/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
При выполнении запросов язык XPath оперирует такими сущностями как узлы. Узлы бывают нескольких видов: element (узел-элемент), attribute (узел-атрибут), text (узел-текст), namespace (узел-пространство имён), processing-instruction (узел-исполняемая инструкция), comment (узел-комментарий), document (узел-документ).
Рассмотрим, как в XPATH задаётся последовательность узлов, направления выборки и выбирать узлы с конкретными значениями.
Для осуществления выборки узлов в основном используется 6 основных типов конструкций:

Так же при выборе узлов имеется возможность использовать wildcard маски, когда нам неизвестно, какой вид должен принимать узел.

В языке XPATH для выборки относительно текущего узла используются специальные конструкции под названием оси.
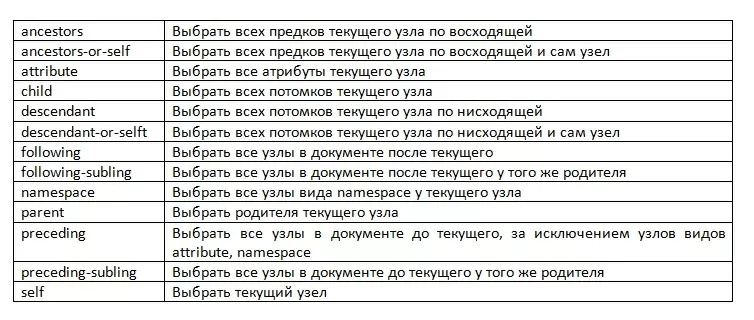
Правило выборки может быть как абсолютным (//input[@placeholder=”Логин” – выборка начиная с корневого узла], так и относительным (*@class=”okved-table__code” – выборка относительно текущего узла) .
Построение правила выборки на каждом шаге выборки осуществляется относительно текущего узла и учитывает:
- Название оси, относительно которой следует производить выборку
- Условие выборки узла по имени или по положению
- Ноль или более предикатов
В общем случае синтаксис одного шага выборки имеет вид:
axisname::nodetest[predicate]Для выборки конкретных узлов по некоторым условиям, параметрам или позиции используют такое инструментально средство как предикаты. Условие предиката ставится в квадратных скобках. Примеры:
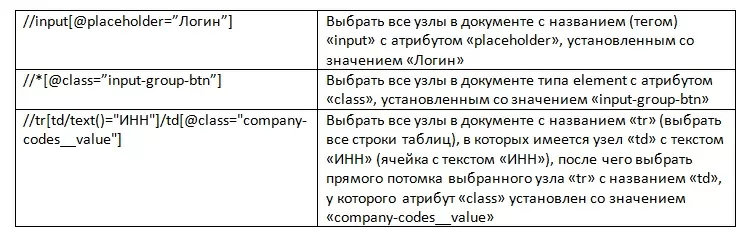
Помимо приведенных конструкций языка XPATH, он также содержит поддерживает ряд операторов (+, -, *, div, mod, =, !=, and, or и т.д.), а также более 200 встроенных функций.
Приведем такой практический пример. Нам необходимо выгрузить информацию о периодах определенного списка людей. Для этого воспользуемся сервисом notariat.ru.
Импортируем зависимости.
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
from multiprocessing import Pool
from retry import retry
import itertools, time, pprint, os, re, traceback, sys, datetime
import pandas as pd, numpy as np, multiprocessing as mp
Загружаем данные по людям:
df_people = pd.read_excel('people.xlsx')Извлекаем информацию из страниц с информацией о людях.
def find_persons(driver, name, birth_date):
base_url = 'https://notariat.ru/ru-ru/help/probate-cases/'
# Обновление страницы поиска людей
driver.get(base_url)
# Поиск поля ввода имени и отправка значения
driver.find_element_by_xpath('//input[@name="name"]').send_keys(name)
# Поиск выпадающего списка для указания дня рождения
driver.find_element_by_xpath('//select[@data-placeholder="День"]/following::div/a').click()
# Выбор дня рождения из выпадающего списка
driver.find_element_by_xpath('//select[@data-placeholder="День"]/following::div//li[@data-option-array-index={}]'.format(birth_date.day)).click()
# Поиск выпадающего списка для указания дня месяца
driver.find_element_by_xpath('//select[@data-placeholder="Месяц"]/following::div/a').click()
# Выбор месяца рождения из выпадающего списка
driver.find_element_by_xpath('//select[@data-placeholder="Месяц"]/following::div//li[@data-option-array-index={}]'.format(birth_date.month)).click()
# Ввод года рождения в виде строки
driver.find_element_by_xpath('//input[@placeholder="Год"]').send_keys(str(birth_date.year))
# Инициализация поиска
driver.find_element_by_xpath('//*[contains(., "Искать дело")]').click()
# Ожидание до 20 секунд до появления списка людей, данный список находится в контейнере с классом «probate-cases__result-list»
WebDriverWait(driver, 20).until(EC.visibility_of_element_located((By.CLASS_NAME, "probate-cases__result-list")))
time.sleep(2)
# Ищем общее количество страниц с результатами
max_pages = 1
pages_counters = driver.find_elements_by_xpath('//a[@class="pagination__item-content"]')
if pages_counters:
max_pages = int(pages_counters[-1].text)
data = []
def parse_page_data():
# Извлекаем ссылки на все строки с данными по людям внутри нумерованного списка
lines = driver.find_elements_by_xpath('//ol[@class="probate-cases__result-list"]/li')
for line in lines:
name = ' '.join(map(lambda el: el[0].upper() + el[1:].lower(), line.find_element_by_xpath('.//h4').text.split()))
death_date = datetime.datetime.strptime(line.find_element_by_xpath('.//p').text.split(':')[-1].strip(), '%d.%m.%Y')
data.append((name, birth_date, death_date))
# Если всего одна страница с результатами
if max_pages == 1:
parse_page_data() # то парсим то что есть и на этом заканчиваем
else:
for page_num in range(1, max_pages + 1):
# Иначе проходим по каждом странице с данными, кликая на кнопку со следующим номером страницы
driver.find_element_by_xpath('//li[./a[@class="pagination__item-content" and text()="{}"]]'.format(page_num)).click()
time.sleep(0.2)
# и извлекаем данные с конкретной страницы
parse_page_data()
return data
Осуществляем поиск, используя модуль multiprocessing, для ускорения сбора данных.
def parse_persons(persons_data_chunk, pool_num):
# Инициализируем браузер Chrome в режиме headless со стандартным разрешением (При меньшем разрешении расположение или классы DOM элементов на сайте notariat.ru может меняться)
chrome_options = Options()
chrome_options.add_argument("--headless")
chrome_options.add_argument("--window-size=1920,1080")
driver = webdriver.Chrome(options=chrome_options)
driver.set_page_load_timeout(20)
data = []
print(pool_num, '')
# Производим поиск данных по каждому человеку из выделенной группы
for ind, (person_name, person_date) in enumerate(persons_data_chunk, start=1):
print('pool:', pool_num, ', person: ', ind, '/', len(persons_data_chunk))
try:
data.extend(find_persons(driver, person_name, person_date))
except Exception as e:
print(pool_num, 'failed to load', person_name, person_date, "error:", e)
traceback.print_exception(*sys.exc_info())
print(pool_num, 'done')
return data
def parse(people_data, parts=5):
p = mp.Pool(parts)
# Производим разбивку списка людей на обрабтку на несколько меньших списков для осущевления параллелизации сбора данных
people_in_chanks = np.array_split(people_data, parts if parts < len(people_data) else 1) or []
all_data = p.starmap(parse_persons, zip(people_in_chanks, range(parts)))
out = []
for el in all_data:
out.extend(el)
return out
parsed_data = parse(people_data)
И сохраняем результаты:
df = pd.DataFrame({
'ФИО': list(map(lambda el: el[0], parsed_data)),
"Дата рождения": list(map(lambda el: el[1], parsed_data)),
'Дата смерти': list(map(lambda el: el[2], parsed_data))
})
df.to_excel('results.xlsx', index=False)
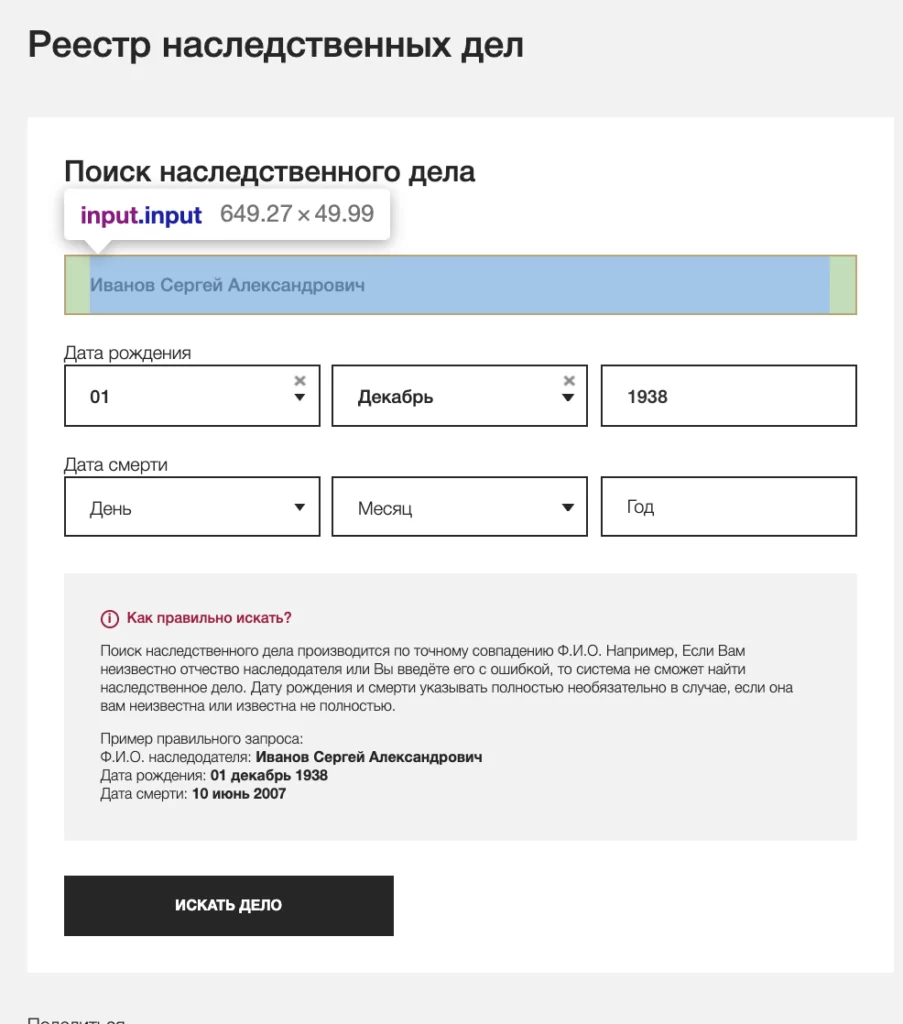
На рисунке ниже представлена страница поиска личных дел, на которой указываются ФИО, дата рождения, по которым в дальнейшем осуществляется поиск. После ввода ФИО и даты рождения алгоритм нажимает на кнопку искать дело, после чего анализирует полученные результаты.
На следующем рисунке видим список, парсингом элементов которого и занимается алгоритм.

На примере выше было показано, как можно использовать XPATH для сбора информации с веб-страниц. Но как уже было сказано, XPATH применим для обработки любых xml документов, являясь отраслевым стандартом для доступа к элементам xml и xhtml, xslt преобразований.
Зачастую читабельность кода влияет и на его качество, поэтому следует отказаться от регулярных выражений при парсинге, изучить XPATH и начать применять его в рабочем процессе. Это сделает ваш код проще, понятнее. Вы допустите меньше ошибок, а также сократиться время отладки.