/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
Способы удаления дубликатов в SQL Server
При проектировании объектов, в частности таблиц в БД SQL Server необходимо придерживаться определенных правил: рекомендуется использовать правила нормализации БД; таблица должна иметь первичные ключи, кластерные и некластерные индексы; ограничения для обеспечения целостности данных и производительности. Но даже если следовать этим правилам, мы можем столкнуться с проблемой появления дубликатов в строках таблицы. Кроме этого, возможна ситуация получения дубликатов при импорте данных, когда мы загружаем данные as is в промежуточные таблицы, и далее требуется удалить дублирующие записи перед загрузкой в промышленные таблицы.
Рассмотрим различные способы для очистки данных от дублей. Создадим простую таблицу сотрудников и наполним её несколькими записями.
CREATE TABLE Employee
(
[id] int identity(1,1),
[Фамилия] nvarchar(100),
[Имя] nvarchar(100),
[Отчество] nvarchar(100),
[Дата рождения] date,
)
GO
Insert into Employee ([Фамилия],[Имя],[Отчество],[Дата рождения])
values
(N'Алексеев',N'Алексей',N'Алексеевич','1990-03-01'),
(N'Алексеев',N'Алексей',N'Алексеевич','1990-03-01'),
(N'Алексеев',N'Алексей',N'Алексеевич','1990-03-01')
(N'Иванов',N'Иван',N'Иванович','1985-01-01'),
(N'Иванов',N'Иван',N'Иванович','1985-01-01'),
(N'Петров',N'Петр',N'Петрович','1988-02-01'),Как мы видим, в таблице присутствуют дублирующие строки, которые необходимо удалить.
- Удаление дубликатов с использованием агрегатных функций
C помощью условия GROUP BY мы группируем данные по определенным столбцам и используем функцию COUNT для подсчета вхождений строк в таблицу.
Например, с помощью следующего запроса, определим записи, которые присутствуют в таблице более 1 раза.
Select [Фамилия], [Имя], [Отчество], [Дата рождения], count(*) as CNT
FROM NTA.dbo.Employee
GROUP BY [Фамилия], [Имя], [Отчество], [Дата рождения]
having count(*) > 1Т.е. сотрудники Алексеев А.А. и Иванов И.И. присутствуют в таблице 3 и 2 раза соответственно.

Удалим дублирующие записи, оставив только строки с MIN id сотрудника.
Delete FROM NTA.dbo.Employee
Where id not in
(
select min(id) as MinRowID
FROM NTA.dbo.Employee
group by [Фамилия],[Имя],[Отчество],[Дата рождения]
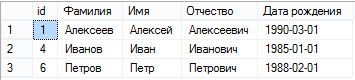
)Выведем оставшиеся записи таблицы, и убедимся, что дубликаты отсутствуют.
Отметим, что данный способ удаления дубликатов возможен в случае таблиц, для которых определен первичный ключ.
- Удаление дубликатов используя обобщенные табличные выражения (CTE)
Мы можем использовать связку обобщенных табличных выражений и функции ROW_NUMBER() для удаления дубликатов, например следующим образом:
WITH CTE ([Фамилия],
[Имя],
[Отчество],
[Дата рождения],
[Нумерация]
)
AS (SELECT [Фамилия],
[Имя],
[Отчество],
[Дата рождения],
ROW_NUMBER () OVER (PARTITION BY [Фамилия],
[Имя],
[Отчество],
[Дата рождения]
ORDER BY id) AS [Нумерация]
FROM NTA.dbo.Employee)
DELETE FROM CTE
WHERE [Нумерация] > 1В данном запросе мы используем функцию ROW_NUMBER() с конструкцией PARTITION BY в предложении OVER для нумерации записей, и удаляем записи с пронумерованными значениями > 1, соответствующие дубликатам.
- Удаление дубликатов с использованием инструментария SSIS пакетов.
Создадим в SQL Server Data Tools новый пакет integration Services.
Добавим в пакет элемент «OLE DB Source», откроем редактор OLE DB Source, в графе Connection Manager укажем реквизиты экземпляра СУБД и БД, и наименование исходной таблицы с данными, содержащей дубликаты.
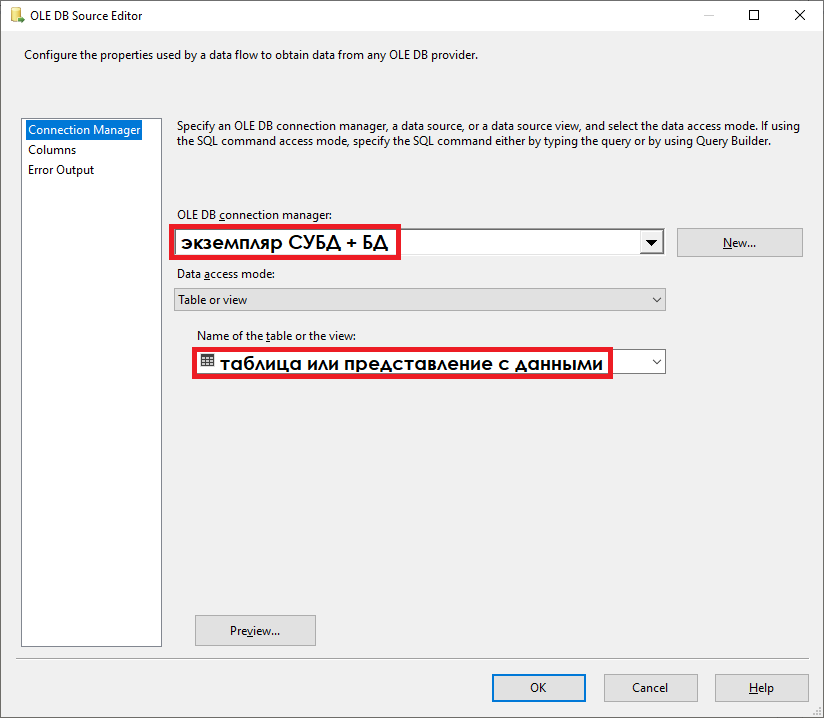
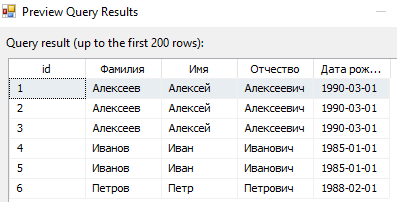
С помощью кнопки Preview убедимся, что в исходной таблице присутствуют дубликаты.
Добавим оператор «Sort», и выделим поля, в которых присутствуют дублирующие данные.
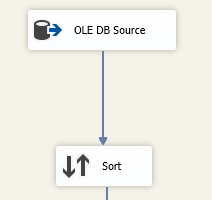
Установим галку «Remove rows with duplicate sort values» для удаления дубликатов.
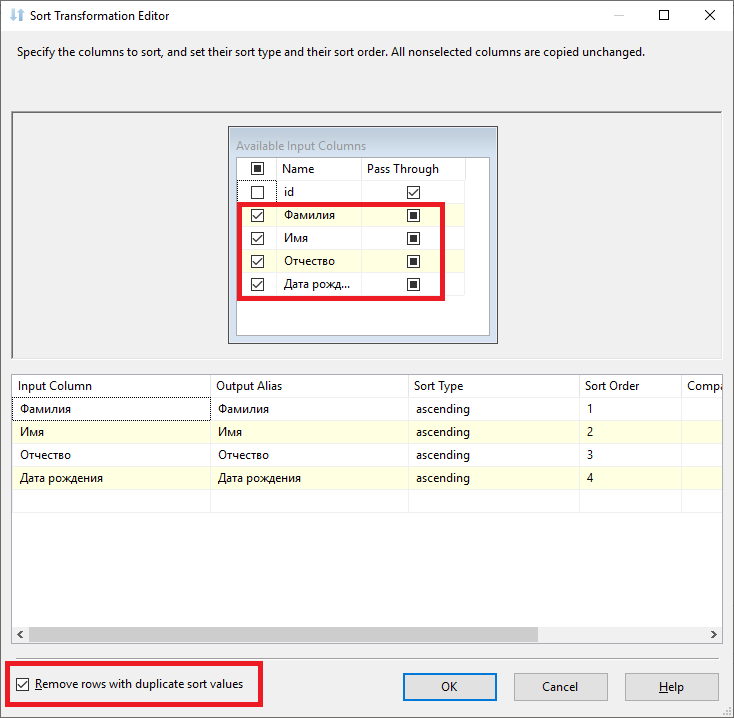
Добавим элемент «OLE DB Destination», в котором укажем целевую таблицу для записей результата очистки данных.
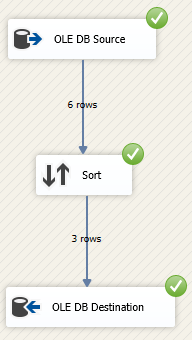
Запустив на исполнение реализованный SSIS пакет, мы видим, что в целевой источник загрузилось 3 строки, проверим, что отсутствуют дубликаты.
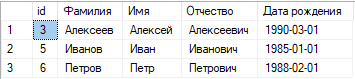
Необходимо отметить, что при использовании данного способа потребуется дополнительное место для хранения новой целевой таблицы, однако данный вариант позволяет избежать ошибок и вернуться к исходному варианту, в случае если результат в целевой таблице не будет являться удовлетворительным.
В данной статье мы рассмотрели различные способы удаления дубликатов записей в таблицах БД SQL Server, которые могут быть использованы в работе в зависимости от задачи и объема данных.
При больших объемах дубликатов в данных целесообразно рассмотреть возможность сохранения уникальных значений в промежуточную таблицу, очистку рабочей таблицы, и возврат оставленных уникальных записей.