/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
На какие вопросы поможет ответить тематическое моделирование?
• Быстро понять, какие темы поднимаются в тексте.
• Выделить наиболее обсуждаемые топики в комментариях.
• Лучше узнать свою аудиторию для таргетирования.
• Находить сообщества, которые интересуются нужными темами.
В моей задаче необходимо было разобрать темы обсуждений в сообществах социальной сети Вконтакте. При решении такой объемной задачи очень важно правильно разбить ее на несколько маленьких пунктов. Для себя я выделила такие: поиск сообществ Вконтакте, написание парсеров для сбора комментариев, предобработка извлеченных данных, моделирование, интерпретация результатов, построение тематических профилей.
Первая проблема, с которой я столкнулась при использовании VK API для сбора комментариев, состояла в том, что метод wall.getComments, который позволяет нам извлечь комментарии к записям со стены сообщества, может вернуть только 100 записей. Используя этот код, вы можете собрать их все.
def vk(method, **params):
url = 'https://api.vk.com/method/%s' % method
data = {
'wall.getComments' : {'owner_id': owner_id,
'post_id': post_id,
'count' : 100},
}.get(method,{})
data.update(params)
data.update({'access_token':access_token,"v": V,})
resp = requests.post(url,data=data)
answer = resp.json()
if 'error' in answer:
print('error:',answer )
return []
return answer ['response']
if __name__ == "__main__":
all_post=pd.DataFrame()
for i in range(n):
offset=i*100
post=pd.DataFrame(vk('wall.get', owner_id= owner_id,
count = 100,offset=offset))
all_post=pd.concat([all_post,post],ignore_index=True)
time.sleep(2)
Второй этап, представляющий из себя предобработку данных, заключается в извлечении из полученных словарей необходимых признаков комментария и самого текста. Для этого пишем функции на основе регулярных выражений.
Например, таким образом мы извлекаем текст комментария.
import re
finded=[]
finded=[]
def text_comment(data):
try:
finded=re.search("'text': .*'",str(data)).group()[8:]
except:
finded=0
return finded
all_comments['text_comment']=all_comments['items'].apply(text_comment)
Затем, для обработки моделью, тексты стоит очистить от пунктуации, пробелов и цифр, пишем еще одну функцию.
def drop_punctuation(text): #пробелы
text = re.sub('\s+', ' ', text)
#все кроме слов
reg = re.compile('[^a-zA-Zа-яА-Я ]')
text=reg.sub('', text)
return text
data['text'] = (data['Заголовок'].astype(str)+' '+data['Комментарий'].astype(str)).apply(lambda x:drop_punctuation(str(x)))
Чтобы установить структурированные семантические отношения между словами, необходимо все слова комментариев преобразовать в их базовую форму. Я воспользовалась морфологическим анализатором для русскоязычных текстов pymystem3.
from pymystem3 import Mystem
m = Mystem()
# применяем лемматизацию
data['text_bow'] = data_['text'].apply(lambda x: m.lemmatize(x))
Далее необходимо избавиться от шумовых слов, удалить общие стоп-слова мы можем используя список слов, собранных на GitHub. Но что же делать с зависимыми или контекстными шумами? Для этого, основываясь на своем мнении я составила еще один список слов, который позже присоединила к существующему.
file_sw = open('stopwords_ru.txt', encoding='utf-8')
stop_words = [line.strip() for line in file_sw]
stop_words.extend([‘Здесь будут ваши слова’])
def doc_to_words_ru(doc, stop_words):
stop_words = set(stop_words)
words = [w for w in gensim.utils.simple_preprocess(str(doc), deacc=True, max_len=100) if w not in stop_words]
return words
data['text_clean'] = [doc_to_words_ru(t, stop_words) for t in data['text_bow']]
В тексте могут встречаться специфические сочетания для сообщества или темы комментария пользователей, для тематического моделирования очень важно не упустить подобные тонкости, поэтому сгенерируем биграммы. После того как у нас есть популярные сочетания составляем конечный словарь терминов, отсекая при этом слишком редкие и частые.
from gensim import corpora, models
combination_of_words = models.Phrases(data.text_clean, min_count=3, threshold=5)
combination_of_words_mod = models.phrases.Phraser(combination_of_words)
def make_combination_of_words(texts):
return [combination_of_words_mod[doc] for doc in texts]
list_of_texts = make_combination_of_words(data.text_clean)
dictionary_texts = corpora.Dictionary(list_of_texts)
dictionary_texts.filter_extremes(no_below=3, no_above=0.8)
word_corpus = [dictionary_texts.doc2bow(text) for text in list_of_texts]
Когда предобработка данных закончена, нам предстоит заняться моделированием тематических профилей сообщества и визуализация результатов.
lda_model = models.ldamodel.LdaModel(corpus= word_corpus, id2word= dictionary_texts, num_topics=6, passes=5 )Параметр num_topics необходимо установить перебором, на основе значения когерентности модели используя обратный метод локтя.
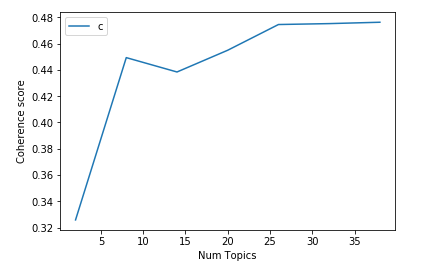
Визуализируем результат:
import pyLDAvis.gensim
pyLDAvis.gensim.prepare(lda_model, word_corpus, dictionary_texts)
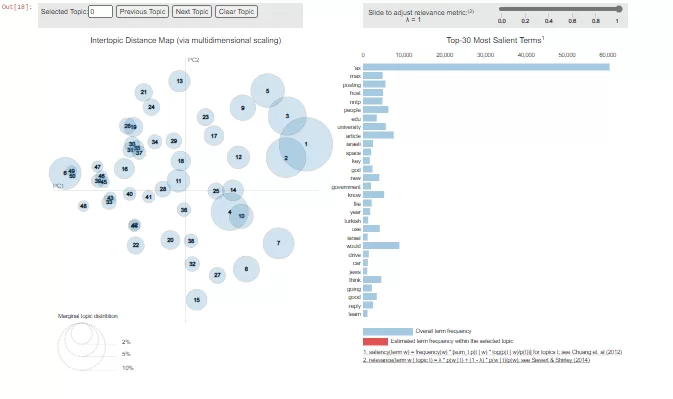
У нас получилась интерактивная картинка, которая отображает многомерные топики в двумерном пространстве. С помощью подобной визуализации мы можем просмотреть каждый топик, а так же увидеть вклад каждого слова. Для получения тематик комментариев, на основе полученных характеризующих наборов слов, необходимо самостоятельно проинтерпретировать результаты и заименовать их, удобным для нас образом так, чтобы они ответили на поставленные в начале исследования вопросы.