/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)
Время прочтения: 8 мин.
При применении моделей машинного обучения, мы обычно делаем предварительную обработку данных, выделение признаков и выбор функций. После этого мы выбираем лучший алгоритм и настраиваем наши параметры для получения наилучших результатов. AutoML — это набор концепций и методов, используемых для автоматизации этих процессов.
Преимущества AutoML
Построение и применение моделей машинного обучения требует навыков программирования, предметной экспертизы и математического анализа. Найти эксперта со всеми этими навыками не всегда просто.
Фреймворки AutoML позволяют автоматизировать обработку сырых данных, самостоятельно определить задачу, которую нужно решить, выбрать модель машинного обучения, оптимизировать гиперпараметры алгоритма обучения, решить другие задачи, вплоть до визуализации.
AutoML позволяет уменьшить смещения и дисперсии, которые возникают, когда человек разрабатывает модели машинного обучения, а также, сокращает время, необходимое для разработки и тестирования модели машинного обучения.
Недостатки AutoML
AutoML — это довольно новая концепция в мире машинного обучения. Поэтому важно проявлять осторожность при применении некоторых современных решений.
Любые решения на AutoML являются весьма ресурсоемкими. Как правило, они требуют привлечения облачных вычислений, т.к. время их работы на локальных компьютерах достаточно велико.
Концепции AutoML
Что касается AutoML, необходимо освоить две основные концепции: поиск нейронной архитектуры и передача обучения.
Поиск нейронной архитектуры
Поиск нейронной архитектуры — это процесс автоматизации проектирования нейронных сетей. Для проектирования этих сетей используются обучающиеся или эволюционные алгоритмы. В обучении с подкреплением модели наказываются за низкую точность и вознаграждаются за высокую точность. Используя эту технику, модель всегда будет стремиться получить более высокую точность. Поиск нейронной архитектуры хорош для задач, требующих обнаружения новых архитектур.
Передача обучения
Трансферное обучение — это метод, в котором используются предварительно обученные модели для переноса того, что изучила модель, при применении к новому, но похожему набору данных. Это позволяет нам получить высокую точность, используя меньше времени и вычислительных мощностей. Трансферное обучение лучше всего подходит для задач, в которых наборы данных аналогичны тем, которые используются в моделях предварительного обучения.
Решения AutoML
Посмотрим на некоторые существующие решения, совместимые с языком Python.
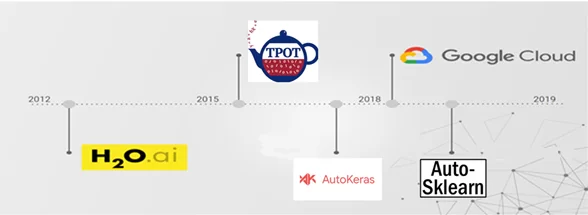
Все представленные продукты позволяют осуществлять выбор модели и поиск гиперпараметров, но каждый инструмент имеет свои особенности.
H20.ai
H2O — это платформа машинного обучения с открытым исходным кодом. Она доступна как на R, так и на Python. Этот пакет обеспечивает поддержку методов машинного обучения с использованием быстрых алгоритмов, и с 2018 года пакет получил поддержку глубокого обучения. На фоне популяризации Apache Spark, H2O обзавелся интерфейсом Sparkling Water для объединения возможностей Apache Spark и H2O. H20.ai является абсолютным лидером по скорости выполнения, но продукт дает относительно среднюю точность.
Инструмент оптимизации на основе дерева (TPOT)
Целью TPOT является автоматизация построения конвейеров ML путем объединения гибкого представления дерева конвейеров выражений с алгоритмами стохастического поиска, такими как генетическое программирование. TPOT использует основанную на Python библиотеку scikit-learn в качестве меню ML. Пакет не умеет взаимодействовать с естественным языком и категориальными признаками
https://github.com/EpistasisLab/tpot
AutoKeras
AutoKeras — это программная библиотека с открытым исходным кодом для автоматического машинного обучения. Она разработана DATA Lab из Техасского университета A & M и участниками сообщества. Конечная цель AutoML — предоставить легкодоступные инструменты глубокого обучения специалистам с ограниченным опытом в больших данных или машинном обучении. AutoKeras предоставляет функции для автоматического поиска архитектуры и гиперпараметров моделей глубокого обучения.
Cloud AutoML — Google Cloud
Cloud AutoML — это набор продуктов для машинного обучения, который позволяет разработчикам с ограниченным опытом в области ML, обучать высококачественные модели, соответствующие бизнес-потребностям, используя передовые технологии обучения Google и технологию поиска нейронной архитектуры. Как утверждают разработчики, готовое для промышленной эксплуатации решение можно получить в течение рабочего дня. Обладает простым пользовательским интерфейсом, и может использоваться бесплатно в течение года. Для коммерческих решений продукт является платным.
https://cloud.google.com/automl
Auto—Sklearn
Auto-Sklearn — это автоматизированный пакет машинного обучения, основанный на scikit-learn. Умеет генерировать признаки на основе сырых данных. Преимущества фреймворка в бейсовском языке оптимизации, метаобучение и ансамблевое построение. Эффективно работает только с небольшими дата сетами. По отзывам пользователей, Auto-Sklearn дает большую точность, но является самым медленным среди конкурентов.
https://automl.github.io/auto-sklearn/master/
Пример использования AutoML к реальным проблемам
Иногда в работе требуется распознавать на изображениях рукописные номера отсканированных договоров или квитанций, это можно осуществить путем классификации каждой цифры в номере.
Для решения этой задачи нужна максимальная точность, то есть корректное распознавание всех цифр, поэтому оставить всю работу AutoML нельзя. Но можно оценить точность, достигнутую при помощи тех или иных архитектур и весов, выбранных генетическими алгоритмами обучения, и использовать как основу для рабочей модели.
С подобными задачами классификации отлично справляется библиотека Keras, так как имеет мощный нейросетевой поиск параметров модели, поэтому пример будет реализован с помощью AutoKeras.
Для простоты воспроизведения, в примере использован открытый набор данных MNIST, содержащий рукописные цифры.
1.Установка AutoKeras
Первым шагом является установка AutoKeras в нашу среду исполнения. Я настоятельно рекомендую запустить следующий пример в Google Colab, если только вы не используете компьютер с высокой вычислительной мощностью.
pip install autokeras2.Импорт
Второй шаг — импортировать набор данных и библиотеку autokeras. Набор данных импортируется из tensorflow, тогда как классификатор изображений импортируется из AutoKeras.
import tensorflow as tf
from tensorflow.keras.datasets import mnist
import autokeras as ak3.Кросвалидация
Следующий шаг — разделение загруженных данных в тренировочный набор и тестовый наборы, как показано ниже:
(x_train, y_train), (x_test, y_test) = mnist.load_data()4. Обучение
Следующий шаг — классификация изображений.
- Инициализируем классификатор изображений с количеством испытаний 1.
clf = ak.ImageClassifier(max_trials=1) 2. Передаем классификатору данные для обучения, с количеством эпох = 1 для быстрой демонстрации работы AutoKeras.
clf.fit(x_train, y_train, epochs=1) 5. Перенос обучения
1.Сохраняем сгенерированную модель
model = clf.export_model()
print(type(model))
try:
model.save("model_autokeras", save_format="tf")
except:
model.save("model_autokeras.h5")2. Загружаем сохранённую модель
from tensorflow.keras.models import load_model
loaded_model = load_model("model_autokeras", custom_objects=ak.CUSTOM_OBJECTS)
predicted_y = loaded_model.predict(tf.expand_dims(x_test, -1))3.Оцениваем модель по количеству ошибок и потерь
loss,acc = loaded_model.evaluate(test_images, test_labels, verbose=2)
print("Restored model, accuracy: {:5.2f}%".format(100*acc))
6.Сравнение
Для сравнения результатов работы сгенерированной модели построена другая модель на основе примера кода для классификации набора данных MNIST с официального сайта Tensorflow.org:
from __future__ import absolute_import, division, print_function, unicode_literals
import os
import tensorflow as tf
from tensorflow import keras
(train_images, train_labels), (test_images, test_labels) = tf.keras.datasets.mnist.load_data()
train_labels = train_labels[:1000]
test_labels = test_labels[:1000]
train_images = train_images[:1000].reshape(-1, 28 * 28) / 255.0
test_images = test_images[:1000].reshape(-1, 28 * 28) / 255.0
def create_model():
model = tf.keras.models.Sequential([
keras.layers.Dense(512, activation='relu', input_shape=(784,)),
keras.layers.Dropout(0.2),
keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
return model
# Создадим экземпляр базовой модели
model = create_model()
# Сохраним контрольную точку
checkpoint_path = "training_1/cp.ckpt"
checkpoint_dir = os.path.dirname(checkpoint_path)
# Создаем коллбек сохраняющий веса модели
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_path, save_weights_only=True, verbose=1)
# Обучаем модель с новым коллбеком
model.fit(train_images,
train_labels,
epochs=10,
validation_data=(test_images,test_labels),
callbacks=[cp_callback]) # Pass callback to training
# Создадим экземпляр базовой модели
model2 = create_model()
# Оценим модель
loss, acc = model2.evaluate(test_images, test_labels, verbose=2)
print("Untrained model, accuracy: {:5.2f}%".format(100*acc))
# Загрузим веса
model2.load_weights(checkpoint_path)
# Оценим модель снова
loss,acc = model2.evaluate(test_images, test_labels, verbose=2)
print("Restored model, accuracy: {:5.2f}%".format(100*acc))
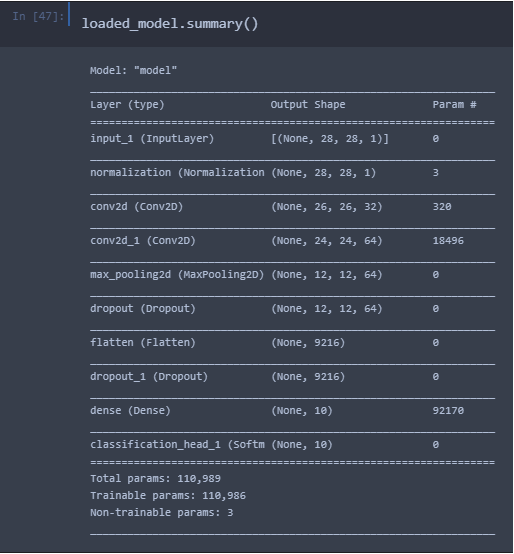
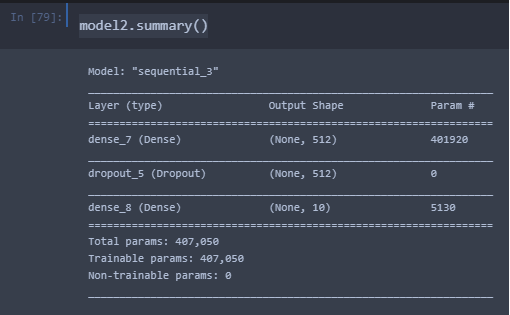
Результаты сравнения показали, что точность модели, сгенерированной в AutoKeras превосходит на 5 процентов модель, построенную человеком. В отчетах имеется информация какие слои и параметры были использованы при AutoML и «классическом» обучении. Точность сгенерированной модели достигнута благодаря использованию Conv2D, Flatten, MaxPooling2D слоев, и уменьшению количества обучающих параметров. Сгенерированная модель распознает рукописные цифры с точностью 91%, и может быть использована повторно при решении аналогичных задач без дополнительных манипуляций.
Отчет по сгенерированной модели AutoKeras
Отчет по построенной модели.
Использовать AutoKeras я рекомендую опытным ML-инженерам, которые могут правильно интерпретировать результаты работы моделей и видеть ошибки. AutoKeras все еще проходит финальное тестирование. Новичкам следует начинать свое знакомство с «классического» H2O.ai — эта платформа является одной из первых, имеет множество стабильных версий, качественную документацию. У компании H2O.ai есть продукт Driverless AI, автоматизирующий процесс создания признаков.
Все программные продукты, перечисленные в статье, находятся в стадии активной разработки и поддержки, и любой желающий может следить за их становлением или принимать личное участие в их развитии.