/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)
Время прочтения: 5 мин.
Недавно мне понадобилось получить данные с одного сайта. Готовой выгрузки с информацией на сайте нет. Данные я вижу, вот они передо мной, но не могу их выгрузить и обработать. Возник вопрос: как их получить? Немного «погуглив», я понял, что придется засучить рукава и самостоятельно парсить страницу (HTML). Какой тогда инструмент выбрать? На каком языке писать, чтобы с ним не возникло проблем? Языков программирования для данной задачи большой набор, выбор пал на Python за его большое разнообразие готовых библиотек.
Примером для разбора основ возьмем сайт с отзывами banki.ru и получим отзывы по какому-нибудь банку.
Задачу можно разбить на три этапа:
- Загружаем страницу в память компьютера или в текстовый файл.
- Разбираем содержимое (HTML), получаем необходимые данные (сущности).
- Сохраняем в необходимый формат, например, Excel.
Инструменты
Для начала нам необходимо отправлять HTTP-запросы на выбранный сайт. У Python для отправки запросов библиотек большое количество, но самые распространённые urllib/urllib2 и Requests. На мой взгляд, Requests удобнее (примеры буду показывать на ней).
А теперь сам процесс. Были мысли пойти по тяжелому пути и анализировать страницу на предмет объектов, содержащих нужную информацию, проводить ручной поиск и разбирать каждый объект по частям для получения необходимого результата. Но немного походив по просторам интернета, я получил ответ: BeautifulSoup – одна из наиболее популярных библиотек для парсинга. Библиотеки найдены, приступаем к самому интересному – к получению данных.
Загрузка и обработка данных
Попробуем отправить запрос HTTP на сайт, чтобы получить первую страницу с отзывами по какому-нибудь банку и сохранить в файл, для того, чтобы убедиться, получаем ли мы нужную нам информацию.
import requests
from bs4 import BeautifulSoup
bank_id = 1771062 #ID банка на сайте banki.ru
url = 'https://www.banki.ru/services/questions-answers/?id=%d&p=1' % (bank_id) # url страницы
r = requests.get(url)
with open('test.html', 'w') as output_file:
output_file.write(r.text)После исполнения данного скрипта получится файл text.html.
Открываем данный файл и видим, что необходимые данные получили без проблем.
Теперь очередь для разбора страницы на нужные фрагменты. Обрабатывать будем последние 10 страниц плюс добавим модуль Pandas для сохранения результата в Excel.
Подгружаем необходимые библиотеки и задаем первоначальные настройки.
import requests
from bs4 import BeautifulSoup
import pandas as pd
bank_id = 1771062 #ID банка на сайте banki.ru
page=1
max_page=10
url = 'https://www.banki.ru/services/questions-answers/?id=%d&p=%d' % (bank_id, page) # url страницыНа данном этапе необходимо понять, где находятся необходимые фрагменты. Изучаем разметку страницы с отзывами и определяем, какие объекты будем вытаскивать из страницы.
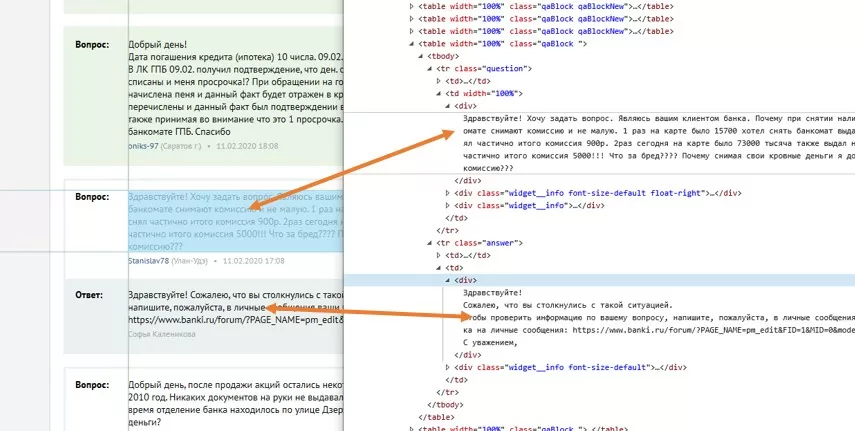
Подробно покопавшись во внутренностях страницы, мы увидим, что необходимые данные «вопросы-ответы» находятся в блоках <table class:qaBlock >, соответственно, сколько этих блоков на странице, столько и вопросов.
result = pd.DataFrame()
r = requests.get(url) #отправляем HTTP запрос и получаем результат
soup = BeautifulSoup(r.text) #Отправляем полученную страницу в библиотеку для парсинга
tables=soup.find_all('table', {'class': 'qaBlock'}) #Получаем все таблицы с вопросами
for item in tables:
res=parse_table(item)Приступая к получению самих данных, я кратко расскажу о двух функциях, которые будут использованы:
- Find(‘table’) – проводит поиск по странице и возвращает первый найденный объект типа ‘table’. Вы можете искать и ссылки find(‘table’) и рисунки find(‘img’). В общем, все элементы, которые изображены на странице;
- find_all(‘table’) – проводит поиск по странице и возвращает все найденные объекты в виде списка.
У каждой из этих функций есть методы. Я расскажу от тех, которые использовал:
- find(‘table’).text – этот метод вернет текст, находящийся в объекте;
- find(‘a’).get(‘href’) – этот метод вернет значение ссылки.
Теперь, уже обладая этими знаниями и навыками программирования на Python, написал функцию, которая разбирает таблицу с отзывом на нужные данные. Каждые стадии кода дополнил комментариями.
def parse_table(table):#Функция разбора таблицы с вопросом
res = pd.DataFrame()
id_question=0
link_question=''
date_question=''
question=''
who_asked=''
who_asked_id=''
who_asked_link=''
who_asked_city=''
answer=''
question_tr=table.find('tr',{'class': 'question'})
#Получаем сам вопрос
question=question_tr.find_all('td')[1].find('div').text.replace('<br />','\n').strip()
widget_info=question_tr.find_all('div', {'class':'widget__info'})
#Получаем ссылку на сам вопрос
link_question='https://www.banki.ru'+widget_info[0].find('a').get('href').strip()
#Получаем уникальным номер вопроса
id_question=link_question.split('=')[1]
#Получаем того кто задал вопрос
who_asked=widget_info[1].find('a').text.strip()
#Получаем ссылку на профиль
who_asked_link='https://www.banki.ru'+widget_info[1].find('a').get('href').strip()
#Получаем уникальный номер профиля
who_asked_id=widget_info[1].find('a').get('href').strip().split('=')[1]
#Получаем из какого города вопрос
who_asked_city=widget_info[1].text.split('(')[1].split(')')[0].strip()
#Получаем дату вопроса
date_question=widget_info[1].text.split('(')[1].split(')')[1].strip()
#Получаем ответ если он есть сохраняем
answer_tr=table.find('tr',{'class': 'answer'})
if(answer_tr!=None):
answer=answer_tr.find_all('td')[1].find('div').text.replace('<br />','\n').strip()
#Пишем в таблицу и возвращаем
res=res.append(pd.DataFrame([[id_question,link_question,question,date_question,who_asked,who_asked_id,who_asked_link,who_asked_city,answer]], columns = ['id_question','link_question','question','date_question','who_asked','who_asked_id','who_asked_city','who_asked_link','answer']), ignore_index=True)
#print(res)
return(res)Функция возвращает DataFrame, который можно накапливать и экспортировать в EXCEL.
result = pd.DataFrame()
r = requests.get(url) #отправляем HTTP запрос и получаем результат
soup = BeautifulSoup(r.text) #Отправляем полученную страницу в библиотеку для парсинга
tables=soup.find_all('table', {'class': 'qaBlock'}) #Получаем все таблицы с вопросами
for item in tables:
res=parse_table(item)
result=result.append(res, ignore_index=True)
result.to_excel('result.xlsx')Резюме
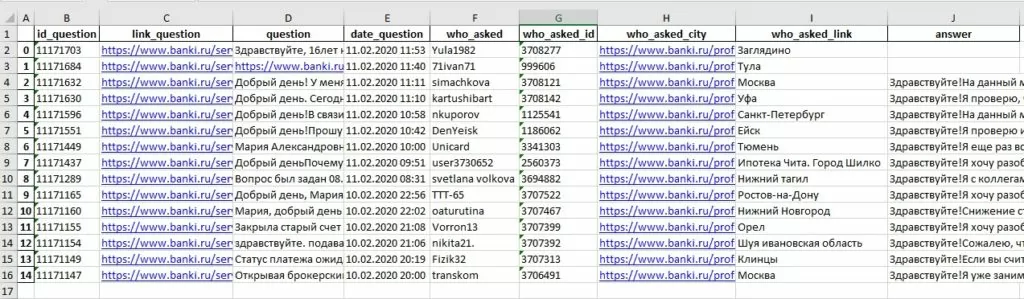
В результате мы научились парсить web-сайты, познакомились с библиотеками Requests, BeautifulSoup, а также получили пригодные для дальнейшего анализа данные об отзывах с сайта banki.ru. А вот и сама результирующая таблица.
Приобретенные навыки можно использовать для получения данных с других сайтов и получать обобщенную и структурированную информацию с бескрайних просторов Интернета.
Я надеюсь, моя статья была полезна. Спасибо за внимание.