

Ура, граф нашел родственные связи гражданки Сидоровой В. с сотрудником банка, а мы – нарушение и возможный конфликт интересов!
Получается фактически данных в графе осталось столько же, но количество полезной информации выросло. Таким образом, чем больше у Вас данных и чем больше правил, которые устанавливают отношения между этими данными, тем больше можно получить инсайтов.
Рассмотренный пример, безусловно, можно решить и на SQL, но чем больше условий вам нужно будет учесть, тем сложнее будет ваш скрипт, и тем выше будет вероятность неправильно связать данные. Я уже не говорю о том, как будет сложно обычному человеку, без глубоких знаний в SQL, понять получившийся талмуд.
Кроме того, в SQL Вы вынуждены в каждой реализации скрипта прописывать все необходимые связи, а в grakn-графе достаточно один раз задать правило отношений между данными и это избавит Вас от рутины в будущем.
Граф без проблем может включать в себя информацию из различных доменов, а язык запросов легко интерпретируем и понятен человеку. При этом граф учитывает не только связи между сущностями, но и направление этих связей. Более того, с помощью GRAKN.AI и машинного обучения можно выявлять вероятные связи там, где они явно не определены, но об этом в другой раз.