/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 8 мин.
Процесс работы DS команд во многом напоминает опыт их коллег из сферы разработки ПО. Ключевым отличием именно работы именно с ML задачами является цикл проектирования модели. На этом этапе проводится огромное количество экспериментов, вносятся изменения в параметры и в формат входных данных.
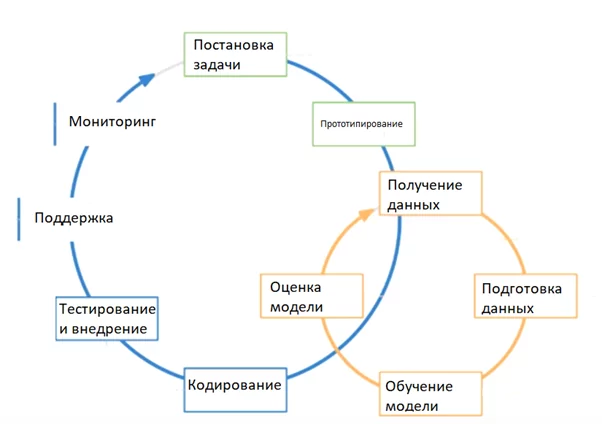
И зачастую, в процессе работы создаётся несколько (десятков) различных моделей, среди которых нужно выбрать одну или две с которыми имеет смысл продолжать работать. При этом эти модели могут отличаться не только параметрами алгоритма, но и предобработкой данных, форматом вывода и ввода и т.д. Помимо очевидной путаницы во всех этих данных для одного разработчика — это также создает значимые препятствия для совместной работы, усложняя процесс обмена промежуточными результатами и наработками.
В этой статье я хочу рассказать о двух инструментах, позволяющих в значительной мере упростить и автоматизировать процесс проектирования модели. В качестве примера возьмем небольшой датасет с Kaggle содержащий информацию об аудите 700 фирм. Ознакомится и скачать датасет можно по ссылке.
В тексте будет часто встречаться понятие “пайплайн”. Под этим термином подразумевается совокупность алгоритмов и методов, применяемых к данным для получения результата. К примеру, пайплайн может состоять из:
- ETL (Extract Transform Load — получение и первичная обработка данных),
- Feature selection и Feature Engineering (отбор и создание новых признаков),
- Обучение модели
- Расчет метрик
Мы будем работать с DVC и MLFlow. Установить их можно через pip:
pip install DVC, mlflowDVC (Data Version Control) это инструмент, позволяющий отслеживать изменения в данных и разрабатываемых моделях, обмениваться ими с другими членами команды и строить пайплайны для обработки этих данных.
Для полноценного функционирования DVC необходим установленный Git (система контроля версий)
MLFlow это платформа для контроля всего жизненного цикла ML модели. При помощи различных инструментов из MLFlow мы можем эффективно проводить эксперименты с моделями и сравнивать их результаты, а также “упаковывать” модели в формат, удобный для дальнейшего внедрения.
Итак, в этом проекте мы настроим версионирование для наших данных и результатов работы, обучим модель, фиксируя результаты при помощи MLFlow и на основе всего этого создадим пайплайн.
Создадим папку для проекта и инициализируем Git и DVC. Для этого откроем консоль, перейдём в папку проекта и выполним:
1. git init
2. dvc init
3. git commit -m "Initialize DVC project"
Создадим новую папку data, и добавим туда наши данные. Зафиксируем это в Git и DVC:
1. dvc add data/audit_data.csv
2. git add data
3. git commit -m "Add raw data to project"
В результате создастся файл audit_data.csv.DVC, который хранит в себе текущее состояние файла audit_data.csv. При помощи этого файла DVC отслеживает изменения данных и в случае, если появится необходимость перенести проект на другой компьютер (например, на рабочую станцию коллеги) позволит загрузить нужные данные из удаленного хранилища.
Создадим простой скрипт для подготовки датасета. К примеру, закодируем некоторые категориальные переменные при помощи One-Hot-Encoding и удалим ненужные столбцы:
1. import pandas as pd
2.
3.
4. def feature_generation(data_path):
5. df = pd.read_csv(data_path)
6. df = df.drop('LOCATION_ID', axis=1)
7. district_loss_onehot = pd.get_dummies(df['District_Loss'], prefix='District_Loss')
8. history_onehot = pd.get_dummies(df['History'], prefix='History')
9. df.drop(['District_Loss', 'History', 'Audit_Risk', 'Inherent_Risk', 'CONTROL_RISK', 'Score', 'TOTAL'],
10. axis=1, inplace=True)
11. df[district_loss_onehot.columns] = district_loss_onehot
12. df[history_onehot.columns] = history_onehot
13. return df
14.
15.
16. if __name__ == '__main__':
17. df = feature_generation('data/audit_data.csv')
18. df.to_csv('data/feature_generated.csv', index=False)
Теперь можно создать DVC пайплайн, который поможет перезапускать вычисления при изменении входных данных. Для этого выполним команду (нужно писать в одну строку):
1. dvc run
2. -f feature_generation.DVC
3. -d feature_generation.py
4. -d data/audit_data.csv
5. -o data/feature_generated.csv
6. python feature_generation.py
Рассмотрим эту команду подробнее. В строке 2 (с флагом -f) задаётся имя .dvc файла, в котором будет хранится информация о создаваемом пайплайне. Строки 3 и 4 (флаг -d) определяют входные данные и зависимости, используемые в пайплайне. Таким образом мы говорим DVC отслеживать изменения этих файлов. Строка 5 (флаг -o) указывает на выходной файл пайплайна. И наконец в строке 6 указана конкретная выполняемая команда (в данном случае запуск выполнения файла feature_generated.py).
Обучим небольшую модель на основе новых данных. А параллельно поговорим о втором инструменте, который поможет отслеживать наши эксперименты с данными и алгоритмами. Создадим файл model_train.py:
from sklearn.metrics import accuracy_score, roc_auc_score
2. from catboost import CatBoostClassifier
3. from sklearn.model_selection import train_test_split
4. import pandas as pd
5. import mlflow
6.
7. mlflow.set_tag('model_type', 'catboost')
8.
9. iterations = 10
10. mlflow.log_param('iterations', iterations)
11.
12. data = pd.read_csv('data/feature_generated.csv')
13. X, y = data.drop('Risk', axis=1), data['Risk']
14. X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
15.
16. params = {'n_estimators': 1, 'learning_rate': 0.01, 'depth': 3}
17. mlflow.log_params(params)
18. model = CatBoostClassifier(**params)
19.
20. for iter in range(iterations):
21. if model.is_fitted():
22. model.fit(X_train, y_train, init_model=model)
23. else:
24. model.fit(X_train, y_train)
25. predicted_train = model.predict(X_train)
26. predicted_test = model.predict(X_test)
27. mlflow.log_metric('Accuracy Train', accuracy_score(y_train, predicted_train), step=iter*params['n_estimators'])
28. mlflow.log_metric('Accuracy Test', accuracy_score(y_test, predicted_test), step=iter*params['n_estimators'])
29. mlflow.log_metric('ROC AUC Train', roc_auc_score(y_train, predicted_train), step=iter * params['n_estimators'])
30. mlflow.log_metric('ROC AUT Test', roc_auc_score(y_test, predicted_test), step=iter * params['n_estimators'])
31.
32. model.save_model('catboostmodel.cbm')
33. mlflow.log_artifact('catboostmodel.cbm')
В этом скрипте мы обучаем CatBoost предсказывать значение поля “Risk”. Сам процесс обучения происходит в цикле на строках 20-30. В использовании градиентного бустинга никаких особенностей нет, поэтому сразу переключимся на более интересные вещи. А именно использование MLFlow.
Начнём с того, что запустим графический интерфейс. Для этого в консоли выполним:
mlflow uiИ перейдем по появившейся в консоли ссылке.
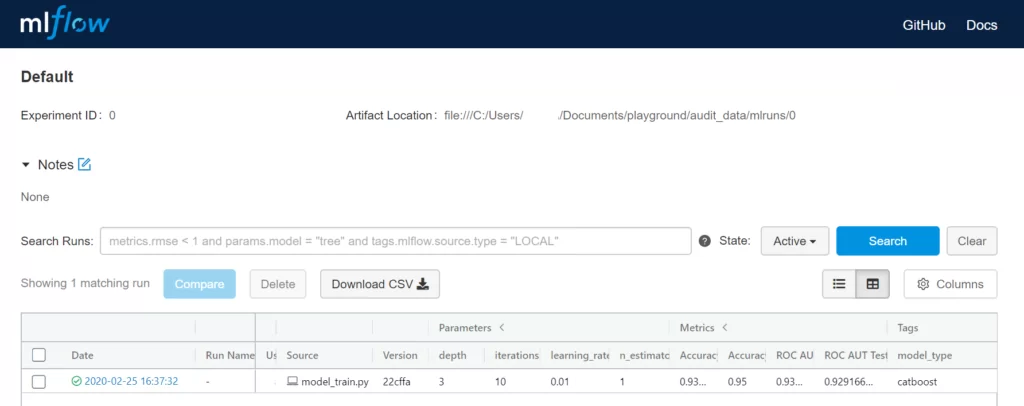
В самом низу страницы мы видим таблицу с информацией об экспериментах. Приведена информация о дате и времени запуска, результате работы, имени эксперимента, пользователе, файле скрипта и его версии, параметры, метрики и теги. Нажав на отдельный эксперимент открывается новое окно с информацией о конкретном эксперименте. Если нажать на метрику в окне эксперимента, откроется настраиваемый график изменения этой метрики в процессе обучения модели.
Вся эта информация записывается MLFlow при помощи вызова специальных функций:
- mlflow.set_tag В строке 7. Позволяет фиксировать параметры запуска. Представляет собой связь двух строк — ключа и значения (в данном случае ключу ‘model_type’ соответствует значение ‘catboost’). Теги могут быть полезны, для сохранения коротких описаний эксперимента, к примеру, типа используемой модели.
- mlflow.log_param и mlflow.log_params В строках 7 и 17. Позволяет фиксировать числовые параметры, такие как количество эпох или learning rate.
- mlflow.log_metric В строках 27-30. Позволяет фиксировать значения метрик во время обучения.
- mlflow.log_artifact В строке 33. Позволяет фиксировать различные файлы, которые являются результатом работы модели (к примеру, сохранённые модели или файлы данных)
Главным достоинством MLFlow является возможность сравнения экспериментов. Однако сейчас у нас есть только один. Исправим это, но для начала создадим новый пайплайн в DVC на основе model_train.py.
1. dvc run
2. -f model_train.DVC
3. -d model_train.py
4. -d data/feature_generated.csv
5. -o catboostmodel.cbm
6. python model_train.py
Заметим, что новый пайплайн зависит от данных, порождаемых предыдущим. И именно это и есть основное преимущество использования DVC пайплайнов!

При создании пайплайнов, DVC строит граф вычислений (DAG), по которому можно перезапускать вычисление части или всего пайплайна целиком.
Ради эксперимента немного поменяем значение в первой строке файла audit_data.csv. Сохраним файл и выполняем:
dvc repro model_train.DVC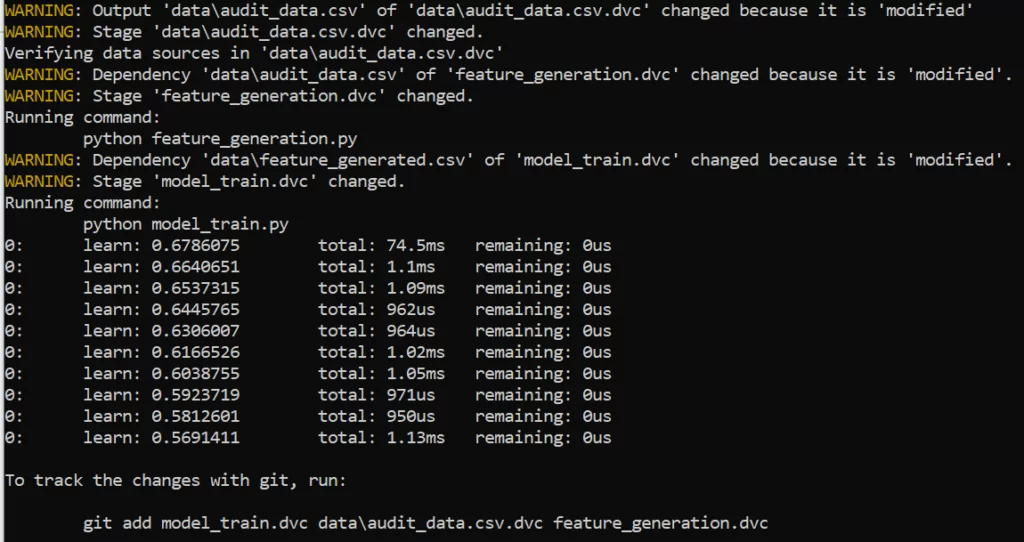
И наконец попробуем действительно сравнить друг с другом два эксперимента. Для этого поменяем параметры модели на {‘n_estimators’: 1, ‘learning_rate’: 0.1, ‘depth’: 12} и установим количество итераций равным 20 (вместо 10). Ещё раз запустим весь пайплайн при помощи
dvc repro model_train.dvc и перейдём в интерфейс MLFlow.

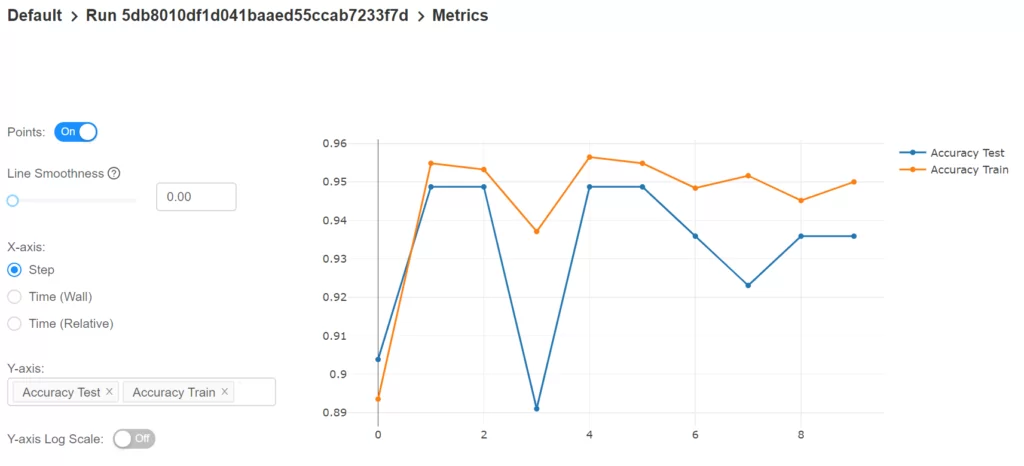
Выделим последние два эксперимента и кликнем на кнопку Compare. На открывшейся странице приведена таблица сравнения параметров и метрик выбранных экспериментов. Кликнув на метрику можно увидеть график изменения этой метрики в процессе обучения для каждого из экспериментов. И в самом низу страницы расположен настраиваемый график для сравнения результатов экспериментов. К примеру, можно вывести график в осях ROC AUC и Accuracy на тестовой выборке:
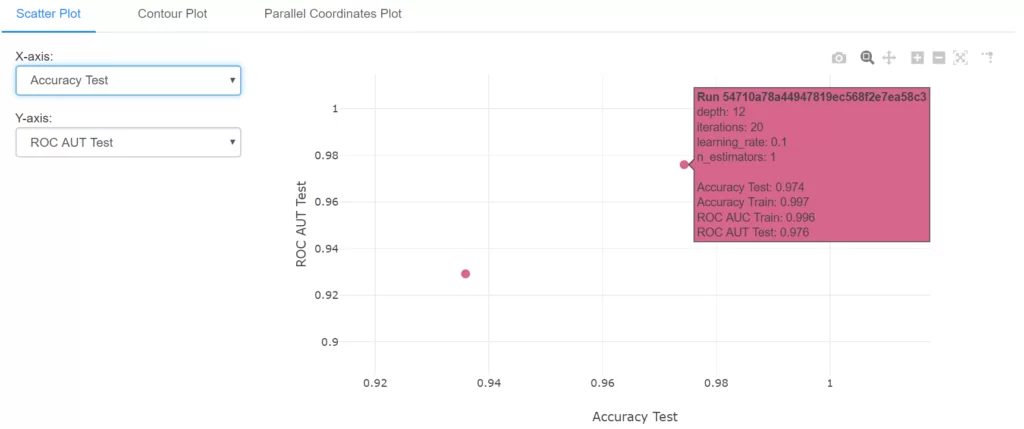
Всё это — самые базовые функции DVC и MLFlow. Однако используя даже эти возможности можно во многом оптимизировать и упростить процесс разработки ML-моделей. Контроль версий файлов данных и создание пайплайнов уменьшает рутинную работу, позволяет настроить перерасчёт ресурсов при добавлении или изменении входной информации. Всё это помогает избежать ошибок и освобождает время для более сложных и важных задач. А возможность удобно отслеживать, хранить и анализировать результаты экспериментов помогает не запутаться в десятках вариантов и выбрать среди них наиболее подходящий.