/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 6 мин.
Благодаря машинному обучению, в аудиторской практике появилась возможность проверки больших массивов данных путем комплексного автоматического анализа признаков для нахождения закономерностей и составления прогнозов без привлечения человеческих ресурсов.
Одна из распространенных задач – задача классификации, в рамках которой необходимо получить категориальный ответ на основе набора признаков: по составу почвы определить, в какой широте был взят образец, определить категорию надежности клиента банка и многое другое.
Для решения подобного рода задач существует множество инструментов и библиотек, одну из которых мы попробуем использовать для решения простой задачи классификации текста.
В процессе выбора инструмента мы остановились на WEKA – наборе инструментов машинного обучения на языке Java для решения задач интеллектуального анализа данных и машинного обучения. Среди возможностей фреймворка можно выделить предварительную обработку данных, алгоритмы классификации, регрессии и кластеризации, правила ассоциации и визуализацию.
Рассмотрим работу с фреймворком на примере простой задачи: по описанию постройки необходимо определить ее тип.
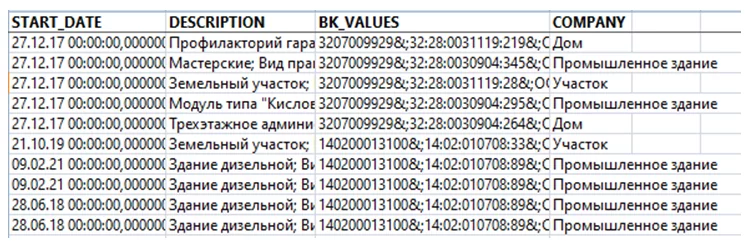
Для начала необходимо загрузить данные для обработки. Для загрузки данных у фреймворка есть свой формат файла .arff
@relation test
@attribute text string
@attribute class {someclass1, someclass2}
@data
‘Some text’,someclass1
‘Another text’,someclass2
…
Помимо своего расширения WEKA также принимает файлы других форматов: .c45, libSVM, .xrff и .csv
Мы используем датасет в формате .csv поэтому загружать будем через одноименный класс-конвертер CSVLoader(). В качестве источника данных передается ссылка на файл и через метод getDataSet() получаем набор данных:
public Instances loadDataset(String path) {
Instances ds = null;
try {
converter = new CSVTOARFFConerter();
ds = converter.LoadCSV(path);
if (ds.classIndex() == -1) {
ds.setClassIndex(ds.numAttributes() - 1);
}
} catch (Exception ex) {
Logger.getLogger(ModelGenerator.class.getName()).log(Level.SEVERE, null, ex);
}
return ds;
}
public class CSVTOARFFConerter {
public static Instances LoadCSV(String path) throws Exception {
CSVLoader loader = new CSVLoader();
loader.setSource(new File(path));
Instances data = loader.getDataSet();
return data;
}
}
Используя этот класс загружаем тренировочную и тестовую выборку данных.
Если данные были загружены без предварительной обработки – необходимо ее выполнить уже внутри фреймворка. Один из способов предобработки данных – нормализация. Нормализация применяется для приведения признаков к некоторому заданному диапазону. Это позволяет сводить признаки в одной модели для ее корректной работы.
Нормализация данных в WEKA происходит через класс Normalize():
Filter normalization = new Normalize();
Instances traindataset = loader.loadDataset(DATASETTRAINPATH);
normalization.setInputFormat(traindataset);
traindataset = Filter.useFilter(traindataset, normalization);
Instances testdataset = loader.loadDataset(DATASETTESTPATH);
normalization.setInputFormat(testdataset);
testdataset = Filter.useFilter(testdataset, normalization);
После подготовки датасетов можно переходить к созданию классификатора:
public Classifier CreateClassifier(Instances traindataset) {
var model = new FilteredClassifier();
model.setClassifier(new NaiveBayesMultinomial());
Attribute textField = new Attribute("KN", (FastVector) null);
FastVector classes = new FastVector();
classes.addElement("SOME_COMPANY");
classes.addElement("ANOTHER_COMPANY");
Attribute classField = new Attribute("Org", classes);
wekaAttributes = new ArrayList<>();
wekaAttributes.add(classField);
wekaAttributes.add(textField);
try {
StringToWordVector stwv = new StringToWordVector();
stwv.setAttributeIndices("last");
NGramTokenizer nTokenizer = new NGramTokenizer();
nTokenizer.setNGramMinSize(1);
nTokenizer.setNGramMaxSize(1);
nTokenizer.setDelimiters("\\W");
stwv.setTokenizer(nTokenizer);
stwv.setLowerCaseTokens(true);
model.setFilter(filter);
model.buildClassifier(traindataset);
} catch (Exception ex) {
Logger.getLogger(ModelGenerator.class.getName()).log(Level.SEVERE, null, ex);
}
return model;
}
Необходимо определиться с алгоритмом классификации. Для задачи классификации текста из имеющихся у фреймворка алгоритмов классификации больше других подходит алгоритм полиномиальной наивной Байесовской классификации. Он обеспечивает простой способ создания точных моделей с очень хорошими характеристиками, учитывая его простоту.
Принцип работы алгоритма заключается в вычислении вероятности наступления некоторых событий, учитывая вероятности «предыдущих» событий.
В полиномиальной модели событий векторы признаков представляют частоты, с которыми определенные события были сгенерированы полиномиальным распределением (p_1, …, p_n) где p_i — это вероятность того, что произойдет событие i (или K таких многочленов в случае мультикласса). Вектор признаков (x_1, …, x_n) это гистограмма, где x_i подсчитывает, сколько раз событие i наблюдалось в конкретном случае. Это модель событий, обычно используемая для классификации документов, с событиями, представляющими появление слова в одном документе.
Алгоритм реализован через класс NaiveBayesMultinomial(). Для фильтрации параметров классификатора этот класс оборачивается метаклассом FilteredClassifier() — класс для запуска произвольного классификатора данных, прошедших произвольный фильтр. Как и классификатор, структура фильтра основана исключительно на обучающих данных, и тестовые экземпляры будут обрабатываться фильтром без изменения их структуры.
Перед обучением модели классификации при помощи фильтра задаются алгоритм и правила токенизации текста через классы StringToWordVector() – фильтр для токенизации параметров и NGramTokenizer() – класс, преобразующий текст в N-граммы.
Затем полученный фильтр применяется к классификатору и вызывается метод классификатора buildClassifier() для обучения на тестовом наборе данных.
После этих манипуляций можно провести оценку полученной модели классификации на тестовом наборе данных.
Оценка модели происходит через класс Evaluation(). Необходимо передать в конструктор обучающую выборку, а в метод валидации – тестовую.
Для вывода оценочных характеристик модели используется метод класса toSummaryString():
public String Scoring(Classifier model, Instances traindataset, Instances testdataset) {
Evaluation scoring = null;
try {
scoring = new Evaluation(traindataset);
scoring.evaluateModel(model, testdataset);
} catch (Exception ex) {
Logger.getLogger(ModelGenerator.class.getName()).log(Level.SEVERE, null, ex);
}
return scoring.toSummaryString("", true);
}
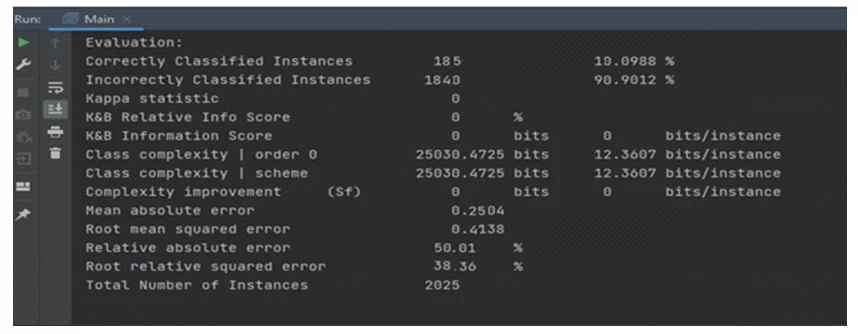
После того как точность модели будет посчитана удовлетворительной – модель можно сохранять и использовать:
public void saveModel(Classifier model, String path) {
try {
SerializationHelper.write(path, model);
} catch (Exception ex) {
Logger.getLogger(ModelGenerator.class.getName()).log(Level.SEVERE, null, ex);
}
}
public String Predict (Instances src, String path) {
String result = "";
Classifier classifier = null;
try {
classifier = (FilteredClassifier) SerializationHelper.read(path);
result = (String) classVal.elementAt((int) src.classifyInstance(src.firstInstance()));
} catch (Exception ex) {
Logger.getLogger(ModelClassifier.class.getName()).log(Level.SEVERE, null, ex);
result = "Classification error";
}
return result;
}
/////
Classifier cls = new Classifier();
String classname =cls.Predict(Filter.useFilter(cls.Instance(«Нежилое помещение&& Вид права: Собственность&& Доля в праве: н/д&& Тип объекта: помещение && Этаж: 1&& Этажность: 10&& », 0), filter), MODElPATH);
System.out.println("classname);
В результате обучения мы получили модель, подходящую для решения нашей задачи. По текстовому описанию объекта он был классифицирован как «Дом»:
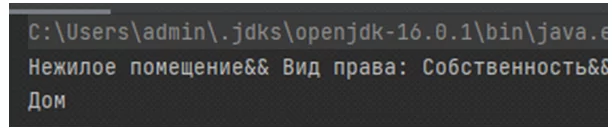
По результатам применения фреймворка можно сделать некоторые выводы.
Положительные:
- Быстродействие. Обучение модели фреймворка на выборке из 10000 произошло в интервале 1-2с.
- Гибкость. Параметры модели не привязаны к конкретному классу. Поэтому замена варианта алгоритма решается только переопределением класса модели.
Отрицательные:
- Сложность в использовании на больших объемах данных без изменения параметров виртуальной машины Java. Разработчики фреймворка в этом случае советуют использовать классы с возможностью дообучения, например NaiveBayesMultinomialUpdateable() в который через цикл добавляются данные для дообучения, что требует дополнительной обработки входных данных с использованием дополнительных библиотек.
Поставленную задачу фреймворк решил полностью, в дальнейшем мы попробуем использовать другие алгоритмы и поделимся своими наблюдениями. Спасибо за внимание!