/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 11 мин.
В 2017 году на свет вышла статья разработчиков Google под названием «Attention is All You Need». В ней впервые была предложена идея трансформеров — моделей машинного обучения, ключевой особенностью которых было использование так называемых «слоев внимания», определяющих, какие слова и в какой степени важны для формирования контекста предложения. Публикация стала началом активного развития и продвижения моделей машинного обучения на описанной архитектуре.
Первоначально архитектура трансформеров была нацелена на языковой перевод текстов. В своей основе модель содержала два компонента: кодирующий (encoder) и декодирующий (decoder). Во время обучения encoder получал предложения на языке оригинала, а decoder – их перевод. При этом encoder сразу обрабатывал все слова в предложении, а слои decoder в начале осуществляли работу последовательно, определяя следующее слово на основе уже предсказанных, но после все равно получали полные данные из encoder, улучшая результат.
Необходимость учитывать весь контекст связана с тем, что в естественном языке одни слова предложения ключевым образом зависят от других. Например, правильное написание фразы «я работаю в IT» зависит от содержащихся в ней местоимений и предлогов. Для местоимения «я» правильно будет «работаю», для «ты» — «работаешь». Однако контекст не всегда находится в непосредственной близости от рассматриваемого слова, в том числе не всегда предшествует ему. Фразы на разных языках могут быть построены совершенно непредсказуемым образом, отчего модель должна определять ключевые для предсказания слова во всем передаваемом диапазоне. Этим и занимаются слои внимания, устанавливающие зависимость каждого слова от остальных.
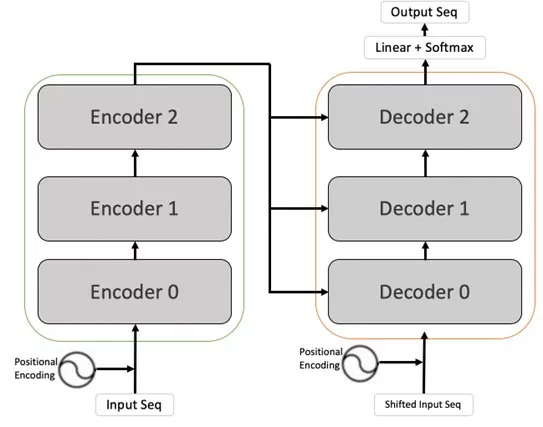
Рис. 1. Схема работы трансформерных моделей машинного обучения.
Несмотря на успешные разработки в данном направлении, результаты работы трансформеров содержат множество допущений, от чего их использование не всегда оправдано. И если в качестве консультационных, поисковых и агрегирующих возможностей они используемы здесь и сейчас, то в задачах, требующих точность и ответственность исполнителя, доверять работу ИИ все еще рано.
Тем не менее, когда перед нашей командой встал вопрос создания инструмента для исправления текстовых документов, мы решили, что совсем не использовать мощь NLP в современных условиях будет неправильно. В то же время предварительные тесты выявили два интересных факта. Во-первых, как было сказано выше, нельзя доверять документ модели без последующей валидации человеком. Тем более, когда речь идет о важной документации, в которой случайная орфографическая или пунктуационная ошибка допустима (хоть и неприятна), но изменение смысла, своевольное дополнение или неправильная интерпретация точно недопустимы. Поэтому пока невозможно исключить из процесса пользователя.
Второе же наблюдение позволило сформулировать иной подход к первоначальной задаче. Дело в том, что модель может периодически ошибаться в том, как исправить ошибку, но гораздо реже ошибается в самом факте ее наличия. Другими словами, если модель получала строку с опечаткой, то результатом могло быть откровенно неправильное исправление. Но главное — она принципиально понимала, что слово само по себе какого-то исправления требует.
Результатом этих наблюдений стала идея трансформировать решение задачи от исправления текста к детекции ошибки и информирование о ней пользователя. И уже пользователю будет предоставляться право выбора, какие ошибки нужно исправить, а куда программе лезть не стоит. Данный подход имел ряд преимуществ. В первую очередь, эффективность детекции ошибки оказалась значительно выше ее исправления, что подтвердили предварительные тесты (Таблица 2).
Таблица 2. Сравнение доли найденных ошибок и исправленных верно.
| Кол-во слов всего | Слов с ошибкой | Найдено ошибок | Исправлено верно |
| 320 | 126 | 121 | 106 |
| Качество, % | — | 96% | 84% |
Кроме того, если валидация результата пользователем все равно неизбежна, то программа облегчала такую работу, не создавая новых «ошибок», но подсвечивая предполагаемые. Наконец, сохранялась возможность использовать предлагаемое моделью исправление в качестве рекомендации пользователю, тем самым частично автоматизировав процесс фактического исправления текста.
Для создания инструмента было принято решение использовать модель T5, предварительно обученную для исправления текста после транскрибации аудио. T5 – нейросетевая модель для генерации текста, разработанная специалистами Google. Название отражает суть модели text-to-text transfer transformer. Google выпустил две ее версии: первая понимает только английский язык, зато дообучалась на 24 разных задачах, а вторая понимает 101 язык (включая русский), но умеет только заполнять пропуски в тексте. От чего всегда требуется дообучение данной модели под конкретную задачу.
Одним из отличительных аспектов архитектуры T5 является принцип преобразования текста в текст (text-to-text) для всех своих задач. Подход преобразования text-to-text — это уникальная и мощная парадигма. В отличие от традиционных моделей, которые требуют конкретной архитектуры для каждой задачи, эта модель рассматривает все задачи обработки естественного языка как одинаковую проблему. Этот подход дает несколько преимуществ. Во-первых, это упрощает процесс обучения и развертывания за счет использования одной модели для нескольких задач. Кроме того, это устраняет необходимость в архитектурах, ориентированных на конкретные задачи, и снижает сложность разработки и поддержки отдельных моделей для каждой задачи.
Во-вторых, подход преобразования текста в текст способствует передаче обучения. Тренируясь над различными задачами, T5 может изучить обобщенные представления языка и приобрести широкие лингвистические знания. Это позволяет модели использовать свое понимание различных языковых моделей и структур для эффективного выполнения новых задач с ограниченными обучающими данными, включая исследуемую здесь задачу поиска и исправления грамматических ошибок.
Возвращаясь к созданному на основе T5 инструменту, основной принцип его работы заключается в последовательном выполнении двух ключевых действий: генерации моделью «правильного» варианта предложения и сравнении между собой первоначального и исправленного варианта. Слова, в которых модель согласилась с первоначальным вариантом и не внесла исправления, считаются верными. А те, в которых модель определила несоответствие и попыталась исправить – ошибочными.
Предобученная модель была взята из открытых источников (https://huggingface.co/UrukHan/t5-russian-spell). Первый модуль программы представляет собой функцию, создающую объекты необходимых классов библиотеки Transformers и выполняющую генерацию и декодирование исходящей последовательности.
def spell_correction(input_sequences):
model = AutoModelForSeq2SeqLM.from_pretrained(MODEL_PATH)
tokenizer = T5TokenizerFast.from_pretrained(TOKENIZER_PATH)
sequences_list = split_into_sentences(input_sequences)
task = [f"Spell correct: {sequence}" for sequence in sequences_list]
tensors = tokenizer(task, padding="longest", max_length=256, truncation=True, return_tensors="pt")
output = model.generate(**tensors)
return tokenizer.batch_decode(output, skip_special_tokens=True)
В коде используются локальные пути к модели и токенайзеру. С помощью библиотеки nltk текст разбивается на предложения, в которые подставляется префикс задания для модели. Далее формируются тензоры входной последовательности и маски внимания с заполнением входных данных по самой длинной последовательности и обрезкой превышающих максимальный размер. В качестве библиотеки для формирования тензоров используется PyTorch. Затем тензоры передаются в модель, а исходящие токены декодируются в текст. Результатом функции будет список исправленных предложений.
Вторая ключевая функция осуществляет сравнение входного и сгенерированного предложений, собирая массивы ошибок по двум категориям: орфографические, включая ошибки в формах слов, и пунктуационные, разделяя их, в свою очередь, на отсутствующую пунктуацию и излишнюю.
def compare_strings(input_, output):
words_with_errors = []
punctuation_added = []
punctuation_remooved = []
input_arr = re.findall(r"\b\w+\b", input_)
output_arr = re.findall(r"\b\w+\b", output)
input_idx = 0
for word in difflib.ndiff(input_arr, output_arr):
if word[0] != "+" and word[0] != "?":
if word[0] == "-":
words_with_errors.append((input_idx, word[2:]))
input_idx += 1
for idx, symbol in enumerate(difflib.ndiff(input_, output)):
if symbol[0] == "-" and not symbol[2].isalnum() and not symbol[2] == " ":
punctuation_remooved.append((idx, symbol[2]))
if symbol[0] == "+" and not symbol[2].isalnum() and not symbol[2] == " ":
punctuation_added.append((idx, symbol[2]))
return words_with_errors, punctuation_added, punctuation_remooved
Результат работы обеих модулей сохраняется в текстовый файл, где для каждого предложения указываются орфографические ошибки с позицией ошибочного слова, а также пунктуационные ошибки с индексом неправильного (отсутствующего) знака препинания.
Input: В своей аснове он содержет два кампонента кодирующий (encoder) и декодирующий (decoder).
Orthography: [(2, 'аснове'), (4, 'содержет'), (6, 'кампонента')]
Punct+: [(42, ':')]
Punct-: []
Очевидно, это рабочий вывод для целей тестирования, который в пользовательском использовании не очень удобен. Поэтому на следующем этапе в планах реализовать разметку docx документа, выделение ошибок цветом или комментарием на полях в самом документе.
Но на текущий момент, получив рабочую версию инструмента, мы протестировали его работу и сравнили результат с альтернативными способами поиска ошибок. В сравнении участвовали редактор Microsoft Word, ресурсы Text.ru и Yandex.Speller, а также другой инструмент нашей разработки, основанный на использовании словарей слов (с рабочим наименованием Сorrector). В каждом случае на проверку передавался отрывок текста, состоящий из 320 слов, в 126 из которых нами специально была допущена орфографическая ошибка или опечатка. После чего подсчитывалось отношение количества найденных ошибок к их общему числу (Таблица 3).
Таблица 3. Сравнение различных инструментов детекции ошибок.
| Инструмент | Найдено | % (от 126) | «Это связано с тем, что в естествином язык одни слава предложения сильно зависят от другие». |
| MS Word | 96 | 76,19% | «естествином» |
| Text.ru | 102 | 80.95% | «естествином», «от другие» |
| Ya.Speller | 40 | 31.75% | «естествином», «слава» |
| Corrector | 115 | 91.27% | «естествином» |
| Model-T5 | 121 | 96.03% | «естествином», «язык», «слава», «другие» |
MS Word «подчеркнул» 96 ошибочных слов, пропустив слова в неправильной форме, а также такие, которые в результате опечатки приобрели другое значение (модели – мотели). Text.ru повел себя аналогичным образом, однако в отдельных случаях определил неправильные связи с предлогами («от другие» было отмечено как ошибка). Сильно удивила неспособность Ya.Speller определить большинство созданных нами ошибок, хотя в характере его работы угадывалась схожесть с нашим инструментом. Местами ему удавалось определить неправильно используемое слово, чего не могли другие редакторы, тем не менее, в общей массе по неизвестным причинам результат оказался удурчающим. А вот другой наш инструмент (Corrector) показал себя неплохо, попадая в ошибку даже чаще, чем MS Word и Text.ru.
Таблица 4. Прямое сравнение с MS Word
| MS Word | |
| MS Word пропускает слова в не правильной форме (неправильно пишется слитно), а также такие, которые в результате опечатки приобрели другое значение. Например, «NLP это большие языковые мотели» — MS Word не видит, что слово «мотели» ошибочно в контексте, а также не понимает, что пропущено тире после слова «не видит». Кроме того, не видит слова использованный в другом времени или падеже. | MS Word не подчеркивает никаких ошибок. По его мнению представленный текст – верный. |
| T5 Model | |
| Input:MS Word пропускает слова в не правильной форме (неправильно пишется слитно), а также такие, которые в результате опечатки приобрели другое значение. Output: MS Word пропускает слова в неправильной форме (неправильно пишется слитно), а также такие, которые в результате опечатки приобрели другое значение. Orthography: [(5, ‘не’), (6, ‘правильной’)] Punct+: [] Punct-: [] | В первом предложении модель детектировала ошибку в слове «не правильной», т.к. в данном контексте нужно писать слитно. Ошибок пунктуации не найдено. |
| Input: Например, «NLP это большие языковые мотели» — MS Word не видит, что слово «мотели» ошибочно в контексте, а также не понимает, что пропущено тире после слова «не видит». Output: Например, «NLP — это большие языковые модели» — MS Word не видит, что слово «мотели» ошибочно в контексте, а также не понимает, что пропущено тире после слова «не видит». Orthography: [(6, ‘мотели’)] Punct+: [(15, ‘-‘)] Punct-: [] | Во втором предложении модель определила неправильно использованное слово «мотели», а также необходимость добавления знака пунктуации «-». |
| Input: Кроме того, не видит слова использованный в другом времени или падеже. Output: Кроме того, он не видит слова, использованные в другом времени или падеже. Orthography: [(5, ‘использованный’)] Punct+: [(29, ‘,’)] Punct-: [] | В третьем предложении модель обнаружила неправильное время слова «использованный». В том числе, обнаружила пропущенную запятую после слова «слова». |
Рассматриваемая же в данном посте модель справилась выше ожиданий, набрав 96% точности. Кроме того, для каждой из 121 детектированной ошибки моделью был предложен вариант для замены слова, из которых 106 оказались правильными (Таблица 2). Однако, несмотря на то, что долю правильных исправлений в размере 84% можно назвать высокой, неверно предложенные варианты существенно портили текст, предлагая порой искажающие первоначальный смысл исправления. Так, «идея трансформИров» могла стать «идеей трансформаций», «принцип работы слАЕв» стал «принципом работы слов», а «игнАрировать» каким-то образом заменялось на «играть».
Следует учитывать, что ошибки в текст вносились целенаправленно, следствием чего могла стать их неестественность и «нечеловечность». В результате чего модель могла ошибаться с предлагаемыми исправлениями, так как была обучена на естественных, а не сгенерированных случаях (возможно, в этом также заключалась причина «провала» Ya.Speller). Проверка данного предположения и полноценное тестирование требует отдельного исследования, включающего в том числе сбор собственного корпуса данных о естественных ошибках и опечатках русского языка.
Помимо орфографических ошибок, модель успешно детектировала неправильную форму слова, падеж и число. Кроме того, были детектированы пунктуационные ошибки, несмотря на то, что специально они нами в текст не вносились и в статистике не учитывались. Так, в представленном на оценку тексте совершенно верно была обнаружена нехватка трех запятых и одного двоеточия, а также нашлась лишняя запятая, которую модель предложила убрать.
Результатом проведенной работы стал успешно работающий функционал, однако для его полноценного использования необходима дальнейшая работа, включающая дообучение модели на специализированном корпусе документов, проведение глубоких тестов, выявление и устранение ошибок в работе, неправильных срабатываний. Кроме того, со времени создания инструмента вышла версия модели FRED-T5, обученная разработчиками Сбера, для которой заявлены схожие возможности. Поэтому в планах проведение сравнительного анализа различных вариантов моделей и выбор наилучшей для данного типа задач. Наконец, все еще необходимо создание удобного интерфейса для взаимодействия с инструментом как в режиме онлайн, так и для разметки готовых документов.
Ну а пока можно провести финальный тест модели перед публикацией, проверив мой пост описываемым инструментом. И если какая-то ошибка оказалась им пропущена – обязательно дайте знать!