/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
Kibana – важная составная часть стека ELK (Elasticsearсh, Logstash, Kibana), с помощью которой удобно работать с индексами Elasticsearсh для пользователей (поиск, визуализация, создание дашбордов и т.д.), а для администраторов – управление индексами и администрирование стеком ELK.
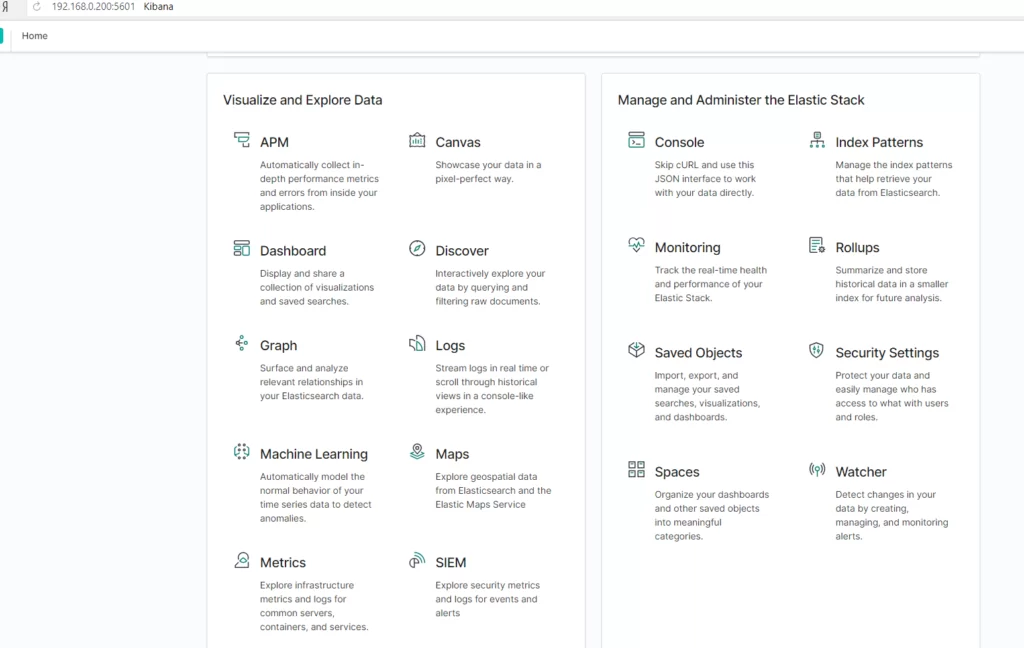
Не всем пользователям удобно пользоваться не локализованной (в нашем случае не русифицированной) версией. Для локализации Kibana на официальном сайте предлагается установить версию для разработчика из GitHub, провести ряд достаточно не тривиальных действий по получению файла локализации английского языка, связанных с правильными установками React and AngularJS frameworks, для конкретной версий стека ELK и дальнейшего перевода файла локализации английского языка на русский язык (все это подробно описано на форуме).
Для упрощения всей этой процедуры мы будем использовать версию ELK из «коробки», доступной любому пользователю на официальном сайте, и внимание … китайскую локализацию Kibana.
Как установить Kibana можно прочитать на https://www.elastic.co/downloads/kibana, а также на многих русскоязычных сайтах.
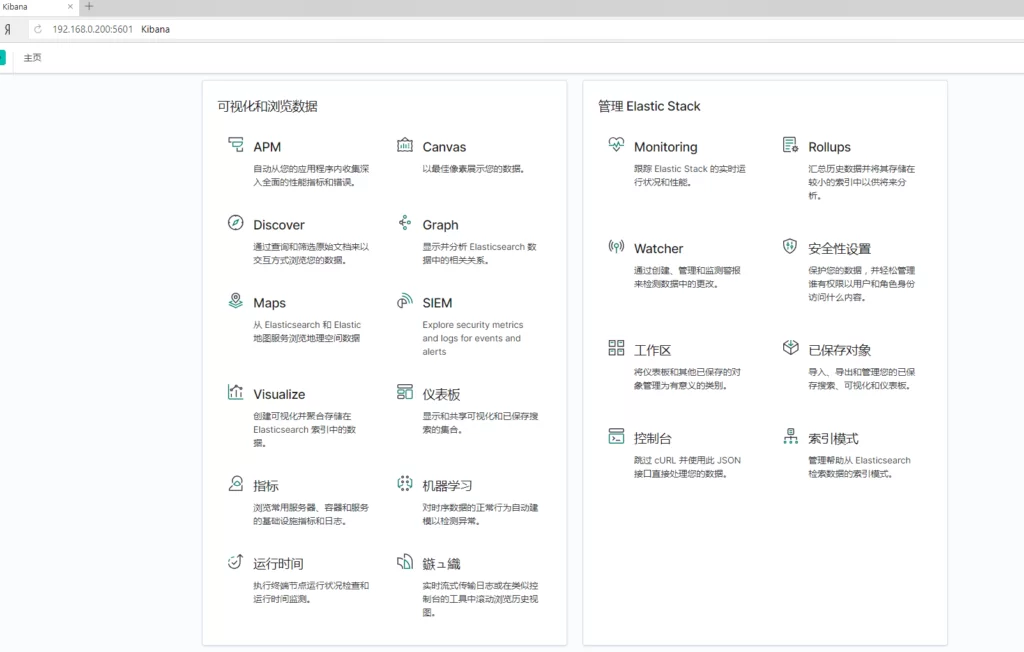
Установим и проверим как работает китайская локализация Kibana. Для этого создадим папку “translations” в “/usr/share/kibana”. Скопируем файл “zh-CN.json” из “/usr/share/kibana/x-pack/plugins/translations/translations” в папку “/usr/share/ kibana/translations” и отредактируем 2 файла:
vi /etc/kibana/kibana.ymlВ последней строчке укажем:
i18n.locale: "zh-CN"Второй файл:
vi /usr/share/kibana/.i18nrc.jsonДобавить или отредактировать строку:
"translations": [
"translations/zh-CN.json"
]Перезагрузим Kibana – восхитимся великим китайским языком:
И теперь осталось самое простое: сделаем перевод.
Для этого воспользуемся безотказным Python и следующими библиотеками:
import json # для работы с файлами
import time # делать таймауты
import re # работать со строками
from googletrans import Translator # Google translator - спасибо Google за помощь в переводе
1.Нужно загрузить файл исходник:
with open('/your_path/zh-CN.json', 'r', encoding='utf-8') as fh: # /your_path/ - ваша папка с файлом
# китайской локализации
data = json.load(fh) #загружаем из файла китайской локализации данные в словарь data2.Так как внутри слов имеются переменные, ограниченные фигурными скобками, и написанные на английском языке, то необходимо их оградить от перевода (т.к. гугл переводит не только с китайского, но и с английского тоже). Для чего напишем следующий код:
ch = data["messages"] # словарь "messages" с китайскими словами
n_val = 10**9 # индексы для замены переменных
message_n = {} # словарь "messages" со списком переменных и их заменой на индексы
message_ch = {} # словарь "messages" с индексами вместо переменных, китайский
message_ru = {} # словарь "messages" с индексами вместо переменных, русский
ru = {} # словарь "messages" с русскими словами
data_ru = {} #
for key in ch:
n = ch[key].count("{") # подсчет фигурных скобок - переменные заключены в {}
variable_end = 0 # задаем начало поиска переменной
ch_int = [] # список для переменных в строке
stroka = ch[key] # присвоение значения ключа
if n > 0: # проверка на наличие переменных
for i in range(n):
variable_start = ch[key].find("{", variable_end)
variable_end = ch[key].find("}", variable_end) # значение окончания переменной
if variable_start > variable_end:
variable_start = variable_end
variable_end = ch[key].find("}", variable_start + 1)
variable_end2 = ch[key].find("{", variable_start + 1)
if variable_end > variable_end2:
variable_end = variable_end2
if variable_end == -1: variable_end = len(ch[key])
variable = ch[key][variable_start:variable_end + 1] # значение переменной
result = re.findall(r'[A-z]', variable) # поиск в переменной латиницы
if len(result) > 0 : # наличие в переменной латиницы
ch_int.append(["{"+ str(n_val) + "}", variable]) # добавление в список индекса и переменной
stroka = stroka.replace(variable, "{"+ str(n_val) + "}") # замена переменной на значение индекса
message_n[key] = ch_int # формирование словаря "messages" со списком переменных и их заменой на индексы
n_val += 1 # инкремент индекса
variable_end += 1 # изменение начала поиска переменной
message_ch[key] = stroka # формирование словаря "messages" с индексами вместо переменных, китайский3. А код для перевода будет выглядеть следующим образом:
translator = Translator()
for key, value in message_ch.items(): # просмотр словаря "messages" с индексами вместо переменных, китайский
if value != " ": # проверка пустого значения (пустое не переводится!!!)
result = translator.translate(value, src='zh-CN', dest='ru') # результат перевода
time.sleep(1) # таймаут для успеха перевода
message_ru[key] = result.text # формирование словаря "messages" с индексами вместо переменных, русский
else:
message_ru[key] = message_ch[key]4.Еще немного технического кода:
………………………………………………………
# весь код можно посмотреть на https://github.com/IldarVS/local_kibana)5.И в конце выгрузка русифицированного файла локализации:
data_ru = data # присвоение данных файла китайской локализации
data_ru["messages"] = ru # изменение словаря "messages" с русскими словами
# формирование файла русской локализации
with open(/your path/ru-RU.json', 'w', encoding='utf-8') as file:
json.dump(data_ru, file, indent=4, ensure_ascii=False) # сохраняем данные в файл русской локализации6.Скопируем полученный файл “ru-RUjson” в папку “/usr/share/ kibana/translations”, и снова редактируем файлы:
vi /etc/kibana/kibana.yml7.Закомментируем китайский и добавим в последней строчке русский:
#i18n.locale: "zh-CN"
i18n.locale: "ru-RU"Второй файл:
vi /usr/share/kibana/.i18nrc.jsonДобавить строку: «translations/ru-RU.json»,
"translations": [
"translations/ru-RU.json",
"translations/zh-CN.json"
]Перезагрузим Kibana – вот он наш родной русский язык:
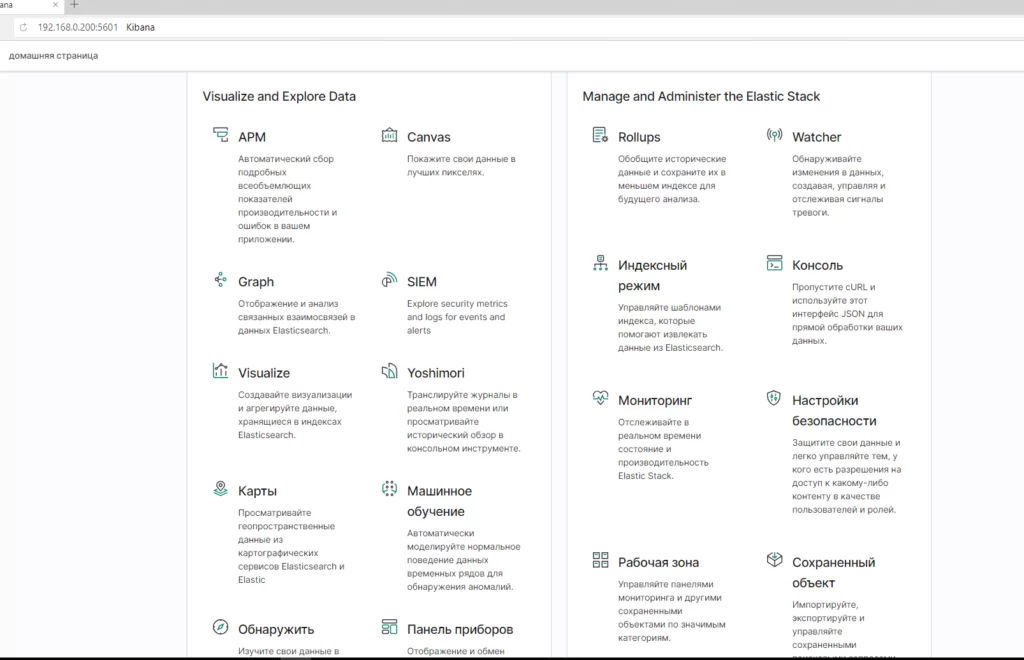
Как видим: с китайского оказалось легче русифицировать Kibana. Весь код лежит на https://github.com/IldarVS/local_kibana