/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
Меня, студента 4 курса бакалавриата факультета физики и, с недавнего времени, стажёра в крупной компании, это соревнование не обошло стороной, и почти сразу после его анонсирования, я приступил к подготовке своего решения, которое впоследствии оказалось одним из победных. Здесь я хочу описать свой подход к решению данной задачи и некоторые общие рекомендации по успешному участию в Kaggle-соревнованиях.
Первое, что всегда важно сделать при работе с задачей такого типа, это посмотреть на данные и понять, что от нас требуется. Предлагаю взглянуть на фотографии с подписями меток классов, именно правильное определение всех платёжных систем, которые есть на фото, и есть наша задача. В тренировочном датасете было около 3000 размеченных фотографий, а в тестовом около 1000. Данных не так много, так что логичным было подыскать предобученную модель, и применить технологию transfer learning, что я и сделал. Ориентация карт на фото произвольная, так что логично было применить аугментации поворотов (опишу ниже)

Данные были распределены неравномерно, так что мне пришлось провести процедуру оверсемплинга (искусственного размножения примеров с малочисленными классами, а также примеров с большим количеством карт на одном фото, как на левом фото в нижнем ряду, чтобы нейронная сеть чаще встречала их при обучении).
Изначальное распределение количества карт, на которых есть та или иная платёжная система

Распределение после процедуры оверсемплига:

Как видно, некоторые малочисленные классы немного размножились, но, вероятно, важнее было размножить фотографии с большим числом карт, так как их больше в тестовых данных. А если их больше в тестовых, то надо было научить нашу модель лучше распознавать платёжные системы, которые еле видны на фото.
Также я применил несколько аугментаций к изображениям (создание дополнительных обучающих данных из имеющихся с добавлением чего-то нового в изображениях).

Теперь о модели: я использовал предложенную организаторами архитектуру Faster R-CNN в качестве основного метода, подбирая backbone-сеть для неё. Приведу иллюстрацию, демонстрирующую основную мысль методики.
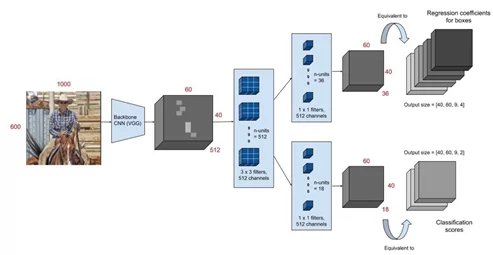
Изображение подаётся на вход предобученной свёрточной нейросети (например, на датасете ImageNet, какую использовал я), затем берётся feature map (карта признаков) с одного из последних свёрточных слоёв, и далее применяется интересная технология RoI-pooling, которая выделяет на изображении фиксированное количество областей интереса (RoI), далее на которых оценивается вероятность принадлежности к какому-либо классу. Таким образом задача разделяется на две параллельные: многоклассовая классификация и регрессия для более точного определения областей, в которых мы детектируем объекты.
Соответственно, функция ошибки становится комбинированной и состоит из классификационного и регрессионного лосса. Вот хорошая статья о том, как работает RoI-pooling.
Далее решающим этапом является правильный подбор backbone архитектуры для Faster R-CNN, то есть выбор той самой сети, которая генерирует feature map. Я опробовал многие известные архитектуры (ResNet 34,50,152; EfficientNet; DenseNet), и лучше всего смогла себя показать DenseNet (121,161,169 (лучшая)), вероятно во многом из-за того, что она хорошо работает при небольшом количестве тренировочных данных, в отличие, скажем, от EfficientNet, которой требуется обычно побольше данных для тренировки.
Тренировку я проводил с помощью PyTorch-Lightning, так как мне нравится его вывод детальной информации об эпохе, которую можно получить. Для обучения понадобилось от 10 до 20 эпох, один цикл обучения длился в среднем несколько часов на мощностях Kaggle и Google Colab. В процессе обучения сохранял лучшую модель по лоссу на валидации и по целевой метрике – расстоянию Левенштейна.
Целевая метрика, кстати, очень чувствительна к серьезным изменениям в очень малом количестве примеров, поэтому даже если мы предскажем верно все платежные системы в почти всех примерах, но в одном предскажем абсолютно не те, то значение метрики будет низким, как будто мы много в каких примерах ошиблись. Это надо учитывать, если выбирать лучшую модель по значению расстояния Левенштейна. Будьте внимательны, если используете эту метрику как основную в своей задаче.
Добавлю пару полезных “лайфхаков” по участию в DS-соревнованиях:
- Не пренебрегайте возможностью посмотреть безлайн, предложенный организаторами, если он есть. У меня это сэкономило достаточное количество времени.
- Приступайте к подготовке решения сразу после начала соревнования, ибо потом времени может не хватить. Соревнования на Kaggle, если Вы желаете в них победить, требуют много вашего времени и сил, сроки в несколько месяцев на соревнование даются не просто так.
- Старайтесь максимально использовать свои попытки отправки решения в Kaggle.
- Отправлять на финальный скоринг не обязательно две лучшие модели на публичной части тестовых данных, а модели, которые сделаны максимально по-разному и при этом имеют обе довольно неплохой скор, на приватной части тестовых данных ситуация может поменяться иногда кардинально.
В заключение прилагаю ссылку на своё решение на Kaggle. Кого заинтересовала техническая сторона реализации, можете взглянуть, там тоже много комментариев