/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)
Время прочтения: 3 мин.
Нейронные сети показали себя отличным инструментом для решения самых разнообразных задач, но, к сожалению, их использование требует значительных вычислительных мощностей, которых до сих пор может не быть у малого бизнеса. Существует множество видов сжатия нейросетей, которые можно разбить на аппаратные, низкоуровневые, математические, но в данной статье будет обсуждаться метод, разработанный в MIT в 2019 году и работающий непосредственно с самой нейросетью.
Данный метод называется “Гипотеза о выигрышных билетах”. В общем виде она звучит так: Всякая полносвязная нейронная сеть со случайно инициализированными весами содержит подсеть, с такими же весами, и такая подсеть, обученная отдельно, может сравняться по точности с исходной сетью.
Формальное доказательство и полную статью можно посмотреть здесь. Нас же интересует возможность практического применения. Вкратце, алгоритм следующий:
- Создаем модель, случайно инициализируем ее параметры
- Обучаем сеть j итераций
- Обрезаем те параметры сети, которые имеют наименьшее значение (самым простым будет задание какого-нибудь порогового значения)
- Сбрасываем оставшиеся параметры до их начальных значений, получаем нужную нам подсеть.
По идее, данный алгоритм нужно повторить n-ое количество шагов, но для примера проведем только одну итерацию. Создадим простую полносвязную сеть с использование tensorflow и Keras:
import tensorflow as tf
from tensorflow import keras
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(300, activation='relu'),
keras.layers.Dense(150, activation='relu'),
keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='SGD',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])Получим следующую архитектуру сети:
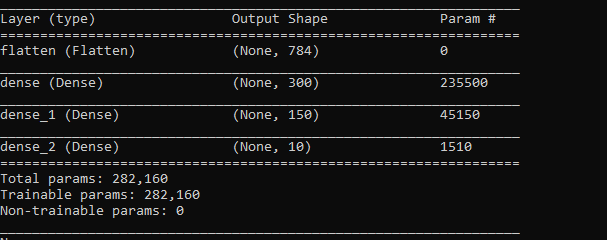
И обучим ее на датесете MNIST-fashion из 60000 изображений. Ее точность на проверочных данных будет равна 0.8594. Применим к параметрам сети 1 итерацию данного алгоритма. В коде это выглядит следующим образом:
# задаем порог
threshold = 0.001
# загружаем веса модели и сохраняем как np.array
weights = model.weights
weights = np.asarray(weights)
# выводим веса скрытых слоев
first_h_layer_weights = weights[1]
second_h_layer_weights = weights[3]
def delete_from_layers(one_d_array, threshold):
index = []
for i in range(one_d_array.shape[0]):
# находим индексы элементов, имеющих значени по модулю ниже чем порог
if abs(one_d_array[i]) <= threshold:
index.append(i)
# удаляем все такие элементы, получаем новые веса
new_layer = np.delete(one_d_array, index)
return new_layer
new_layer_weights = delete_from_layers(second_h_layer_weights, threshold)Таким образом, после выполнения данного кода, мы избавимся от практически неиспользуемых весов. Стоит отметить две вещи, в данном примере порог выбирался эмпирически и данный алгоритм нельзя применять к весам входного и выходного слоя.
Получив новые веса, необходимо переопределить изначальную модель, убрав лишнее. В результате получим:
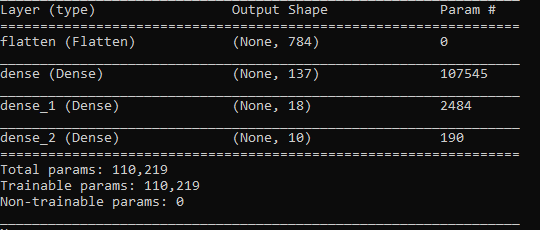
Можно заметить, что общее количество параметров уменьшилось почти в 2 раза, что значит, что при обучении первой сети больше половины параметров были попросту ненужными. При этом точность подсети составляет 0.8554, что совсем немного ниже основной сети. Конечно, данный пример является показательным, обычно сеть можно сократить на 10-20% от изначального числа параметров. Здесь же и без применения данного алгоритма понятно, что изначальная архитектура была выбрана слишком громоздкой.
В заключении можно сказать, что данная техника не является хорошо отработанной на данный момент, и в реальных задачах попытка оптимизировать веса модели таким образом может только удлинить процесс обучения, но сам по себе алгоритм имеет достаточно большой потенциал.