/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 3 мин.
Для каждого из нас распознавать какие-либо объекты – естественная и привычная возможность организма. При этом для компьютера, пока что, – это не так-то и просто. Последние несколько лет человечество регулярно предпринимает попытки научить компьютер распознавать хотя бы часть того, что может видеть человек.
Чаще всего мы встречаемся с компьютерным зрением на кассах в магазине. Я сейчас о процессе считывания штрих кодов. Эти непонятные для обычного человека «полоски» были разработаны специально, чтобы упростить компьютеру процесс распознавания. Но для компьютерного зрения есть и более сложные задачи: поиск дефектов на производстве, исследование медицинских снимков, распознавание номеров автомобилей, распознавание лиц и т.д.
Недавно в своей деятельности мы столкнулись с задачей идентифицировать среди объявлений на торговых площадках Рунета те, где продаются уникальное оборудование и материальные ценности, определенного вида. Во избежание огромных трудозатрат большого количества специалистов мы решили использовать технические ресурсы, а именно, ту самую технологию Computer Vision.
Для начала компьютер необходимо обучить распознавать среди всех фото в объявлениях на сайте именно те, которые нам необходимы. Для этого необходимо создать обучающий датасет и разметить его (показать где именно на изображении находится искомый объект). Для задачи классификации в обучающем датасете необходимо использовать как можно больше различных изображений искомого объекта. Для себя мы определились, что нам необходимо ~1000 изображений каждого искомого объекта.
Вот тут-то и пришло осознание того, что для создания данной обучающей выборки потратится неприемлемое количество времени и сил (ведь мало того, что необходимо много фото с разных ракурсов, данные фотографии должны быть разного качества, с разным освещением, балансом белого и другими изменяемыми параметрами изображения). На данном этапе мы решили разделиться: часть команды отправилась проявлять свои навыки фотографов, а вторая часть ушла думать и гуглить то, как можно автоматизировать данную задачу.
Идея появилась практически сразу же – парсить картинки из результатов поиска в сервисе Яндекс.Картинки. Готовое средство автоматизации также нашлось достаточно быстро: бесплатное ПО PictureYandexGraber.
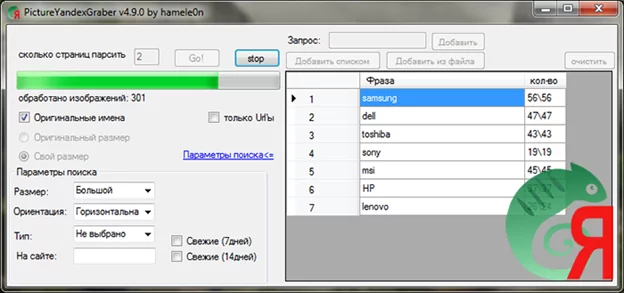
Спустя некоторое количество времени был сформирован отличный датасет, а результат разделения труда дал нам возможность исследовать новый для нас инструмент диджитализации. Датасет сформированный автоматизированным методом отличается:
- разнообразием изображений;
- скоростью формирования (в 50 раз быстрее механического способа).
Но, к сожалению, нельзя не отметить и минусы данной программы. А точнее один МИНУС: Capcha от Яндекс. В нашем случае решение данной проблемы было достаточно примитивным – смена IP адреса физически (меняли источник интернета). По причине относительно небольшого объема выгружаемых изображений capcha сильно нам не надоедала. Но в целом функционалом программы предусмотрена возможность использовать proxy, поэтому если есть необходимость парсить большое количество изображений с Яндекс.Картинки проблему можно решить используя данный инструмент.
Кроме того, функционалом программы PictureYandexGraber предусмотрено:
- поиск изображений по заданным параметрам: размер, ориентация, тип;
- сохранение url’ов изображений в отдельный файл;
- сохранение изображений в 10 потоков;
- выбор размера
сохраняемого изображения:
- оригинальный;
- по вашему размеру (width и height);
- по одному из параметров (указывается width/height, а второй параметр высчитывается пропорционально оригинальному размеру).
В целом, программа нам понравилась, и мы её взяли на вооружение. Да, кстати, для корректной работы программы Вам необходимо установить net framework не ниже 4.0(если вдруг его нет на вашем компьютере).