/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
Предположим, у нас есть таблица с данными продаж нескольких видов продуктов (Product 1, 2, 3, 4) у разных операторов (A, B, C, D):
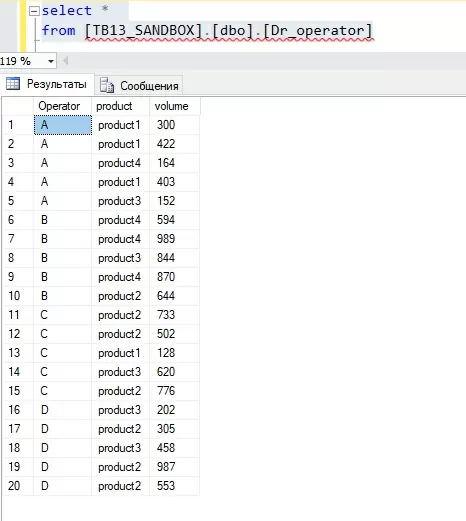
Из вышеуказанной таблицы мы хотим получить сводную таблицу вида:

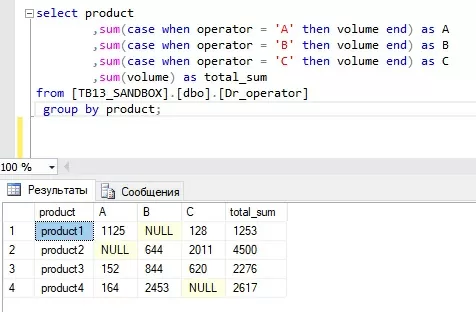
Вариант 1: Использование оператора CASE.
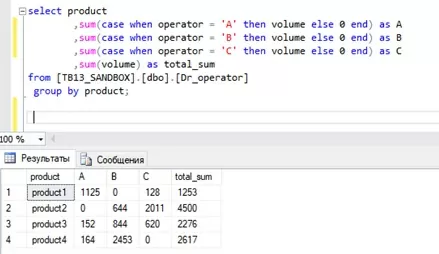
Для замены значения Null на обычный «0» достаточно добавить в конструкцию CASE WHEN оператор ELSE:
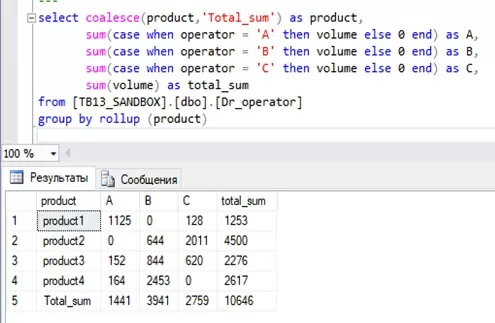
Не хватает итогов под таблицей. Для этого мы будем использовать оператор GROUP BY ROLLUP:
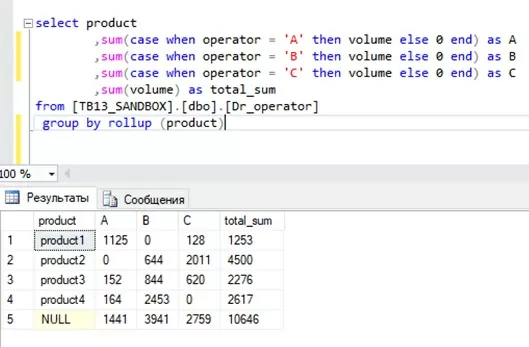
А для того, чтобы под колонкой «product» вместо значения «NULL» вывести всем понятное «Total_sum» нам понадобится оператор COALESCE.
Вариант 2: Использование оператора GROUP BY CUBE
Для быстрой группировки данных по операторам и вывода итоговых значений по каждому продукту без перечисления в коде всех операторов удобно использовать оператор GROUP BY CUBE:
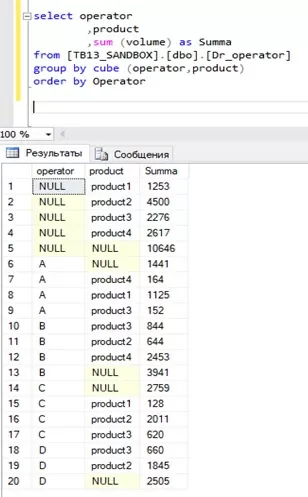
Для отображения вместо NULL в колонке operator названия «Total_sum» воспользуемся оператором COALESCE
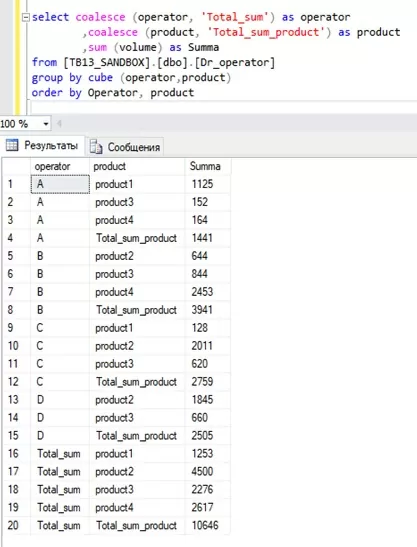
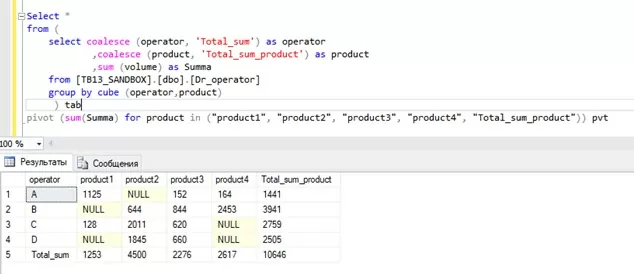
Перед использованием этого оператора нам необходимо получить агрегированную таблицу. Для этого мы будем использовать ранее подготовленную с использованием оператора GROUP BY CUBE таблицу, используя предыдущий фрагмент кода как подзапрос (выделено цветом).
Здесь мы «поворачиваем» таблицу из прошлого запроса, используя агрегатную функцию суммы sum (Summa). При этом заголовки столбцов мы берём из поля operator, а с помощью in («A», «B», «C», “D”, «total_sum») указываем какие конкретно операторы должны быть выведены (total_sum отвечает за столбец с итогами по строкам). При этом заголовки столбцов обязательно берем в двойные кавычки.
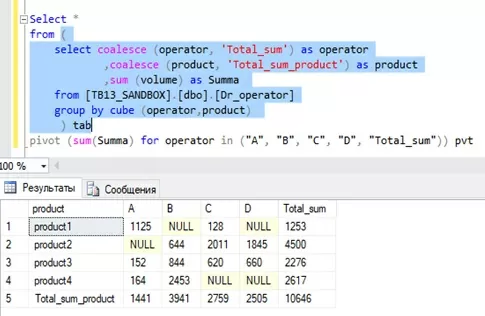
Для разворота таблицы в разрезе продуктов по каждому оператору меняем аргумент в операторе PIVOT.
Запрос с PIVOT выглядит короче, чем изначальный с CASE, но названия поставщиков все ещё необходимо вносить вручную. Но что делать, если поставщиков много? Или если их список регулярно обновляется? Хотелось бы выбирать их автоматически. Здесь чистого SQL недостаточно. Он подразумевает статическую типизацию: для создания плана запроса СУБД нужно заранее указать число столбцов. Поэтому синтаксис PIVOT не позволяет использовать подзапрос. Но это ограничение легко обойти с помощью динамического SQL. Для этого названия столбцов необходимо преобразовать в строку формата «элемент_1», «элемент_2», …, «элемент_n», и использовать их в запросе.
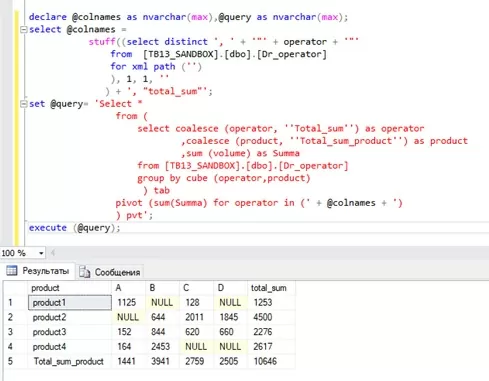
Для генерации строки, мы можем использовать оператор STUFF:
declare @colnames as nvarchar(max);
select @colnames =
stuff((select distinct ', ' + '"' + operator + '"'
from [TB13_SANDBOX].[dbo].[Dr_operator]
for xml path ('')
), 1, 1, ''
) + ', "total_sum"';
Полученную строку включаем в окончательный запрос:
Еще больше статей на тему автоматизации и анализа данных в SQL ищите по ссылке