/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
1. Нехватка памяти при чтении очень больших файлов
Предположим, нам необходимо найти соответствия регулярному выражению в строках CSV файла. В этом случае нам может помочь оператор yield return.
Этот оператор позволяет генерировать перечислимые коллекции элементов для их перебора в цикле. Его особенностью является то, что для перебора таких коллекций нам не нужно заранее хранить все их элементы в оперативной памяти компьютера. Это полезно, если заранее неизвестен размер обрабатываемого файла. Ниже приведён пример обработки csv-файла. Метод-генератор AllLinesFromFile (string a_file_path) принимает на вход путь к файлу и возвращает итератор, указывающий на текущий объект коллекции – связный список, состоящий не более, чем из ста строк файла. При этом в памяти одновременно будет находиться только один элемент коллекции. Таким образом, мы можем обрабатывать файл частями, не загружая его полностью в оперативную память.
// param a_file_path - путь к csv файлу
private static IEnumerable<LinkedList<string>> AllLinesFromFile(string a_file_path)
{
LinkedList<string> Lines = new LinkedList<string>();
using (StreamReader r = new StreamReader(a_file_path))
{
int count = 0;
while (r.EndOfStream != true)
{
Lines.AddLast(r.ReadLine());
count++;
if (count == 100)
{
count = 0;
yield return Lines;
// Удаление текущих узлов списка перед заполнением следующей порцией строк
Lines.Clear();
}
}
if(count > 0 && count <= 100)
{
yield return Lines;
}
}
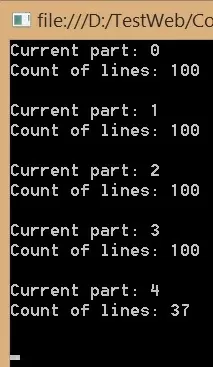
}Теперь продемонстрируем в методе Main() использование написанного выше генератора коллекции для чтения csv файла, состоящего из 437 строк:
static void Main(string[] args)
{
string FilePath = @"C:\Users\User1\test.csv";
int current_part = 0;
foreach(LinkedList<string> LinesPart in AllLinesFromFile(FilePath))
{
/* В теле цикла мы можем обрабатывать текущую порцию строк */
Console.WriteLine("Current part: " + current_part);
Console.WriteLine("Count of lines: " + LinesPart.Count);
Console.WriteLine("");
current_part++;
}
Console.ReadKey();
}
Примечания
- Размер возвращаемой “порции строк” взят не более ста исключительно для примера. На практике выбор этого значения должен быть обусловлен системными требованиями к потреблению памяти приложением.
- Показанный способ чтения текста из файлов подходит для простых форматов (.txt или .csv). Для чтения более сложных форматов, например JSON или XML, может дополнительно понадобиться использование соответствующего парсера.
- В качестве типа возвращаемого элемента коллекции (на который указывает итератор) метод AllLinesFromFile (string a_file_path) использует связный список строк, что также поможет избежать возможных проблем с выделением непрерывной области памяти (если бы использовался массив).
- Подробнее про оператор yield return в C# можно почитать на официальном сайте Microsoft (https://docs.microsoft.com/ru-ru/dotnet/csharp/language-reference/keywords/yield).
- Оператор yield есть не только в языке C#, но и во многих других языках программирования, например Python, JavaScript, PHP и др.
2. Использование LINQ и PLINQ
Платформа .NET содержит много полезных встроенных библиотек, в том числе и для работы с данными. Например, LINQ (Language-Integrated Query) и PLINQ (Parallel LINQ). Эти технологии позволяют совершать разработчику запросы к различным данным (коллекциям C#, БД, XML файлам и др.), используя универсальный язык.
Остановимся именно на использовании PLINQ. Данный инструмент является параллельной реализацией LINQ и может использоваться при работе с коллекциями C#. При применении запроса к элементам коллекции он будет автоматически распараллеливаться (при условии, что это поможет ускорить выполнение запроса), разбивая коллекцию на сегменты, каждый из которых будет обрабатываться в отдельном потоке. Деление осуществляется, исходя из доступных системных ресурсов. Например, нам необходимо найти все файлы с указанными расширениями в папке и всех её дочерних папках. Можно написать рекурсивный алгоритм, который бы последовательно перебрал все необходимые папки с файлами. Но с помощью библиотеки PLINQ можно выполнить эту операцию параллельно:
static void Main(string[] args)
{
string[] SearchPatterns = new string[6] {"*.csv", "*.txt", "*.xls", "*.xlsx", "*.doc", "*.docx" };
string InitialPath = @"C:\Users\User1\Downloads\";
// Перебор всех файлов с указанными расширениями в папке и всех её дочерних папках
foreach(string FilePath in SearchPatterns.AsParallel().
SelectMany(SearchPattern => Directory.EnumerateFiles(InitialPath,
SearchPattern,
SearchOption.AllDirectories)))
{
/* Обработка файла */
}
Console.ReadKey();
}Примечания
- C помощью метода AsParallel() массив расширений файлов SearchPatterns разбивается на части, каждая из которых обрабатывается в отдельном потоке.
- В свою очередь, для каждой из полученных частей выполняется запрос LINQ (метод SelectMany()), запускающий метод EnumerateFiles() для поиска файлов с нужным расширением.
- Метод Directory.EnumerateFiles() находит нужные файлы и возвращает пути к ним с помощью оператора yield return (что полезно в случае, когда неизвестно заранее, сколько файлов будет удовлетворять условиям поиска).