/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
Аудит кибербезопасности внешних web-ресурсов – это процесс проверки на наличие потенциальных уязвимостей web-компонентов сайтов, платформ, которые посещают пользователи из внешней сети интернет. Выявленные недостатки классифицируются в соответствии с международными подходами к оценке критичности эксплуатации рисков информационной безопасности. Изучением уязвимостей занимается международное некоммерческое сообщество OWASP (Open Web Application Security Project). Более подробно можно почитать на русскоязычном форуме по ссылке.
Существует бесплатный инструмент «Vulners» в виде веб-расширения для браузера (Chrome, Yandex, Edge, Firefox). Он использует пассивный сбор данных о web-сервере и установленных компонентах, анализирует версии и проверяет наличие уязвимостей в базе данных. На сегодня база данных «Vulners» является самым масштабным источником информации об обнаруженных багах веб-компонентов, включает в себя информацию из более чем 100 авторитетных ресурсов в сфере ИБ. Благодаря пассивному анализу, риски влияния на работоспособность исследуемых ресурсов минимальны, и нам не нужно согласовывать свои действия с бизнесом, что значительно упрощает задачу.
Целью проекта было провести оценку уровня защищённости Кибербезопасности web-ресурсов компании и сформировать рекомендации по устранению рисков ИБ.
Идея была в следующем – список сайтов проверить с помощью Vulners, собрать информацию об уязвимостях, сверить с данными на официальном сайте ФСТЭК России и на основании данных регулятора, сформировать аудиторский отчёт с выводами и рекомендациями по устранению.
Road map проекта:
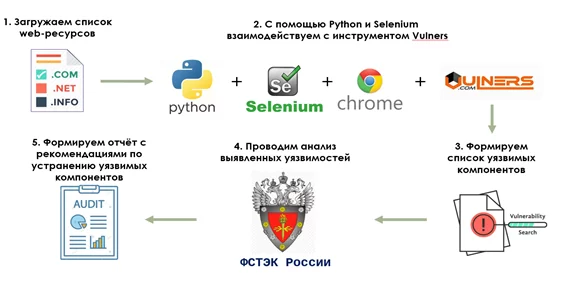
Для решения проекта мы использовали язык Python и библиотеки Pandas, Numpy, OS, BeautifulSoup, Selenium.
Функция (def parse_vulners(soup)): выполняет парсинг сайта, результат анализа Vulners
def parse_vulners(soup):
data = []
domain_linked_site = soup.find_all("span", {"class":"domain-name amber-text text-darken-4"})
site_names = [str(i).split(">")[1].strip("</span") for i in domain_linked_site]
list_vuln = soup.find_all("ul", {"class":"collapsible"})
for num, vuln_block in enumerate(list_vuln):
soft_block = vuln_block.find_all("div", {"class":"collapsible-header"})
soft_name = [str(i).split(">")[3].split('<!--')[0] for i in soft_block]
version = [str(i).split(">")[7].split('<!--')[0].strip(' - ') for i in soft_block]
score = [str(i).split(">")[11].strip('</span') for i in soft_block]
text_vuln_codes = vuln_block.find_all("span", {"class": "title"})
codes = [str(i).split(">")[1].strip("</span") for i in text_vuln_codes]
text_code_scores = vuln_block.find_all("a", {"class": "secondary-content"})
code_scores = [str(i).split(">")[2].strip("</span") for i in text_code_scores]
site_name = site_names[num]
for i in range(len(score)):
data.append([site_name, soft_name[i], version[i], score[i], find_vuln_code(score[i], codes, code_scores)])
return data
Функция (def get_web_page(url_site)): с помощью Selenium запускает Chrome, активирует расширение (Vulners) и собирает всю информацию со страницы.
def get_web_page(url_site):
executable_path = "./chromedriver"
os.environ["webdriver.chrome.driver"] = executable_path
options = Options()
options.add_extension('./extension_2_0_1_0.crx')
driver = webdriver.Chrome(executable_path=executable_path, options=options)
driver.get(url_site)
vulners = driver.get("chrome-extension://dgdelbjijbkahooafjfnonijppnffhmd/index.html")
driver.find_element_by_css_selector('.vulners-start-btn.waves-effect.waves-light.btn-large.amber.darken-4').click()
soup = BeautifulSoup(driver.page_source, 'html.parser')
driver.close()
driver.quit()
return soupОсновное тело программы:
#считываем список сайтов
sites = pd.read_excel('Сводный список.xlsx')
list_url = sites['Домен'].values.tolist()
#конкатенация строк для проверки сайтов c протоколом https
list_url = ["https://"+i for i in not_prepared_2]
len(list_url)
#создаём DataFrame для заполнения результатов
df = pd.DataFrame(columns = ['URL', 'vulner_link', 'Software', 'Soft_version', 'Ratings', 'Vulner_code'])
not_preparrr = []
%%time
#пробегаем по каждому сайту – Сводный список.xlsx
for url_site in list_url:
print('Prepare {0}'.format(url_site))
#получаем страницу с результатом на вкладке Vulners
page = get_web_page(url_site)
try:
#проводим поиск необходимой информации (парсим данные)
p_soft = parse_vulners(page)
#каждую уязвимость для сайта заносим в таблицу
for soft in p_soft:
row = df.shape[0]
df.at[row, 'URL'] = url_site
df.at[row, 'vulner_link'] = soft[0]
df.at[row, 'Software'] = soft[1]
df.at[row, 'Soft_version'] = soft[2]
df.at[row, 'Ratings'] = soft[3]
df.at[row, 'Vulner_code'] = soft[4]
except Exception as e:
not_preparrr.append(url_site)
print(e)
#в случае когда ничего не обнаружено
print('Нет уязвимостей для сайта {0}'.format(url_site))На официальной странице ФСТЭК – “Банк данных угроз безопасности информации” скачиваем файл со сведениями об угрозах. Производим join по уникальному коду уязвимости CVE.
Результатом всех манипуляций получился отчёт в виде сводной таблицы с информацией об уязвимых компонентах и рекомендациях по устранениям недостатков ИБ:

В завершении хотел бы отметить, что можно организовать мониторинг своих сайтов на постоянной основе и быть всегда в курсе появления новых уязвимостей и выхода эксплоитов.