/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 3 мин.
Для примера представим задачу:
После обработки информации по поиску нарушений на видео или скрин-снимках с видеорегистраторов необходимо срочно сформировать отчет, в котором на изображении будет виден момент нарушения, а рядом пояснения и дополнительная информация.
Имеем:
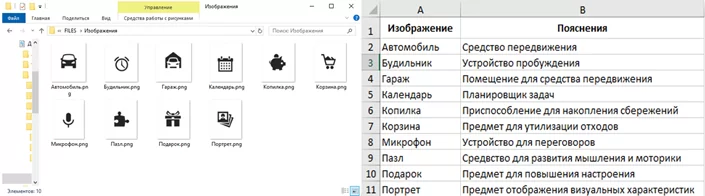
- папку, в которой располагаются необходимые изображения;
- excel-файл, в котором представлены идентификаторы изображений с пояснениями.
Полный код функции, а также вспомогательные материалы можно найти на github странице. Начнем с создания ipynb-файла в том же месте, где располагается папка с изображениями и Excel-файл. Для работы нам понадобятся только 2 библиотеки:
import pandas as pd
import osЗагрузим информацию с Excel-файла, а также имена файлов, которые располагаются в папке «Изображения»:
df = pd.read_excel('Пояснения.xlsx', encoding='utf8')
list_img = os.listdir('Изображения/')
Далее необходимо реализовать функцию, которая сформирует отчет в виде таблицы в .html-файле. Функция будет состоять из 3-х функциональных частей:
- начало: задаем заголовок и имена столбцов;
- тело документа: отображение изображений с пояснениями;
- конец: запись данных, формирование документа.
with open('Report.html', 'w') as f:
html_tags = \
"""
<!doctype html>
<html>
<head></head>
<body>
<h1>Отчет с изображениями и пояснениями</h1>
<style>
table {border-collapse: collapse;}
td, th {border: 5px solid #000; text-align: "center"; padding: 8px; font-size:24pt}
</style>
<table style='width:100%'; border='5'>
<tr>
<th>Изображение</th>
<th>Пояснения</th>
</tr>
"""
f.write(html_tags)С помощью данной конструкции создается html-файл с названием Report.html. Между тегами «h1» задается заголовок отчета. Между тегами «style» задаются параметры для форматирования таблицы и текста. Например, параметр «font-size» задает размер текста. Далее с помощью тегов «th» задаем количество и имена столбцов.
data = ''
for img in list_img:
path_to_img = 'Изображения/' + img
description = str(df[df['Изображение'] == img.strip('.png')]['Пояснения'].values[0])
data += '<tr>'
data += '<td align="center"><img src={0} width=600></td>'.format(path_to_img)
data += '<td align="center">{0}</td>'.format(description)
data += '<tr>'Данный блок создает переменную, в которой содержится информация о данных для отображения. Для каждой строки таблицы, формируется два значения, которые будут записываться в переменную data:
- path_to_img: путь к изображению;
- description: описание к изображению.
with open('Report.html', 'a') as f:
f.write(data)
html_tags = """
</table>
</body>
</html>
"""
f.write(html_tags)Последний блок функции записывает в .html-файл информацию о расположении изображения, а также его описание. Структура .html-файлов формируется за счет тегов (html, head, h1, body и т.д.), которые всегда записываются два раза, для каждого из значений или параметров. Для корректного вывода текст заголовка нужно поместить между тегами «h1» (открытие тега) и «/h1» (закрытие тега). Т.к. в первом блоке функции сформировали документ открытием тегов (html, body, table) в конце документа, то после записи информации необходимо закрыть указанные теги с помощью записи переменной html_tags.

После запуска функции, в папке где располагается ipynb-файл сформируется отчет с именем Report.html. Для его запуска можно воспользоваться любым интернет-браузером. Для корректной работы необходимо, чтобы папка с изображениями, excel-файл, ipynb-файл и Report.html располагались в одной директории.