/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
Пока мы сидим в офисе, попивая горячий чай, где-то там на просторах космоса происходит что-то действительно важное. То, что приковывает взгляды астрономов и исследователей со всего мира, завораживает, интригует, а может и пугает тех, кто знает об этом чуть больше, чем мы. Рождаются новые Галактики, летает Тесла Илона Маска под песни бессмертного Дэвида Боуи, в общем, красота.
Но вернёмся на время на Землю. Так уж получилось, что анализ данных – потребность кросснаучная. И тем привлекательная. Поскольку исследовано может быть всё, от недр Земли до бескрайнего космоса.
Хочу рассказать о подобном опыте, а именно об участии в международной олимпиаде по анализу данных IDAO 2019, которую уже третий год подряд проводит мой родной университет – НИУ ВШЭ.
Задача сводилась к предотвращению и детекции “космических ДТП”, когда спутники на орбите при неоптимальных траекториях движения врезаются друг в друга, превращаясь в космический мусор, который на космических скоростях вполне может стать причиной ещё нескольких аварий, потери нескольких миллионов долларов и нескольких вызовов на ковёр где-нибудь в NASA или Роскосмосе. Почему так случилось? Очевидно, виноваты звёзды. Или нет, давайте разбираться. К слову, статистика по количеству космических объектов земного происхождения, летающих на околоземной орбите, приведена ниже.
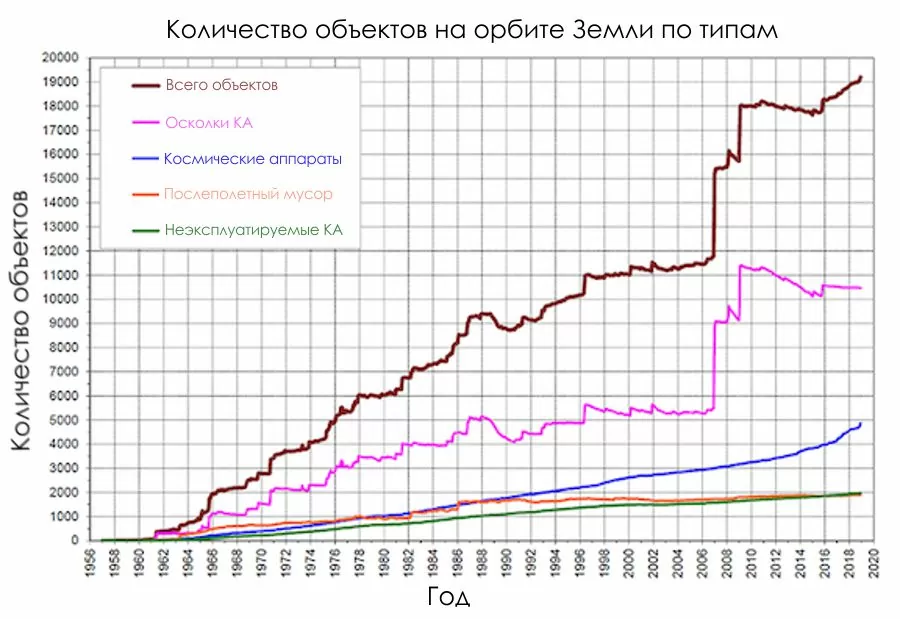
Из неё видно, что количество космического мусора увеличивается год от года. Итак, здесь я постараюсь рассказать, как мы смогли занять 22 место из 302.
Для начала рассмотрим исходные данные, которые выглядят следующим образом.
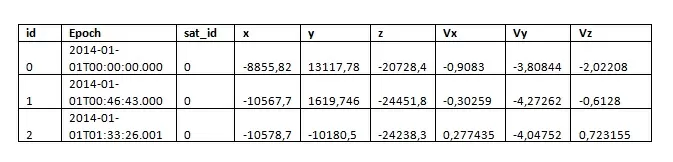
Где x,y,z – координаты объекта в трёхмерном пространстве, а Vx, Vy, Vz – скорости. Также присутствуют симуляционные данные, полученные алгоритмом GPT-4 с префиксом _sim, которые мы использовать не будем.
Для начала построим простейшую визуализацию, это поможет понять, как устроены данные. Я использовал plotly. Если рассматривать данные в двухмерной системе координат, то они выглядят следующим образом. Ниже отображены данные по оси y седьмого спутника. Больше графиков, которые можно повертеть мышкой и поскалить и при этом с пользой провести время, в .ipynb на Github.
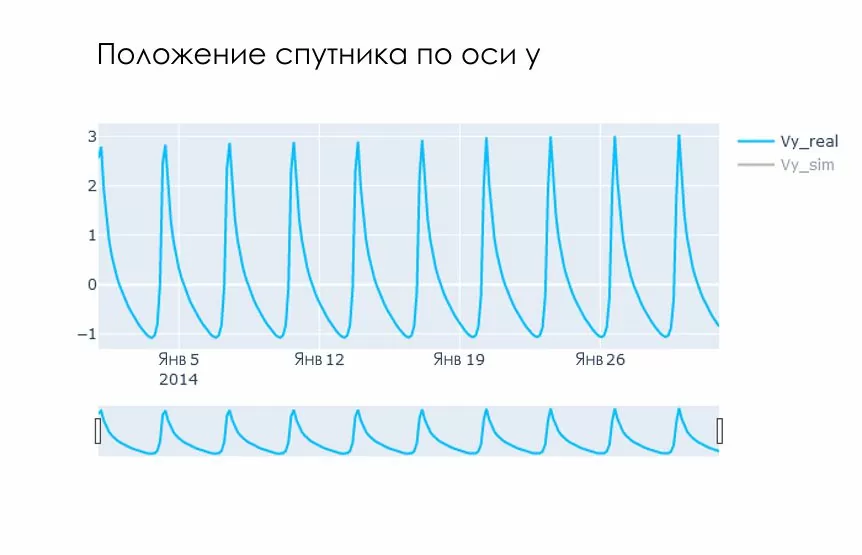
При проведении EDA (Explorative Data Analyze) было замечено, что в данных присутствуют наблюдения, отличающиеся по времени на одну секунду. Их необходимо удалить, чтобы сохранить сезонность. Скорее всего один и тот же объект был детектирован в одной и той же точке дважды.
Если кратко, данный временной ряд явно имеет линейный тренд и сезонность, равную 24, т. е. спутник совершает оборот вокруг Земли за 24 наблюдения. Это поможет в дальнейшем выбрать оптимальный алгоритм.
Теперь напишем функцию, которая будет предсказывать значения временного ряда, используя алгоритм SARIMA (была использована реализация из пакета statsmodels), при этом оптимизируя параметры модели и выбирая лучшую с минимальным значением критерия Акаике. Он показывает, насколько модель усложнена параметрами и “переобучена”. Формула приведена ниже.
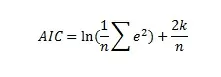
Конечный вывод выглядел следующим образом:

Разумеется, к этому мы пришли спустя несколько десятков итераций и многократных переписываний кода. Что-то заходило, значительно улучшая наш скор, что-то в конечном итоге падало, пожирая наше время, подобно Лангольерам. Но так или иначе были получены предсказания положения спутника и скоростей его перемещения на следующий месяц.
Метрикой качества была SMAPE симметричная средняя процентная ошибка.
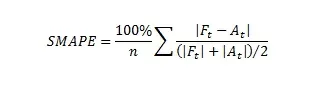
Финальная формула выглядела следующим образом:
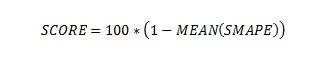
В конечном итоге мы получили кучи исписанных не очень хорошим кодом .ipynb тетрадок, csv файлов с абсолютно алогичными названиями, бессонных ночей, тысячи обновлений лидерборда, десятки упавших сабмитов и прочих прелестей ML хакатонов, ну и 22 место из 302 команд на приватном лидерборде, т.е. попали в ТОП 7%.

В качестве идей для оптимизации решения предлагается попробовать углубиться в EDA, чтобы понять данные на более низком уровне, попробовать использовать другие предсказательные алгоритмы. Более подробный анализ в репозитории. Любите ML и stay tuned.
По всем вопросам, корректировкам и предложениям можно писать мне @do_what_thou_wilt