/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 6 мин.
PANDAS — это библиотека на языке Python, созданная для анализа и обработки данных. Имеет открытый исходный код и поддерживается разработчиками Anaconda. Эта библиотека хорошо подходит для структурированных (табличных) данных.
Для начала импортируем библиотеки, которые пригодятся нам по ходу работы:
import pandas as pd
import numpy as npИ для наглядности возьмём csv таблицу:

Далее мы записываем информацию из csv в DataFrame, который назовем test_csv, и убедимся, что полученная таблица будет иметь тоже имя и структуру, как и оригинальный csv:
Ввод: test_csv = pd.read_csv('test.csv')
test_csv.head()
Вывод:
ID FIO ID_STATUS OPEN CLOSE PRICE SALE
0 45 Горбунов В.Ф. В работе 02/05/2020 NaN 1500 0.8
1 49 Нестерова В.В. В работе 02/05/2020 NaN 2300 0.9
2 52 Горбунов В.Ф. Выполнено 02/05/2020 04/05/2020 3500 1
3 54 Нестерова В.В. В работе 03/05/2020 NaN 750 0.6
4 55 Мамонтов Б.А. Выполнено 03/05/2020 06/05/2020 1230 0.95SELECT
В SQL выборка необходимых нам столбцов происходит перечислением имен этих столбцов через запятую или с помощью * для выбора всех столбцов:
SELECT ID, ID_STATUS, CLOSE
FROM test_csv
LIMIT 5;В Pandas выбор столбцов происходит с помощью перечисления необходимых названий столбцов в списке в нашем DataFrame:
Ввод: test_csv[['ID', 'ID_STATUS', 'CLOSE']].head(5)
Вывод:
ID ID_STATUS CLOSE
0 45 В работе NaN
1 49 В работе NaN
2 52 Выполнено 04/05/2020
3 54 В работе NaN
4 55 Выполнено 06/05/2020 А если же мы вызываем DataFrame без листа с названиями столбцов, то это отобразить все столбцы словно * в SQL.
В SQL мы сразу можем добавить столбец с нужными нам расчетами:
SELECT *, PRICE*SALE as SUM
FROM test_csv
LIMIT 5;В Pandas для добавления столбца с расчетами мы воспользуемся DataFrame.assign():
Ввод: test_csv.assign(SUM=test_csv['PRICE'] / test_csv['SALE']).head(5)
Вывод:
ID FIO ID_STATUS OPEN CLOSE PRICE SALE SUM
0 45 Горбунов В.Ф. В работе 02/05/2020 NaN 1500 0.8 1200
1 49 Нестерова В.В. В работе 02/05/2020 NaN 2300 0.9 2070
2 52 Горбунов В.Ф. Выполнено 02/05/2020 04/05/2020 3500 1 3500
3 54 Нестерова В.В. В работе 03/05/2020 NaN 750 0.6 450
4 55 Мамонтов Б.А. Выполнено 03/05/2020 06/05/2020 1230 0.95 1168.5WHERE
Фильтрация в SQL происходит при помощи WHERE:
SELECT *
FROM test_csv
WHERE ID_STATUS = 'Выполнено'
LIMIT 3;DataFrame же может быть отфильтрован несколькими способами, но самыми частым из них является логическое сравнение:
Ввод: test_csv[test_csv['ID_STATUS'] == 'Выполнено'].head(3)
Вывод:
ID FIO ID_STATUS OPEN CLOSE PRICE SALE
1 52 Горбунов В.Ф. Выполнено 02/05/2020 04/05/2020 3500 1
2 55 Мамонтов Б.А. Выполнено 03/05/2020 06/05/2020 1230 0.95
3 56 Горбунов В.Ф. Выполнено 03/05/2020 07/05/2020 767 0.35Также, как и в SQL, в DataFrame мы можем использовать операторы И/ИЛИ:
SELECT *
FROM test_csv
WHERE ID_STATUS = 'Выполнено' AND PRICE > 1000;
Ввод: test_csv[(test_csv['ID_STATUS'] == 'Выполнено') & (test_csv['PRICE'] > 1000)]
Вывод:
ID FIO ID_STATUS OPEN CLOSE PRICE SALE
0 52 Горбунов В.Ф. Выполнено 02/05/2020 04/05/2020 3500 1
1 55 Мамонтов Б.А. Выполнено 03/05/2020 06/05/2020 1230 0.95Для проверки наличия в значении NULL, мы используем notna() и isna(). Для примера создадим DataFrame с NULL значениями.
Ввод: test_1 = pd.DataFrame({'C1': ['1', '1', np.NaN, '1', '1'],
'C2': ['2', np.NaN, '2', '2', np.NaN],
'C3': [np.NaN, '3', '3', '3', np.NaN]})
test_1
Вывод:
C1 C2 С3
0 1 2 NaN
1 1 NaN 3
2 NaN 2 3
3 1 2 3
4 1 NaN NaNИ теперь для примера выберем все строки, где С2 IS NULL:
SELECT *
FROM test_1
WHERE C2 IS NULL;
Ввод: test_1[test_1['C2'].isna()]
Вывод:
C1 C2 С3
0 1 NaN 3
1 1 NaN NaNДля получения IS NOT NULL значений по столбцу С3 воспользуемся notna():
SELECT *
FROM test_1
WHERE C3 IS NOT NULL;
Ввод: test_1[test_1['C3'].notna()]
Вывод:
C1 C2 С3
0 1 NaN 3
1 NaN 2 3
2 1 2 3UNION
UNION ALL в PANDAS осуществляется с помощью concat():
Ввод: set_1 = pd.DataFrame({'name': ['Банан', 'Арбуз', 'Яблоко'],
'price': [90, 30, 150]})
set_2 = pd.DataFrame({'name': ['Арбуз', 'Ананас', 'Груша'],
''price': [30, 190, 80]})
SELECT name, price
FROM set_1
UNION ALL
SELECT name, price
FROM set_2;
/*
name price
Банан 90
Арбуз 30
Яблоко 150
Арбуз 30
Ананас 190
Груша 80
*/
Ввод: pd.concat([set_1, set_2])
Вывод:
name price
0 Банан 90
1 Арбуз 30
2 Яблоко 150
3 Арбуз 30
4 Ананас 190
5 Груша 80UNION из SQL похожа по функционалу на UNION ALL с отличием только в том, что UNION удаляет дубликаты строк.
SELECT name, price
FROM set_1
UNION
SELECT name, price
FROM set_2;
/*
name price
Банан 90
Арбуз 30
Яблоко 150
Ананас 190
Груша 80
*/В PANDAS мы можем использовать concat() в сочетании с drop_duplicates():
Ввод: pd.concat([set_1, set_2]).drop_duplicates()
Вывод:
name price
0 Банан 90
1 Арбуз 30
2 Яблоко 150
3 Ананас 190
4 Груша 80UPDATE
С помощью UPDATE мы можем “обновить” значения:
SQL:
UPDATE test_csv
SET SALE = SALE*0.9
WHERE SALE > 0.5;
PYTHON:
test_csv.loc[test_csv['SALE'] > 0.5, 'SALE'] *= 0.9DELETE
В SQL удаление с условием выглядит так:
DELETE FROM test_csv
WHERE SALE > 0.75;В PANDAS же мы выбираем какие столбцы остаются, а не удаляются как это сделано в SQL:
Ввод: test_csv = test_csv.loc[test_csv['SALE'] <= 0.75]ЗАДАЧИ
Так как мы рассмотрели основные функции SQL и PANDAS на примерах, то попробуем решить пару задачек, с которыми мы можем столкнуться в повседневной работе.
Пусть у нас имеется csv таблица work:
- ID – ID работника
- FIO – ФИО работника
- DEPT – Отдел
- CHIED_ID – Непосредственный руководитель
- SALARY – Заработная плата
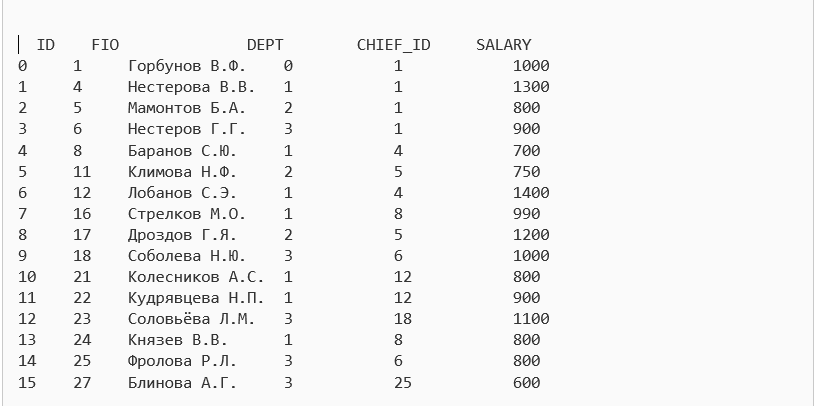
Например, нам нужно вывести всех сотрудников, которые получают максимальную заработную плату в каждом из отделов.
В SQL это будет выглядит так:
SELECT a.*
FROM work a
WHERE a.SALARY = ( SELECT MAX(SALARY)
FROM work b
WHERE b.DEPT = a.DEPT )Для python одним из вариантов будет:
import pandas as pd
import numpy as np
work_csv = pd.read_csv('work.csv', header=0)
unique_dept = pd.unique(df['DEPT']).tolist()
for ud in unique_dept:
ud_df = work_csv[(work_csv['DEPT'] == ud)]
max_salary.append(ud_df.iloc[ud_df['SALARY'.idxmax()])
print(max_salary)Для данной задачи мы получим вот такой ответ:

В следующей задаче нам нужно вывести список ID отделов, где количество сотрудников не превышает трех человек.
В SQL это будет выглядит так:
SELECT DEPT
FROM work
GROUP BY DEPT
HAVING COUNT(*) <= 3Для python одним из вариантов будет:
import pandas as pd
import numpy as np
work_csv = pd.read_csv('work.csv', header=0)
unique_dept = pd.unique(df['DEPT']).tolist()
for ud in unique_dept:
if len(work_csv[(work_csv['DEPT'] == ud)] <= 3:
print(ud)И для данной задачи мы получим ответ: 0 и 2, т.к. только они и удовлетворяют условиям нашей задачи.
Мы рассмотрели основные функции SQL в рамках PANDAS на примерах, закрепили полученные знания на практике и теперь с уверенностью можем покорять новые горизонты!