/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
Пожалуй, самым популярным способом выявления мошеннических операций из перечня подозрительных это сортировка по количеству операций, приходящихся на одного сотрудника. Данный способ выявления концентрации обладает очень большим недостатком – он не учитывает вероятность проведения операций у сотрудника. Например, если мы анализируем операции по счетам клиентов-нерезидентов, то в филиалах, которые расположены в пограничной территории, таких операций будет априори больше и наши реальные мошеннические операции могут попросту «утонуть» в море легитимных.
И здесь нам может помочь распределение Пуассона. Не вдаваясь в лишние и сложные подробности, можно сказать, что количество клиентов, обслуженных в банке в течение одного часа, описывается распределением Пуассона. Чтобы глубже понять смысл пуассоновского процесса разберем нашу задачу – выявление нестандартных операций выдачи банковских карт клиентам-нерезидентам. В данном случае мы исследуем количество клиентов-нерезидентов, которые обслуживались у конкретного сотрудника в течение часа.
Распределение Пуассона имеет один параметр, обозначаемый символом λ (греческая буква «лямбда») – среднее количество событий за фиксированный промежуток времени. Распределение Пуассона описывается формулой:
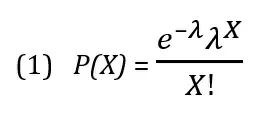
где Р(Х) — вероятность X успешных испытаний, λ — ожидаемое количество успехов, е— основание натурального логарифма, равное 2,71, X— количество успехов в единицу времени.
Вернемся к нашему примеру. Допустим, что в течение часа в среднем сотрудник выдает три карты в час. Какова вероятность того, что в данный час сотрудник выпустит две карты? Применим формулу (1) с параметром X = 3. Тогда вероятность равна
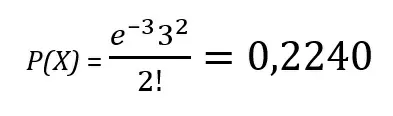
Проведение данных вычислений возможно провести как на калькуляторе или Excel, так и с использованием различных языков программирования (C#, Python). Однако в данной статье, я бы хотел поделиться реализацией алгоритма расчета вероятности на T-SQL. Почему именно на нем? Во-первых, в работе чаще используется именно T-SQL для анализа данных. Во-вторых, не требуется перенос экспорт предрасчитанных данных из БД для анализа в другой среде.
Итак, первым шагом мы создаем таблицу, содержащую статистическую информацию о количестве карт, выданных сотрудниками в течение часа, и среднее количество таких операций по сотруднику (LAMBDA).
if object_id('tempdb.dbo.#stat') is not null drop table #stat
create table #stat
(
EMPLOYEE varchar(120),
EVENT_TIME datetime,
EVENT_COUNT int,
LAMBDA decimal(5,2),
PROB decimal(9,7)
)
Как пример рассмотрим гипотетического сотрудника Иванова, который как в примере расчета вероятности выше в среднем выдает по три карты в час и нам требуется рассчитать вероятность выдачи двух карт.
insert into #stat (EMPLOYEE, EVENT_TIME, EVENT_COUNT, LAMBDA) values ('Иванов', '2020-01-01 09:00:00', 2, 3)Для расчета нам понадобится вспомогательная таблица со значениями факториалов:
declare @maxEventCount int = (select max(EVENT_COUNT) from #stat)
;with factorial as
(
select
1 as i,
1 as f
union all
select
i + 1,
f * (i + 1)
from
factorial
where
i < @maxEventCount
)
insert into
#factorials
select *
from
factorial
Теперь с помощью одного запроса мы сможем рассчитать вероятность по всем записям во входной таблице.
update te
set
PROB = power(LAMBDA, EVENT_COUNT) * power(2.71828, -LAMBDA) / f.factorial
from
#stat te
inner join #factorials f on
te.EVENT_COUNT = f.num
select * from #stat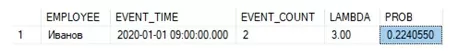
Как видите мы получили аналогичное значение вероятности. В завершении хотелось бы отметить, что применение статистических методов при анализе информации в первую очередь должна быть удобной и эффективной и не являться прерогативой специально созданных математических пакетов, инструментов или языков программирования.