/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
Для демонстрации будет использоваться набор данных, предоставленных в рамках соревнования Don’t Overfit II (ссылка), проводившегося на Kaggle в 2018 году.
Одной из основных проблем построения моделей на малых наборах данных является проблема переобучения. Переобучение – это ситуация, когда модель хорошо объясняет данные обучающей выборки, но при этом плохо работает на примерах, не участвовавших в обучении.
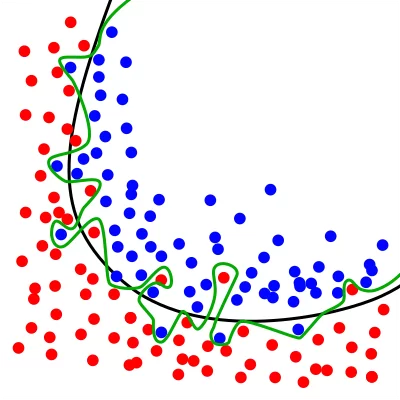
Чем меньше записей рассматривается при построении модели, тем больше различных моделей способны их описать, и тем, соответственно, сложнее подобрать наиболее правильную из них. Одним из способов решения данной проблемы может быть использование простых моделей. Чем сложнее используемая модель, тем больше риск того что полученный результат будет слишком сильно подстраиваться под имеющийся тестовый набор.
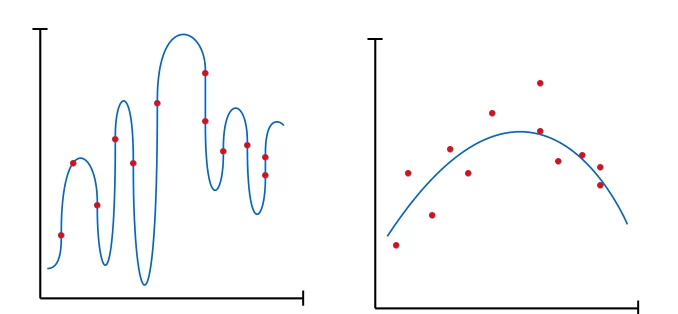
Рис 2. Отличие сложной модели от простой.
Например, для рассматриваемого случая можно использовать логистическую регрессию или дерево решений с ограниченной глубиной.
Пример формирования простых моделей.
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression(
penalty='l1',
C=0.1
)
lr.fit(train[train_columns], target_values)
lr.predict_proba(test[train_columns])[:,1]
from xgboost import XGBClassifier
XGBC = XGBClassifier(
max_depth=2,
gamma=2,
eta=0.8,
reg_alpha=0.5,
reg_lambda=0.5
)
XGBC.fit(train[train_columns], target_values)
XGBC.predict_proba(test[train_columns])[:,1]
Для регуляризации логистической регрессии мы можем управлять параметрами penalty и С, где penalty может принимать одно из допустимых значений (как, например, l1, l2), а параметр С обратно пропорционален степени регуляризации. В случае с деревом, мы можем управлять глубиной (max_depth, чем меньше, тем проще дерево), и параметрами gamma, eta, reg_alpha, reg_lambda, для которых чем выше значение, тем выше регуляризованность модели.
Другой важный фактор, это определение выбросов в данных. Очистка данных важна при построении любых моделей, однако на малых объёмах записей они могут оказывать значительное влияние на результат, внося неточности в нашу модель:
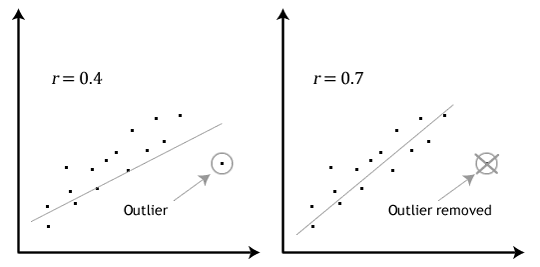
Для подготовки данных можно использовать библиотеку scikit-learn, которая обладает большим набором различных методов поиска выбросов. На рассматриваемых нами данных будет актуально применить метод IsolationForest, который хорошо работает на данных с большим количеством параметров:
from sklearn.ensemble import IsolationForest
isf = IsolationForest(random_state=1)
isf.fit(train[train_columns], train['target'])
isf.predict(train[train_columns])
Алгоритм применения методики IsolationForest для поиска выбросов в данных.
На выходе метод даёт список, в котором на месте выбросов стоит «-1», а на месте вхождений – «1».
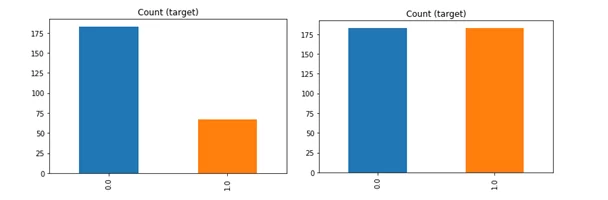
Ещё следует обратить внимание на то, что датасеты с малым количеством записей зачастую бывают несбалансированы, что так же усложняет создание моделей. В таком случае можно искусственным образом сформировать записи, восполняющие недостаток точек, принадлежащих одному из возможных результирующих множеств:
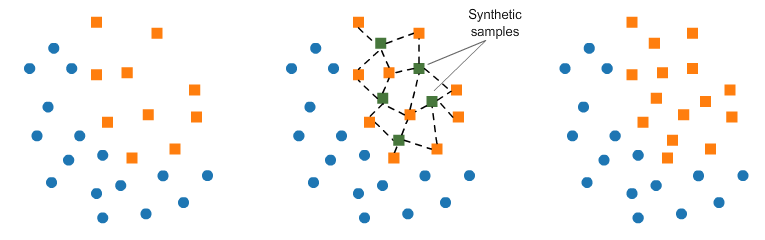
Для формирования таких данных можно использовать алгоритм SMOTE (Synthetic Minority Oversampling TEchnique). Алгоритм работает опираясь на методику k-nearest neighbours, формируя группу соседей для значения в датасете, относящегося к плохо представленному классу, и добавляя точки между ними.
from imblearn.over_sampling import SMOTE
smote = SMOTE(ratio='minority')
X_sm, y_sm = smote.fit_resample(train[train_columns], train['target'])
Алгоритм реализации функции SMOTE.
Полученные новые данные будут искусственным образом сбалансированы, что может помочь для построения модели.
Это лишь небольшой набор из методов, применение которых позволит более точно работать с датасетами, содержащими малое число записей. Тем не менее он может послужить хорошим примером для тех, кто столкнулся с подобными проблемами и натолкнуть их на правильное решение.