/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 7 мин.
По роду деятельности мне периодически приходится заниматься анализом процессов или Process Mining’ом. Process Mining – это совокупность подходов для анализа и усовершенствования процессов в информационных системах. На вход мы подаем лог событий системы и в большинстве случаев строим граф. Лог должен содержать минимум 3 колонки: id кейса(сессии), дата события, название события. Например,
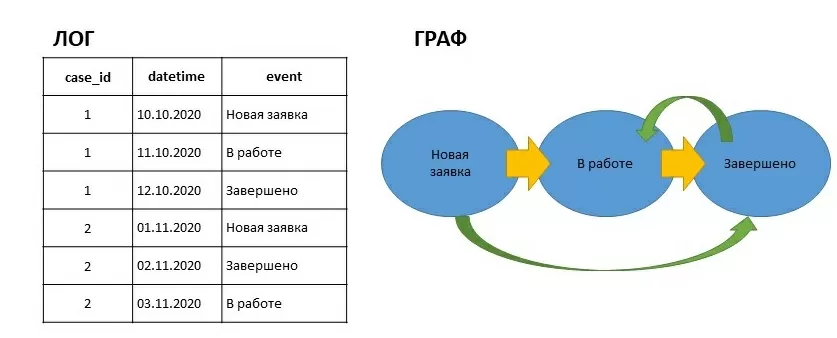
Результирующий граф состоит из наложения графа для кейса 1(желтые ребра) и кейса 2(зеленые). Глядя на этот граф, мы можем задаться вопросом: почему заявка после завершения пошла в работу? Таким образом, визуализируя процесс мы упрощаем задачу поиска выбросов.
В данный момент существует множество программ и библиотек для построения графов и анализа процессов, например, proM, pm4py, disco, apromore, celonis и другие. Каждый инструмент чем-то хорош, но все они не удовлетворяли моим потребностям в полной мере. Периодически возникала необходимость обрабатывать большие логи (12+ Гб) на моем слабеньком ПК (3ГБ свободной ОЗУ). Существующие решения загружают весь датасет в оперативную память, что не позволяло анализировать большие логи. Возможности фильтрации есть далеко не в каждом решении, мне не хватало предложенных возможностей.
Задумка написать свой майнер появилась давно, но именно участие в международном конкурсе BPIC2020 (business process inelegance challenge) подтолкнуло меня к действиям. По условиям конкурса поощрялись собственные разработки в области Process Mining. Победить нашей команде не удалось, но был получен хороший опыт как в области разработки, так и в анализе процессов. Получившуюся программу я назвал myPM.
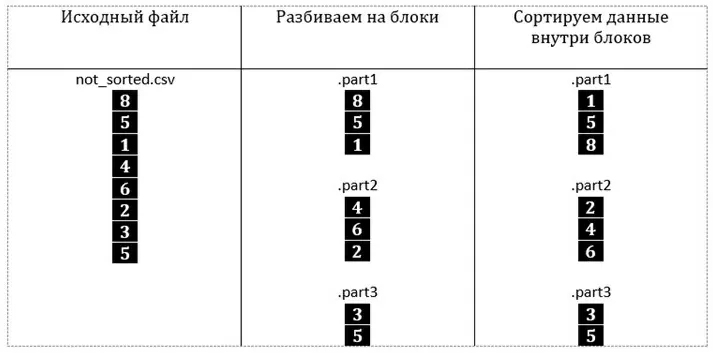
Чтобы построить граф, не загружая весь лог в память нужно отсортировать кейсы по идентификатору. Затем считывать из файла данные порциями, например, по 1 кейсу и накладывать их на результирующий граф. Для *.XES (xml-формат логов для Process Mining) формата этой проблемы не существует, т.к. маршруты (наборы кейсов с общим идентификатором) изначально отсортированы. В моей же практике приходится чаще работать с выгрузками *.CSV.
Но как отсортировать файл большого размера, не помещая его полностью в оперативную память?
Все гениальное просто. Сортировка слиянием. На самом деле алгоритм придуман уже давно, оставалось применить его для моих структур данных. Суть заключается в разделении исходного файла на несколько кусочков, которые мы сможем последовательно отсортировать, загружая полностью в ОЗУ, например по 100Мб.
Код метода SplitSort:
public void SplitSort()
{
int split_num = 1;
long read_line = 0;
int rowNum = 0;
int runnigThrCnt = 0;
void writeToFile(ref List<Row> partitionRows, ref int sn)
{
int num = sn;
sn++;
while (runnigThrCnt == 4)
{
Thread.Sleep(100);
}
List<Row> temp = partitionRows;
Interlocked.Increment(ref runnigThrCnt);
_ = Task.Run(() =>
{
string[] sorted = temp.OrderBy(r => r.caseId).ThenBy(r => r.datetime).Select(r => r.ToString(logInfo)).ToArray();
File.WriteAllLines(Path.Combine(tempDir, string.Format("sorted{0:d5}.dat", num)), sorted);
sorted = null;
temp = null;
GC.Collect();
Interlocked.Decrement(ref runnigThrCnt);
});
partitionRows = new List<Row>();
}
using (StreamReader sr = new StreamReader(logInfo.sourceLogPath, logInfo.CsvEncoing))
{
List<Row> partitionRows = new List<Row>();
while (sr.Peek() >= 0)
{
rowNum++;
string str = sr.ReadLine();
if (++read_line % 5000 == 0)
{
double val = 100.0 * sr.BaseStream.Position / sr.BaseStream.Length;
Console.Write("{0:f2}% \r", val);
worker.SetValue((int)val);
}
partitionRows.Add(new Row(str, logInfo));
if (partitionRows.Count > chunkSize && sr.Peek() >= 0)
{
writeToFile(ref partitionRows, ref split_num);
}
}
if (partitionRows.Count > 0)
writeToFile(ref partitionRows, ref split_num);
while (runnigThrCnt != 0)
{
Thread.Sleep(100);
}
}
}
Открываем отсортированные файлы, читаем из каждого по первой и строке и записываем минимальное из значений в результирующий файл:
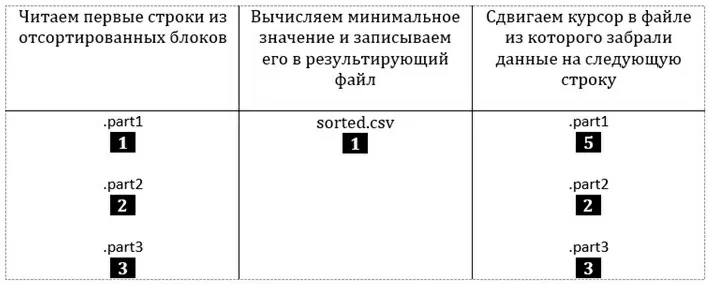
Процесс повторяется, пока все строки в блоках не будут записаны в конечный файл
Код метода MergeTheChunks:
public void MergeTheChunks()
{
string[] paths = Directory.GetFiles(tempDir, "sorted*.dat");
int chunks = paths.Length;
int bufferlen = 50000;
StreamReader[] readers = new StreamReader[chunks];
for (int i = 0; i < chunks; i++)
readers[i] = new StreamReader(paths[i]);
Queue<Tuple<string, string>>[] queues = new Queue<Tuple<string, string>>[chunks];
for (int i = 0; i < chunks; i++)
queues[i] = new Queue<Tuple<string, string>>(bufferlen);
for (int i = 0; i < chunks; i++)
LoadQueue(queues[i], readers[i], bufferlen);
StreamWriter sw = new StreamWriter(logInfo.GetSortedFilePath, false, Encoding.UTF8);
bool done = false;
int lowestIndex, j, progress = 0;
int rowsCnt = 0;
while (!done)
{
if (++progress % 5000 == 0)
{
double val = 100.0 * progress / (chunks * chunkSize);
Console.Write("{0:f2}% \r", val);
worker.SetValue((int)val);
}
lowestIndex = -1;
string lowestValue = "0";
string row = "";
for (j = 0; j < chunks; j++)
{
if (queues[j] != null)
{
Tuple<string, string> currItem = queues[j].Peek();
if (lowestIndex < 0 || currItem.Item1.GetHashCode() < lowestValue.GetHashCode())
{
lowestIndex = j;
lowestValue = currItem.Item1;
row = currItem.Item2;
}
}
}
if (lowestIndex == -1)
{
done = true; break;
}
sw.WriteLine(row);
rowsCnt++;
queues[lowestIndex].Dequeue();
if (queues[lowestIndex].Count == 0)
{
LoadQueue(queues[lowestIndex],
readers[lowestIndex], bufferlen);
if (queues[lowestIndex].Count == 0)
{
queues[lowestIndex] = null;
}
}
}
sw.Close();
worker.SetMessage("Удаление временных файлов");
for (int i = 0; i < chunks; i++)
{
readers[i].Close();
File.Delete(paths[i]);
}
Directory.Delete(tempDir); }
Сортировку слиянием нельзя назвать быстрым процессом, т.к. приходится дважды записывать исходный файл на жесткий диск (при разбиении на блоки и при формировании сортированного файла). Но изменяя размер блока и буфера при слиянии мы можем ограничивать объем используемой ОЗУ. Единственным ограничением становится размер жесткого диска.
Были произведены замеры производительности на тестовом логе размером 849мб (Формат .CSV, 3кк кейсов, 24кк строк)
| Время обработки | Использование ОЗУ в пике | Использование ЦПУ | |
| pm4py (сервер) | 8мин | 17Гб | 100% |
| myPM (Рабочий ПК) | 4м55сек | 500Мб | 25% |
Этот замер времени так же включает в себя отрисовку с помощью внешней библиотеки GraphViz.
Лог, размером 12Гб сортируется на моем ПК (3Гб свободной ОЗУ) чуть больше часа.
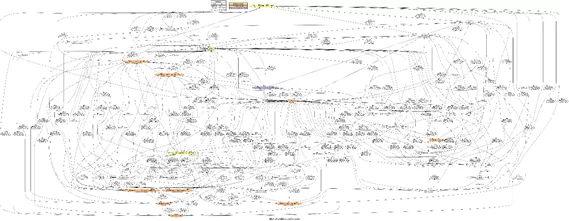
В реальной жизни логи систем могут содержать миллионы событий, состоять из неполных кейсов и событий, усложняющих и запутывающих граф. Если не очищать граф от лишней информации его восприятие может быть затруднено.
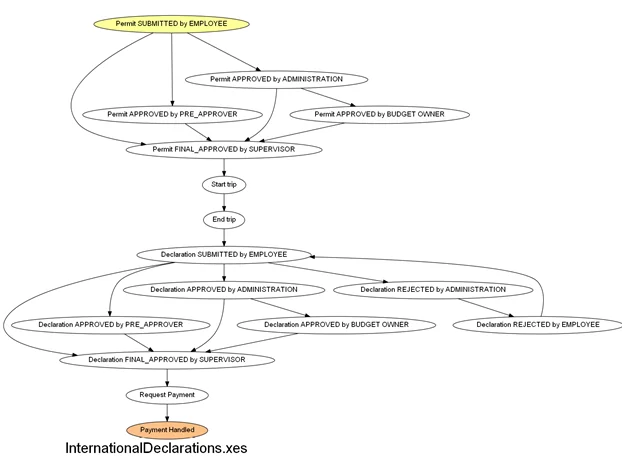
Пример графа, построенного по одному из логов соревнований BPIC2020, на котором отражены все кейсы и их события:
Попробовав множество инструментов для анализа процессов ни в одном из них, я не обнаружил удобный интерфейс для фильтрации логов. Этот функционал был частично реализован в библиотеке pm4py (python), но ни о каком графическом интерфейсе и речи не идет. Мне хотелось щелкать мышкой, выбирать варианты из выпадающих меню, а не писать код и перепроверять корректность введенных названий активностей. Опечатку можно не заметить, компилятор не выругается (т.к. ошибка в текстовой переменной), и граф будет построен неверно. А ты об этом и не знаешь:).
В myPM интерфейс позволяет наложить множество фильтров. На данный момент доступны следующие варианты:
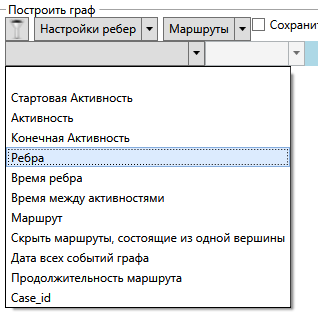
Применив фильтр по 5 самым популярным маршрутам, мы получим граф, с которым уже можно работать:
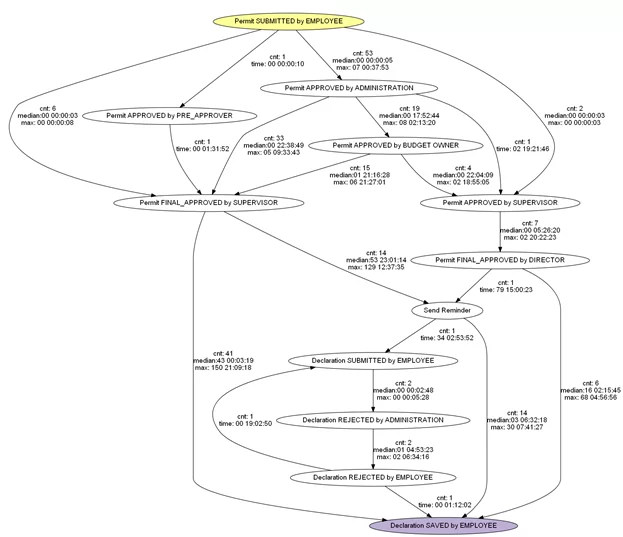
Или удалим активности start trip, end trip, установим фильтр по конечной активности и отобразим некоторые временные и количественные метрики:

Так выглядит добавление фильтров\модификаторов лога:
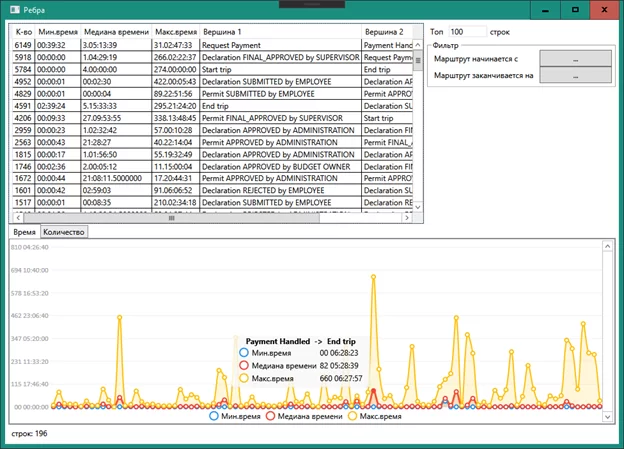
В окне «Ребра» можно увидеть список всех ребер и отклонения по времени перехода от одной вершины к другой:
myPM позволяет декомпозировать сложные для анализа задачи. Например, оставить только часть графа, находящуюся между определенными событиями. Этот блок можно сохранить в отдельный файл и обработать как самостоятельный лог. Или конвертировать *.XES фал лога в .CSV для загрузки в базу данных для ознакомления с данными через excel.
Все возможности myPM я перечислять не буду, а просто оставлю ссылку на исполняемый файл. Написано на C#. Для рендера графов понадобится GraphViz.
Исполняемые файлы myPM: https://github.com/Freem27/myPM
GraphViz: https://www2.graphviz.org/Packages/stable/windows/10/msbuild/Release/Win32/graphviz-2.44.1-win32.zip