/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 15 мин.
Анализ социальных сетей – это процесс исследования различных систем с использованием теории сетей. Он начал широко применяться именно тогда, когда стало понятно, что огромное количество существующих сетей (социальных, экономических, биологических) обладают универсальными свойствами: изучив один тип, можно понять структуру и любых других сетей и научиться делать предсказания по ним.
Любые сети состоят из отдельных участников (людей или вещей в сети) и отношений между ними. Сети очень часто визуализируются с помощью графов – структур, состоящих из множества точек и линий, отображающих связи между этими точками. Участники представлены в виде узлов сети, а их отношения представлены в виде линий, их связывающих. Такая визуализация помогает получить качественную и количественную оценку сетей:
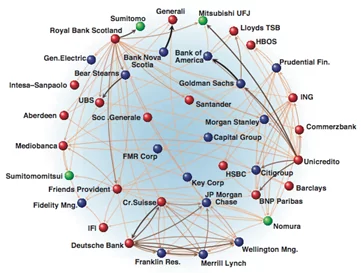
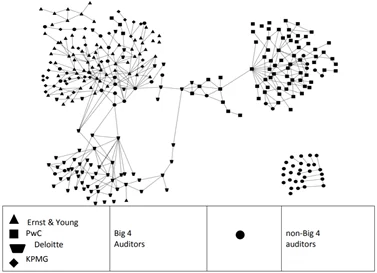
С помощью анализа социальных сетей можно проанализировать самые разные взаимодействия и процессы обмена ресурсами, как материальными, так и информационными. Например, проанализировав сеть транзакций между клиентами банка (где узлами являются клиенты банка, а рёбрами – переводы между ними), можно определить круг лиц, вовлечённых в мошеннические операции, или выявить нарушения внутренних регламентов сотрудниками банка.
Также можно построить сеть рабочих взаимоотношений (на примере различных типов коммуникаций между сотрудниками), которая может помочь в понимании социальной структуры организации и позиции каждого сотрудника в этой структуре. При наличии данных о типе коммуникации для каждого работника можно даже проанализировать, как такие характеристики как лидерство, наставничество и сотрудничество влияют на его карьеру, а на основе полученных знаний определить карьерные цели и предложить учебные программы для их достижения.
Кроме того, на примере сетей можно и прогнозировать события. К примеру, существуют модели, которые оценивают вероятность сбоя программного обеспечения, некоторые из них рассматривают людей как источник для прогнозов – ведь именно люди разрабатывают и тестируют продукты до релиза. Их взаимодействия образуют сеть: можно представить разработчиков как узлы, а то, работали ли они вместе над одним и тем же файлом в рамках одного релиза, как рёбра сети. Понимание взаимодействий и информация о ранее произошедших сбоях позволит многое сказать о надёжности конечного продукта и укажет на файлы, в которых риск сбоя наиболее вероятен.
Теперь попробуем применить анализ социальных сетей на практике. Для этого мы будем использовать язык программирования Python, а точнее библиотеку networkx, предназначенную для работы с графами, библиотеку matplotlib для визуализации и библиотеку community для выделения сообществ внутри сети. Давайте их импортируем:
1. import community
2. import networkx as nx
3. import matplotlib.cm as cm
4. import matplotlib.pyplot as plt- Импорт данных и преобразование их в граф
В качестве датасета возьмём переписку посредством электронной почты от крупного европейского университета, где содержится анонимная информация обо всех входящих и исходящих электронных сообщениях между членами исследовательского учреждения (ссылка). Датасет содержит файл формата txt, где на каждой строке перечисляются пары узлов, которые связаны друг с другом.
1. G = nx.read_edgelist('email-Eu-core.txt', create_using=nx.DiGraph())
2. print('Количество вершин: {}'.format(G.number_of_nodes()))
3. print('Количество рёбер: {}'.format(G. number_of_edges()))
4. print(' Среднее количество соседей у узлов в графе: {}'.format(round(G.number_of_edges() / float(G.number_of_nodes()), 4)))
Количество вершин: 1005
Количество рёбер: 25571
Среднее количество соседей у узлов в графе: 25.4438В приведённом выше коде датасет был импортирован и преобразован в граф. Затем мы последовательно вывели основные параметры графа: количество узлов, рёбер и среднее количество соседей у узлов в графе. Последний параметр отражает, насколько тесно связаны узлы между собой.
- Основные характеристики графов
Для того чтобы понять, как можно работать с каждым конкретным графом, вначале нужно понять, как он устроен. Давайте кратко рассмотрим характеристики, с помощью которых можно понять структуру графа.
Прежде всего рассмотрим понятия связности и направленности. Граф называется связным, если каждая пара узлов графа связана между собой, т.е. из любого узла можно прийти в любой другой узел. Если же граф несвязный, то его можно разбить на максимально связные подграфы (называемые компонентами). Также графы могут быть направленными и ненаправленными. Это определяется наличием направленности связей между двумя участниками. Одним из примеров направленной сети являются транзакции между клиентами банка, где у каждого клиента могут быть как входящие, так и исходящие платежи.
В общем случае в направленных графах связи не взаимны, поэтому для направленных графов вместо понятия связности выделяют понятия компоненты слабой и сильной связности. Компонента считается слабо связной, если при игнорировании направления получается связный граф. Компонента сильной связности может быть таковой, если все её вершины взаимно достижимы. Давайте посмотрим, какой структурой обладает граф из нашего датасета с электронной перепиской:
1. if nx.is_directed(G):
2. if nx.is_weakly_connected(G):
3. print('Граф является направленным и состоит из одной компоненты слабой связности.')
4. else:
5. print('Граф является направленным и состоит из нескольких компонент.')
6. else:
7. if nx.is_connected(G):
8. print('Граф является ненаправленным и связным.')
9. else:
10. print('Граф является ненаправленным и состоит из нескольких компонент.')Граф является направленным и состоит из нескольких компонент.
Здесь мы провели проверку на направленность и связность графа и выяснили, что граф из датасета является направленным и содержит несколько несвязных компонент. Давайте попробуем посмотреть поближе на самые крупные компоненты сильной и слабой связности:
1. G_weak = G.subgraph(max(nx.weakly_connected_components(G), key=len))
2. print('Количество вершин: {}'.format(G_weak.number_of_nodes()))
3. print('Количество рёбер: {}'.format(G_weak.number_of_edges()))
4. print('Среднее количество соседей у узла в графе: {}'.format(round(G_weak.number_of_edges() / float(G_weak.number_of_nodes()), 4)))
5.
6. G_strong = G.subgraph(max(nx.strongly_connected_components(G), key=len))
7. print('Количество вершин: {}'.format(G_strong.number_of_nodes()))
8. print('Количество рёбер: {}'.format(G_strong.number_of_edges()))
9. print('Среднее количество соседей у узла в графе: {}'.format(round(G_strong.number_of_edges() / float(G_strong.number_of_nodes()), 4)))
Количество вершин: 986
Количество рёбер: 25552
Среднее количество соседей у узла в графе: 25.9148
Количество вершин: 803
Количество рёбер: 24729
Среднее количество соседей у узла в графе: 30.7958Итак, мы получили основные характеристики для компоненты слабой связности и для входящей в неё компоненты сильной связности. Давайте посмотрим, какие выводы мы можем сделать на этом этапе. Мы видим, что из 1005 участников друг с другом общаются 986 человек, при этом 183 человека из них отправляли электронные письма другим людям в одностороннем порядке, и только 803 человека поддерживали двустороннее общение. В 823 случаях попытка наладить коммуникацию посредством электронной почты оказалась провальной. Также мы видим, что наиболее активные участники (входящие в компоненту сильной связности) поддерживают коммуникацию в среднем с 30 людьми.
Давайте рассмотрим и другие ключевые характеристики графов, определяющие их структуру. Графы считаются взвешенными, если отношения между узлами отражают не только само наличие связи, но и определённый вес, отражающий силу этой связи. Наш датасет с электронными сообщениями взвешенным не является, поскольку в нём учитывается только факт наличия переписки, но не количество отправленных писем.
Кроме того, узлы и связи могут создавать различные типы сетей: однодольные, двудольные или многоуровневые. Однодольные сети состоят из одного типа участников и связей между ними. Двудольные сети состоят из двух разных типов участников, где один из типов узлов связан только с другим типом. Многоуровневые сети также включают два типа участников, однако связи могут соединять как участников разных типов, так и однотипных участников (например, отношения между менеджерами и отношения между проектами). Взятый нами для исследования датасет представляет собой сеть однодольного типа, так как состоит только из одного типа участников и связей между ними.
- Визуализация графа
А теперь давайте попробуем визуализировать взятый нами датасет. Для этого нам понадобится библиотека matplotlib, уже импортированная нами выше:
1. plt.figure(figsize=(15, 15))
2. plt.title('E-mails')
3. nx.draw(G, node_size=5)
4. plt.show()В первой строке задаётся размер будущего изображения, которому затем присваивается определённое название. В третьей строке функции draw передаётся граф и указывается размер узлов, после чего граф выводится на экран. Давайте на него посмотрим:
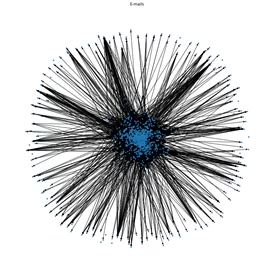
На получившемся графе мы видим, что существует ряд точек, не связанных с остальными участниками коммуникации. Эти люди, не связанные с остальными участниками, попали на граф, поскольку отправляли письма исключительно сами себе. Также можно заметить, что на периферии расположен ряд точек, которые связаны с остальным графом немногочисленными входящими связями, – это участники, которые попали в компоненту слабой связности для нашего графа, но не попали в компоненту сильной связности.
Давайте также рассмотрим граф, иллюстрирующий компоненту сильной связности – людей, которые поддерживают двустороннюю коммуникацию с другими участниками исследовательского учреждения:

- Степень узла и распределение степеней узлов
Теперь, когда мы знаем структуру нашего графа и умеем его визуализировать, давайте перейдём к более детальному анализу. У каждого узла в графе есть степень – количество ближайших соседей этого узла. В направленных сетях можно различать как степень входа (количество входящих связей с узлом), так и степень выхода (количество исходящих связей с узла). Если для каждого узла графа посчитать степень, можно определить распределение степеней узлов. Давайте посмотрим на него для графа с электронной перепиской:
1. degree = dict(G.degree())
2. degree_values = sorted(set(degree.values()))
3. hist = [list(degree.values()).count(x) for x in degree_values]
4. plt.figure(figsize=(10, 10))
5. plt.plot(degree_values, hist, 'ro-')
6. plt.legend(['Degree'])
7. plt.xlabel('Degree')
8. plt.ylabel('Number of nodes')
9. plt.show()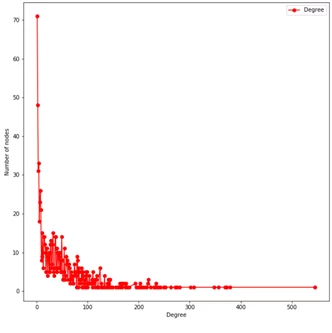
На получившемся графике мы видим распределение степеней узлов: большое количество узлов имеет немногочисленные связи с соседями, но есть небольшое количество крупных узлов, у которых количество связей с другими участниками огромно. Такая тенденция называется степенным законом распределения, и оно очень характерно для больших сетей. Этим законом можно описать распределение населения разных городов, ранжирование сайтов в Интернете и даже распределение материальных благ среди людей.
- Путь, диаметр и среднее расстояние в графе
Теперь давайте определим то, насколько участники нашего графа связаны между собой. Для начала поговорим о различных типах расстояний между узлами.
Любая последовательность ребер, которая соединяет узлы, называется путь. Чаще всего в исследованиях рассматривается простой путь, то есть путь без циклов и повторяющихся узлов. Кратчайший путь между двумя узлами называют геодезическим расстоянием. Самый длинный кратчайший путь в графе называют его диаметром, однако он очень чувствителен к отклонениям (одна цепочка в многомиллионном графе может изменить его диаметр). В направленных графах понятие диаметра можно применить только для компоненты сильной связности, ведь для подсчёта диаметра необходимо, чтобы для каждой пары узлов существовал путь между ними. В ненаправленных графах достаточно того, чтобы рассматриваемая компонента была связной.
Ещё одной очень информативной характеристикой считается среднее расстояние между узлами, которое можно получить, взяв среднее значение всех кратчайших путей в графе. Среднее расстояние определяется структурой графа: если граф построен в форме цепочки, оно будет большим, но чем теснее связаны узлы, тем меньше становится и среднее расстояние. Среднее расстояние можно посчитать как для компоненты сильной связности, так и для компоненты слабой связности:
1. print ('Диаметр: ', nx.diameter(G_strong))
2. print ('Среднее расстояние в компоненте сильной связности: ', nx.average_shortest_path_length(G_strong))
3. print ('Среднее расстояние в компоненте слабой связности: ', nx.average_shortest_path_length(G_weak))
Диаметр: 6
Среднее расстояние в компоненте сильной связности: 2.5474824768713336
Среднее расстояние в компоненте слабой связности: 2.164486568301397
Давайте разберём полученные результаты. Диаметр в данном случае показывает нам максимальное расстояние между двумя незнакомыми людьми, и здесь, как и в известной теории о шести рукопожатиях, это расстояние равно 6. Среднее расстояние в компонентах также невелико, в среднем двум незнакомым людям достаточно 2 «рукопожатий». Здесь можно также увидеть интересный феномен: среднее расстояние в компоненте сильной связности несколько ниже, чем в компоненте слабой связности. Объяснить это можно тем, что для компоненты слабой связности не учитывается направленность связей (только сам факт её наличия). Из-за этого связь в слабой компоненте появляется там, где она отсутствовала для сильной компоненты.
- Кластеризация и выделение сообществ
C расстояниями между участниками разобрались, давайте перейдём к другим явлениям, отражающим, насколько участники в графе связаны между собой: кластеризации и сообществам.
Кластерный коэффициент показывает то, что два элемента графа, связанные через третий элемент, с высокой долей вероятности связаны и друг с другом. Даже если они не связаны, то вероятность того, что они окажутся связанными в будущем, гораздо выше, чем у двух других случайно взятых узлов. Это явление, называемое кластеризацией или транзитивностью, чрезвычайно распространено в социальных графах.
Для графов с высокой степенью кластеризации характерно присутствие значительного количества связанных троек (трёх узлов, связанных друг с другом). Они являются строительным блоком многих социальных сетей, где количество подобных треугольников очень велико. Часто возникают даже не треугольники, а целые кластерные образования, называемые сообществами, которые связаны между собой теснее, чем с остальным графом.
Посмотрим на кластеризацию и кластерный коэффициент для компоненты слабой связности:
1. print ('Кластеризация: ', nx.transitivity(G_strong))
2. print ('Кластерный коэффициент: ', nx.average_clustering(G_strong))
Кластеризация: 0.2201493109315837
Кластерный коэффициент: 0.37270757578876434Для компоненты сильной связности мы можем получить те же характеристики, а также определить количество центральных узлов (узлов, которые сильнее всего связаны с остальными) и количество узлов на периферии графа:
1. print ('Кластеризация: ', nx.transitivity(G_strong))
2. print ('Кластерный коэффициент: ', nx.average_clustering(G_strong))
3. print ('Количество центральных узлов: ', len(nx.center(G_strong)))
4. print ('Количество узлов на периферии: ', len(nx.periphery(G_strong)))
Кластеризация: 0.2328022090200813
Кластерный коэффициент: 0.3905903756516427
Количество центральных узлов: 46
Количество узлов на периферии: 3Во втором случае кластеризация и кластерный коэффициент увеличились, это отражает, что в компоненте сильной связности содержится большее количество связанных троек. Давайте попробуем вместе определить основные сообщества в компоненте слабой связности:
1. G_undirected = G_weak.to_undirected()
2. partition = community.best_partition(G_undirected)
3. communities = set(partition.values())
4. communities_dict = {c: [k for k, v in partition.items() if v == c] for c in communities}
5. highest_degree = {k: sorted(v, key=lambda x: G.degree(x))[-5:] for k, v in communities_dict.items()}
6. print('Количество сообществ: ', len(highest_degree))
7. print('Количество элементов в выделенных сообществах:', ', '.join([str(len(highest_degree[key])) for key in highest_degree]))
Количество сообществ: 8
Количество элементов в выделенных сообществах: 113, 114, 125, 131, 169, 188, 54, 92Итак, в графе с электронной перепиской можно выделить 8 сообществ, которые связаны между собой теснее, чем с остальным графом. Самое маленькое из сообществ содержит 54 участников, а самое крупное – 188 участников. Для сетей, содержащих перекрывающиеся или вложенные сообщества, определить оптимальное разбиение может оказаться сложнее. Поэтому при каждом запуске кода состав сообществ может различаться. Посмотрим визуализацию для полученного нами разбиения:
1. pos = nx.spring_layout(G)
2. plt.figure(figsize=(15, 15))
3. cmap = cm.get_cmap('gist_rainbow', max(partition.values()) + 1)
4. nx.draw_networkx_nodes(G, pos, partition.keys(), node_size=20, cmap=cmap, node_color=list(partition.values()))
5. nx.draw_networkx_edges(G, pos, alpha=0.5)
6. plt.show()
На изображенном выше графе мы видим распределение участников по сообществам, где цвет узлов описывает принадлежность тому или иному сообществу.
- Взаимность связей
Кроме уже описанных свойств также существует такое понятие, как взаимность в направленной сети. Эта характеристика описывает, какой процент исходящих связей имеет обратную, входящую, связь. Для того, чтобы это узнать, используем специальную функцию overall_reciprocity библиотеки networkx и посмотрим на уровень взаимности в графе и его компонентах:
1. print ('Уровень взаимности графа: ', nx.overall_reciprocity(G))
2. print ('Уровень взаимности компоненты слабой связности: ', nx.overall_reciprocity(G_weak))
3. print ('Уровень взаимности компоненты сильной связности: ', nx.overall_reciprocity(G_strong))
Уровень взаимности графа: 0.6933635759258535
Уровень взаимности компоненты слабой связности: 0.6938791484032562
Уровень взаимности компоненты сильной связности: 0.7169719762222492В 71% случаев в компоненте сильной связности пользователи получали ответы на свои сообщения. Для компоненты слабой связности и всего графа в целом уровень предсказуемо ниже.
- Универсальные свойства сетей
Подводя итог, сложные сети, в целом, обладают определёнными свойствами и некоторые характерны для многих сетей. Проведённый нами анализ датасета с электронными сообщениями хорошо подтверждает эти тенденции:
- Распределение степеней узлов. Во всех сетях есть много узлов с низкой степенью, в то же время есть небольшое количество огромных узлов, у которых соседей очень много. Это логично: если мы посмотрим на ссылки между различными web-сайтами, то обнаружим, что существует небольшое количество крупных сайтов, на которые в большом количестве ссылаются все остальные (Wikipedia, Microsoft). В то же время на среднестатистические сайты ссылки встречаются гораздо реже, хотя большинство сайтов относятся именно к такому типу.
- Диаметр и среднее расстояние в графе. Крупные сети имеют такое устройство, что средний диаметр у них очень небольшой, это явление в анализе социальных сетей называется явлением «малого мира». Оно хорошо описывается через теорию шести рукопожатий: несмотря на огромное количество людей, среднее расстояние между двумя незнакомыми людьми будет равным шести.
- В больших сетях, как правило, присутствуют гигантские связные компоненты: более 80% узлов связаны между собой, остальные представлены более мелкими компонентами. При этом в каждой из крупных компонент можно встретить сообщества – группы объектов, которые связаны между собой теснее, чем с остальным графом. Наличие кластеризации, то есть большого количества таких сообществ, чрезвычайно распространено в социальных графах.
- Во многих социальных графах действует принцип взаимности, когда при наличии исходящей связи очень высока вероятность встретить и входящую связь. Эта концепция специфична для направленных сетей, поскольку взаимность и обмен являются фундаментальными социальными процессами.
Все перечисленные выше тенденции мы разобрали и подтвердили для датасета с электронной перепиской: в графе обнаружилась большая связная компонента, содержащая более 80% всех узлов. Внутри этой компоненты большинство узлов характеризовалось небольшим количеством, однако существовал небольшой процент участников, у которых количество соседей было огромно. Также мы увидели, что диаметр и среднее расстояние между участниками графа небольшое: среднее расстояние в компоненте слабой связности, содержащей 986 участников, составило всего 2.1, что означает, что большинство участников связаны друг с другом всего через два «рукопожатия». Кроме того, граф характеризуется высокой степенью взаимности: 69% всех участников поддерживали двусторонний контакт между собой.
Примечания:
- С полным текстом исследования можно ознакомиться в книге Николая Викторовича Урсул «Вся правда о Forex» (2019).
- Исследование описано в статье «The Application of Social Network Analysis to Accounting and Auditing» Slobodan Kacanski, Dean Lusher (2017, ссылка).