/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
При решении задачи оптимизации работы у нас возникла необходимость проведения анализа длительности процесса на основе логов. В настоящее время для решения аналогичных задач модно применять методы Process Mining. При анализе графа, отражающего реальные связи, следует учитывать, что события бизнес-процесса заполняются в информационной системе спустя произвольное время после выполнения и инструмент Process Mining дает искажённую картину происходящего. Поэтому мы решили подойти к снаряду нетрадиционно — применить альтернативные методы анализа логов.
Исходные данные для проведения анализа – датафрейм, полученный на основе логов процесса.
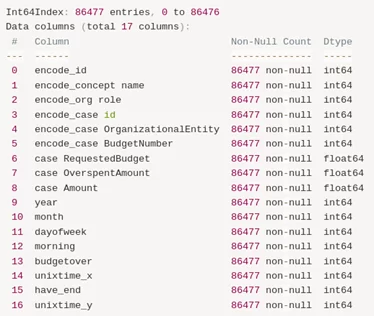
Проведя первичный анализ данных в Pandas, мы выявили, что уникальных событий по id 86477. Проведем «обогащение» данных — дополним даты годом, месяцем, днем недели и бинарным показателем — выходной/будний день.
После обработки и обогащения дополнительно проводим LabelEncoder нечисловых данных, что позволит нам в дальнейшем провести обучение моделей.
Итоговый датафрейм:
Анализ показывает, что по крайней мере все события закончились успешно — количество Start = End.
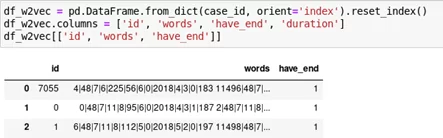
Всего у нас 7061 уникальных case id — т.е. каждый кейс — это упорядоченная во времени последовательность событий (количество событий внутри каждого кейса от 3 до 90). Одной из задач мы ставим предсказание длительности кейса исходя из того, какие события в него входят, при этом оценивать длительность отдельного события не целесообразно, т.к. событие имеет смысл только в рамках кейса и не интересно само по себе, и имеет смысл добавить к каждому событию признак — общая длительность кейса. Так же добавим бинарную переменную наличия в кейсе события, которое показывает окончание кейса. Данные переменные «unixtime_y» и «have_end» будут являться целью прогноза.
Для учета в кейсе порядка следования событий друг относительно друга рассматриваем кейс, как аналогию фразы, события при этом будут словами. Для того, чтобы снизить уникальность слов вещественные переменные, а также переменную даты, переведенную в формат времени UNIX «unixtime» мы разделим на периоды с помощью pd.cut, количество периодов примем равным ~10% от количества переменных. Для учета порядка событий внутри кейса служат величины полученных периодов переменной «unixtime» — каждое событие будет характеризоваться значением наборов переменных и периодом переменной «unixtime», в который попадает этот набор.
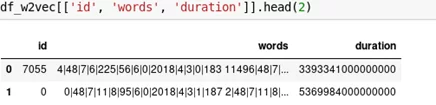
Сформируем train/test набор для обучения модели. Для этого проведем формирование «предложения» по каждому кейсу из «слов», которые сформируем как значение переменных события плюс значение периода переменной «unixtime». Итоговый датафрейм для модели классификации:
После проведения векторизации TfidfVectorizer разбиваем датасет на train/test выборки и проводим обучение на моделях LogisticRegression и LinearSVC. Полученный результат:

Далее, отработаем модель для предсказания длительности кейса – сформируем датафрейм для прогнозирования показателя длительности кейса:
После проведения векторизации TfidfVectorizer разбиваем датасет на train/test выборки и проводим обучение на модели SGDRegressor. Полученный результат с метрикой mean squared error:

В процессе альтернативных способов анализа данных при решении задачи Process Mining были реализованы пилотные методы оценки с помощью методов машинного обучения для прогнозирования категориальных и вещественных переменных. На основании полученных значений можно проводить оценку кейсов сильно выбивающихся из общей картины и манипулировать исходными данными для принятия решения об оптимизации конкретных этапов процесса.