/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 7 мин.
В качестве примера для детекции объектов будем использовать алгоритм YOLOv3. Дополнительные материалы по статье вы сможете найти на github странице. Пример установки и настройки осуществляется на ОС Windows 10.
В первую очередь нам необходимо скачать или клонировать необходимые материалы для переобучения нейронной сети под определенный тип объекта с данной github страницы. Для того чтобы не возникало проблем с доступом или разрешениями, материалы лучше разместить в директории своей учетной записи, например: C:\Users\user_name\Documents\NN\.
- Переходим в папку yolov3-master, вызываем терминал (командную строку) и выполняем команду pip install —U —r requirements.txt. При запуске команды некоторые из пакетов не установились, т.к в репозитории pip для windows, пакетов с таким названием не существует. Чтобы установка прошла успешно, в requirements.txt мы должны закомментировать несколько пакетов («torch >= 1.5» и «pycocotools»). Затем установить pytorch с помощью следующей команды:
pip install torch==1.5.0 torchvision==0.6.0 -f https://download.pytorch.org/whl/torch_stable.htmlПакет pycocotools внашем случае не понадобится. Также необходимо скачать и установить CUDA tools, для того чтобы ваши вычисления проходили на видеокарте, что в разы увеличивает скорость переобучения.
- После успешного завершения установки можем приступать к подготовке данных. Для лучшей работы алгоритма фотографии для обучения необходимо брать с материалов, на которых будет производится обработка. Например, необходимо обработать видеоматериалы с камер видеонаблюдения, которые установлены в помещении, где объекты располагаются под большим углом. В такой ситуации будет очень сложно обучить алгоритм для детекции объектов, которые сильно отличаются от картинок в интернете, на которых была обучена нейронная сеть. Таким образом, обучающая выборка составляется либо из скрин-снимков по видеоматериалам, либо с помощью ручной съемки фотоаппаратом. Размер обучающей выборки может сильно варьироваться, все зависит от характера задачи. В данном примере набор данных состоит из 46 картинок, на которых изображены три типа объектов (ручка, карандаш, маркер). Фотосъемка производилась на фоне стола и листа А4.
- Следующий этап состоит в разметке объектов на изображении. Однако, перед тем как приступить к разметке, необходимо увеличить обучающую выборку с помощью нескольких методов аугментации. Это важно для улучшения способностей нейронной сети к распознаванию объектов в различных вариациях. Несколько примеров аугментации можно найти в данной тетрадке. По завершении аугментации объединяем оригинальные изображения с результатом аугментации в одну папку (важно, изображения должны располагаться в корне папки yolov3_master, например: NN\ yolov3_master\images\). Далее с помощью программы labelImg проводим разметку объектов, последовательно выполняя следующие шаги:
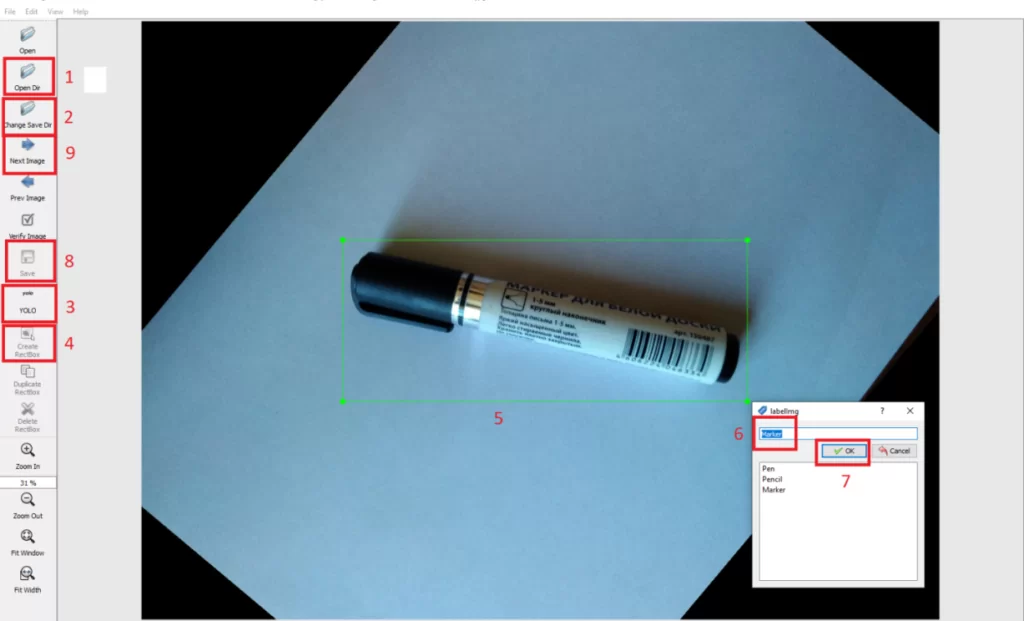
- выбираем папку с изображениями (…\yolov3_master\images\);
- выбираем папку для сохранения меток. Необходимо создать новую папку с названием labels, в той же директории где изображения (….\yolov3_master\labels\);
- меняем тип меток c PascalVOC на YOLO;
- нажимаем на инструмент выделения объектов;
- полностью выделяем все объекты, для которых хотим обучить алгоритм;
- задаем название для каждого из типов объектов (Pen, Pencil, Marker), после первого ввода эти названия буду доступны в списке для следующих изображений;
- подтверждаем;
- сохраняем метку;
- переходим к следующему изображению и повторяем пункты 4 – 8.
В результате в папке labels появятся текстовые документы с названиями изображений, в которых содержится метка класса и четыре координаты — нормализованные значения x,y,w,h, которые описывают расположение прямоугольника для каждого объекта на изображении (1 – это номер строки в редакторе Notepad++ и не относится к содержимому документа):

- Далее нам необходимо разделить подготовленную выборку на обучающую и тестовую. В данном случае необходимо создать 2 текстовых документа (train_112.txt и test_24.txt), в которых будут указаны полный путь расположения для каждого изображения. Пример создания документов можно найти в тетрадке.
- Для того чтобы искомые объекты были именованными необходимо создать файл с расширением .names, например objects.names, в котором указаны имена в том же порядке, как указано в classes.txt в папке labels. Выглядит примерно так:
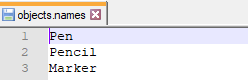
Далее необходимо создать файл с расширением .data, например conf.data, в котором указано количество классов (в данном примере 3), файлы с именами объектов, а также файлы с расположением изображений для обучающей и тестовой выборки:

Файлы objects.names, conf.data и последующие файлы необходимо поместить в следующую директорию: yolov3_master\data\, заранее удалив с неё все файлы.
- Для переобучения необходимо настроить конфигурационный файл, для этого с папки (…\yolov3_master\cfg) копируем файл yolov3-spp.cfg в папку (…\yolov3_master\data). Далее необходимо отредактировать строки (636,643 — 722,729 — 809,816) для каждого из трех слоев:
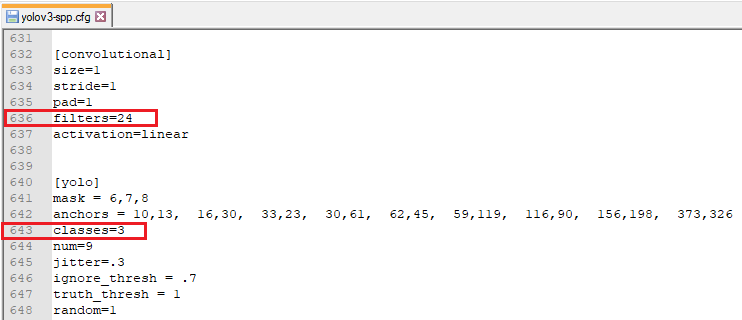
Где, filters = (5 + n) * 3 и classes = n. n – количество классов (в данном примере 3).
- Далее необходимо скачать веса для настроенного конфигурационного файла. Для этого со страницы скачиваем файл yolov3-spp.pt и помещаем его в (…\yolov3_master\data). Для примера используется алгоритм yolov3-spp. Однако существует еще несколько вариаций алгоритма, например, yolov3-tiny, что является облегченной версией yolov3-spp. Облегченная версия менее точна, но при это скорость обработки материалов значительно выше.
- Переходим непосредственно к переобучению алгоритма под свой тип объекта. Для этого в папке …\yolov3_master\ запускаем командную строку и вводим следующую команду:
python train.py --cfg data/yolov3-spp.cfg --data data/conf.data --weights data/yolov3-spp.pt --nosaveПосле запуска команды может возникнуть ошибка следующего характера:
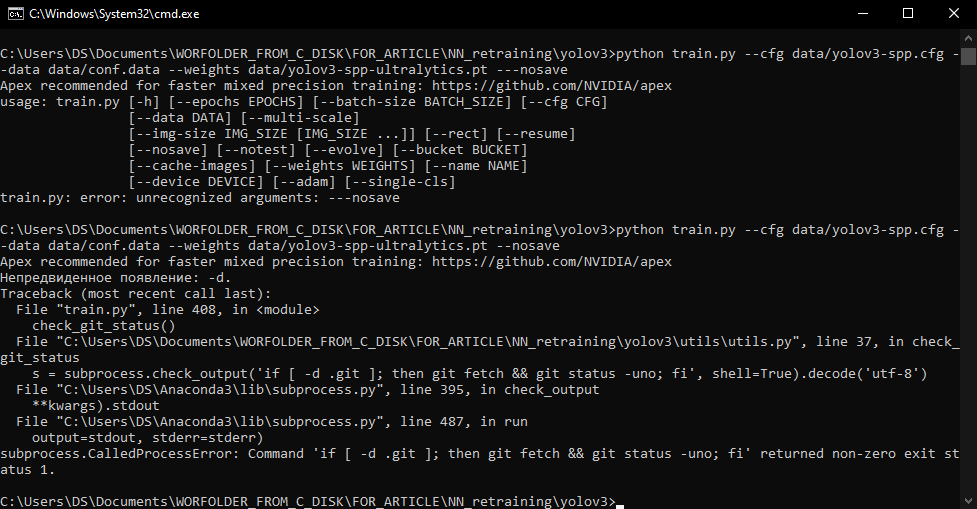
Для решения данной проблемы необходимо закомментировать строки в файле utils.py в папке utils:

В теле функции check_git_status закомментируем все строкикроме print, в который передадим любую строку, например, «ss».
Также может появиться ошибка следующего вида:
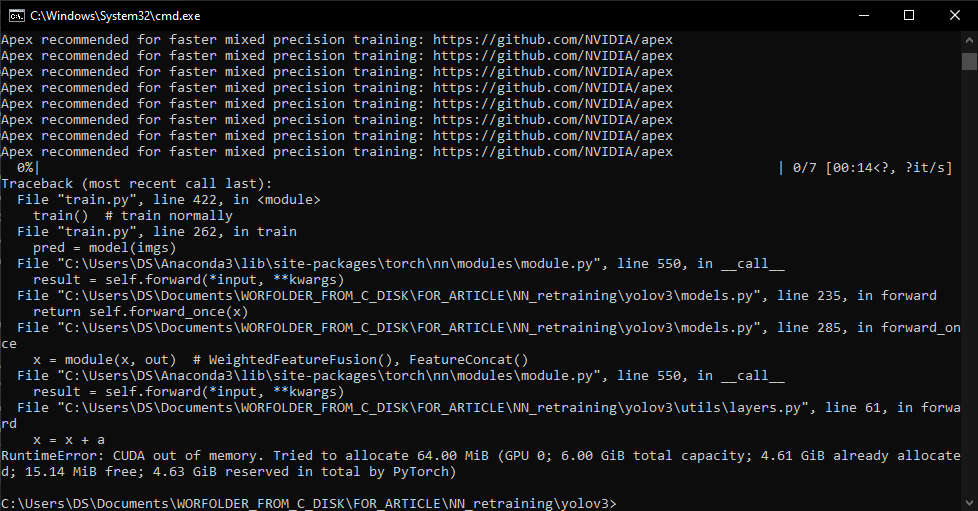
Данная ошибка говорит о том, что не хватает памяти видеокарты для построения вычислительного графа. Одним из способов решения данной проблемы является уменьшение размера батча при обучении. Для этого в файле (…\yolov3_master\train.py) необходимо изменить параметр batch_size, по умолчанию установлено 16, изменим на меньшее значение (8 или 4) кратное 4:
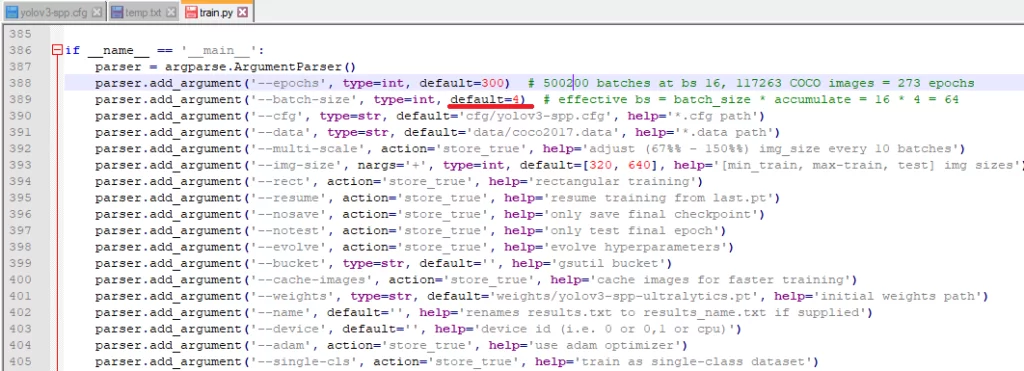
Также данное значение можно передать явно, используя значение параметра при инициализации:
python train.py --cfg data/yolov3-spp.cfg --data data/conf.data --weights data/yolov3-spp.pt --batch-size 4 --nosaveВ примере выше мы указали конфигурационный файл, файл с информацией об обучающей выборке, веса и параметр сохранения.
Параметр —nosave указывает на то что будет сохранен только финальный файл с весами. Также можно настроить в файле train.py режим сохранения, например, если вы хотите сохранять веса каждые 400 epoch:

Также важно указать параметр —epochs, количество эпох зависит от типа объектов, объема обучающей выборки и других факторов. В данном примере изначально было 46 изображений, с помощью методов аугментации набор данных увеличился до 136, из них 112 – обучающая выборка, 24 – тестовая выборка. Вычисления проводились на видеокарте GTX 1060 6 GB. Первая попытка проводилась для 300 эпох, обучение заняло порядка 2.5 часов. Выявилась очень плохая точность алгоритма. Вторая попытка проводилась для 1200 эпох, обучение заняло ~ 12 часов. По окончании обучения в папку (…\yolov3_master\weights\) сохранятся веса — файл last.pt. Для того чтобы проверить работоспособность алгоритма необходимо запустить следующую команду:
python detect.py --weights weights/last.pt --cfg data/yolov3-spp.cfg --names data/objects.namesПеред запуском команды необходимо поместить изображения для обработки алгоритмом в папку (…\yolov3_master\data\samples\). Результат появится в папке (…\yolov3_master\output\).

Таким образом, проведено переобучение готовой нейронной сети, которая была способна определять 80 классов объектов, под новые 3 типа объекта, не вошедших в этот список. Для объекта «маркер» алгоритм не совсем точен, уверенность составляет меньше 0.5. Одной из причин может быть малый размер обучающей выборки, т.к. в данном примере изображений с маркерами было 26 %, остальное ручки и карандаши.