/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
Немного о соревновании
Но сперва немного предыстории. К моменту запуска COVID-19 Data Challenge[3], на платформе Kaggle.com уже во всю проходили аналогичные соревнования. Участники использовали самые разные методы (деревья, ARIMA модели, SARS и т.д.), проверяли гипотезы, делились инсайтами и т.д., тем самым создавая огромный пласт информации для анализа.
Отдельно хотелось бы остановится на огромном количестве признаков, связанных с демографическими показателями (численность населения, плотность, показатели миграции и многие, многие другие), климатическими (скорость ветра, влажность и т.д.) и другими, которые многие участники пытались использовать, и почему, в моем представлении, это не совсем верно.
Несмотря на то, что такие показатели очевидно должны влиять на поведение вируса, в «сыром» виде для методов машинного обучения они оказываются почти, а иногда и совершенно бесполезными.
Допустим, для страны A, у нас есть данные по числу заболевших (целевая переменная Y) за периоды
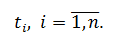
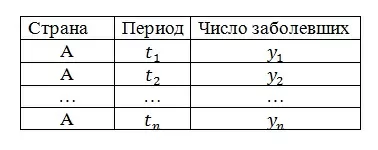
Теперь добавим к нашим данным два признака: Х1 (например, численность населения) и X2 (например, плотность населения). Т.к. эти показатели остаются неизменными для любого разумного (в рамках соревнования, конечно) числа периодов N, получим следующую картину:
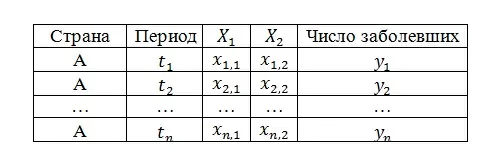
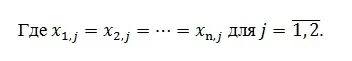
То есть, на самом деле наши данные выглядят следующим образом:
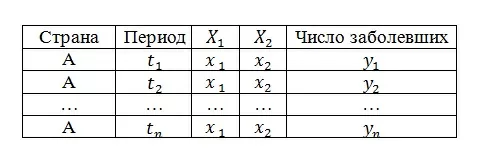
Конечно, это можно обобщить для числа признаков M.
Что мы имеем? Имеем, во-первых, признаки, которые невариативны (по крайней мере в рамках одной страны), а во-вторых – линейно зависимы, что для «деревьев» возможно и не является критичным (хотя все равно излишне захламляет данные), а вот оценки коэффициентов линейных моделей становятся «неадекватными».
Для случая нескольких стран, первая проблема в каком-то смысле решается, признаки становятся вариативными, хотя все так же линейно зависимы. Что важнее, эти признаки приобретают новую интерпретацию, они позволяют отличить одну страну/регион от другой/другого.
Но при этом едва ли найдется такой признак, который один сможет «отличить» страны с приемлемым качеством, возникает необходимость в некоем интегральном показателе или показателях. Эта задача в свою очередь решается методами кластеризации и/или понижения размерности.
В общем, использовать такие признаки, значение которых постоянно в течение периода много большего соответствующего периода для целевой переменной, следует по крайней мере учитывая изложенное выше. Или можно их не использовать.
Судя по публичным решениям (в т.ч. и на каггловских соревнованиях) и обсуждениям в slack’е ods.ai, самыми полезными признаками в результате оказались лаговые переменные, что логично.
Довольно полезным приемом оказалось преобразование целевой переменной (переход от общего числа случаев по состоянию на дату к приростам), как раз он был использован в моем решении.
Насколько я знаю, у участников победителей соревнования были так же довольно хитрые идеи, вроде создания отдельных моделей для прогноза на каждый из дней недели и т.п. Для подробного ознакомления рекомендую пролистать канал соревнования в slack’е (вся инф-я на сайте соревнования) [3].
Подробнее о решении и DSANet
Основная особенность этого решения, как мне кажется, в том, что оно не громоздко. В нем не используются блендинги/стекинги, нет хитрой предобработки признаков и не подгружается большой объем дополнительных данных.
По сути, единственное преобразование – это описанное в предыдущем разделе (преобразование цел. переменной). Дальше модель обучается на данных в течение 10-15 минут (обучение проходило на GPU от Kaggle.com) и на этом все.
DSANet была как раз создана для задач прогнозирования многомерных временных рядов. По словам авторов, их сеть сохраняет в себе все достоинства LSTM и GRU, т.е. она способна находить долгосрочные нелинейные зависимости и при этом показывает лучшие результаты.
Далее попытаюсь максимально кратко описать устройство сети, для более подробного изложения рекомендую обратиться к оригинальной статье.[1]
Ниже представлена архитектура сети.
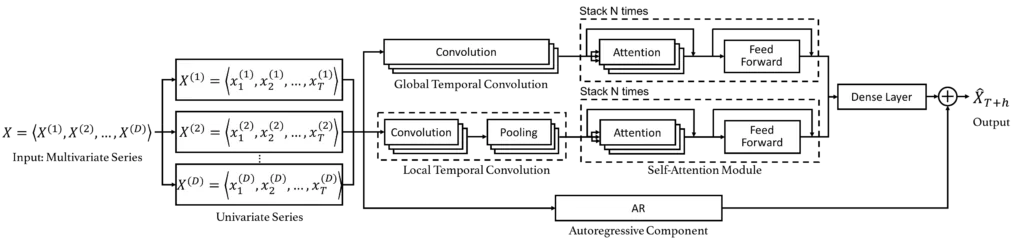
На вход сеть получает многомерный временной ряд X размерности DxT, где D это число временных рядов, а T это число наблюдений в каждом из них.
Далее сеть пытается восстановить закономерность внутри этих временных рядов и спрогнозировать h (от horizon – горизонт прогнозирования) следующих значений для каждого из них.
Собственно, выше обозначены два основных гиперпараметра, которые я регулировал – длина ряда T, который так же мы называем окном (window), и h.
Далее обратим внимание на два блока – Global Temporal Convolution (GTC) и Local Temporal Convolution (LTC). Их роль заключается в преобразовании исходных рядов в некоторые их представления, причем разница в том, что GTC делает преобразование из целого ряда длины T, а LTC из части ряда l < T, таким образом LTC учитывает относительно более «близкие», а значит, и сильнее влияющие друг на друга периоды
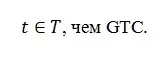
Далее, в обоих случаях следуют Self-Attention блоки, в которых и происходит поиск закономерностей.
После следует полносвязный слой (Dense), который комбинирует два предыдущих блока.
Из этого слоя авторы получили предсказания основанные на Self-Attention блоках, а уже путем добавления к ним предсказаний авторегрессионной составляющей (AR) и получается финальное предсказание самой сети DSANet.
В статье авторы также проверили собственные замеры точности сети. [1]
Итог
Решение, полученное с помощью этой сети заняло 8-е место в 3-м этапе [4] соревнования, при этом, повторюсь, удалось избежать многих вычислительно затратных и неэффективных приемов.
Источники: