/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
Для машинного обучения важно количество ядер и объём памяти. По сути, алгоритмы машинного обучения — это всего лишь куча линейной алгебры. Поэтому графические процессоры, рассчитанные на большое количество параллельных вычислений, так превосходят процессоры центральные.
Если тренируете модели не часто, то стоит обратить внимание на облачные сервисы. Вероятно, вам хватит возможностей, предоставляемых бесплатными тарифами. Однако даже если вы решите заплатить, это может оказаться выгодней, чем приобретать собственную карту.
При регулярном обучении моделей становится разумнее приобрести свой ускоритель. Основных производителей графических чипов два: Nvidia и AMD. Intel только выпускает на рынок свои первые дискретные видеокарты, а встроенная в центральные процессоры графика обладает малой производительностью.
Изначально библиотеки использовали технологию CUDA, присутствующую только на картах Nvidia. Благодаря этому Nvidia стала стандартом в машинном обучении и остается им сейчас. Позже в популярные библиотеки стали добавлять поддержку OpenCL для работы на картах AMD, но сообщество пользователей малочисленно и смело называйте себя энтузиастом, если решите заниматься обучением моделей на AMD.
Далее в статье будем рассматривать только Nvidia, т.к. кроме большого сообщества, которое уже столкнулось с множеством проблем до вас и готово подсказать решение, есть и другое важное преимущество. Для работы современных версий библиотек подойдут видеокарты архитектуры Maxwell и новее. Часть карт архитектуры Kepler также подходят.
На что еще следует обратить внимание:
- Объем видеопамяти.
Перемещение данных, из памяти и в неё, очень сильно ограничивает вычислительный процесс, поэтому чем больше памяти есть на карте, тем лучше. Недостаток памяти вынудит вас уменьшать Batch size, либо вовсе отказаться от задуманного.
Вот несколько ориентировочных рекомендаций объема видеопамяти:
- при использовании предобученных моделей в Transformer ≥ 11 ГБ;
- обучение больших моделей в Transformer или в сверточных нейронных сетях ≥ 24 ГБ;
- прототипирование нейронных сетей ≥ 10 ГБ;
- для Kaggle ≥ 8 ГБ;
- компьютерное зрение ≥ 10 ГБ.
Примеры нехватки видеопамяти можно посмотреть на изображениях ниже (нули в ячейках).
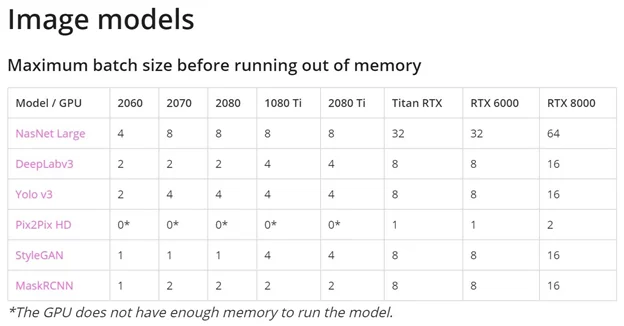
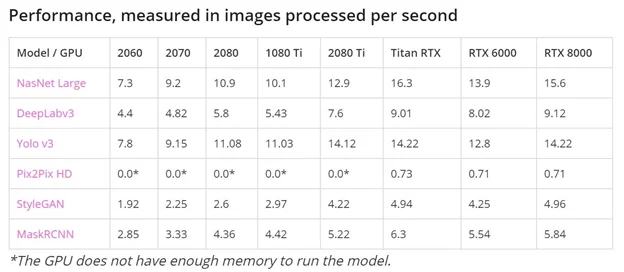
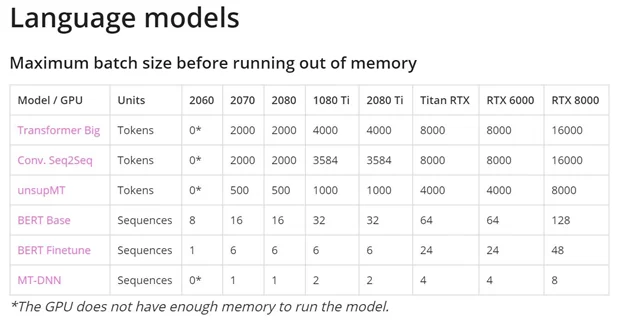
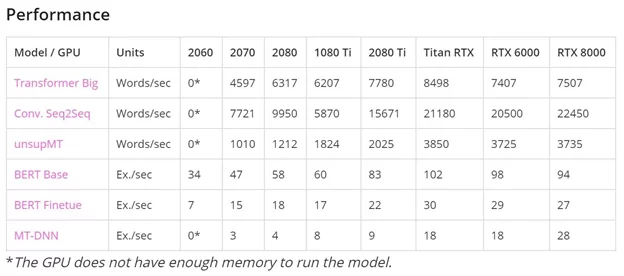
- Пропускная способность памяти.
В задачах Machine Learning / Artificial Intelligence пропускная способность видеопамяти зачастую имеет определяющее значение. По оценке многих специалистов, именно пропускная способность видеопамяти, а не вычислительная мощность графического процессора имеет ключевое значение в построении нейросетей. Например, при распознавании лиц объем высококачественных изображений, необходимых для обучения, чрезвычайно велик.
Если не указана пропускная способность памяти, то ее можно посчитать самостоятельно, как произведение шины памяти на ее эффективную частоту (в зависимости от типа памяти за 1 такт может передаваться объем данных характерный для нескольких тактов другой памяти), полученный результат разделите на 8.
- Чип графического процессора.
Чипы отличаются друг от друга количеством ядер CUDA и их архитектурой. Видеокарты серии RTX обладают также тензорными ядрами. Тензорные ядра — это специализированные блоки графического процессора для машинного обучения, значительно повышающие скорость тренировки моделей.
Тензорные ядра быстрее CUDA-ядер, потому что им требуется меньше циклов для операций с матрицами. Карты RTX поддерживают вычисления c низкой точностью (16 битные вместо 32), в таком режиме можно обучать модели вдвое большего размера используя тот же объем памяти.
Стоит ли использовать несколько видеокарт?
Использование нескольких видеокарт позволит увеличить скорость обучения:
- для сверточных нейронных сетей можно ожидать ускорения в 1,9x/2,8x/3,5x для двух, трех или четырех графических процессоров соответственно
- для рекуррентных сетей длина последовательности является наиболее важным параметром, а для NLP можно ожидать аналогичного или несколько худшего ускорения, чем для сверточных сетей
Еще одно преимущество использования нескольких GPU (даже если вы не распараллеливаете алгоритмы) заключается в том, что вы можете запускать несколько экспериментов отдельно на каждом графическом процессоре.
Хотите увидеть диаграмму? Она у меня есть
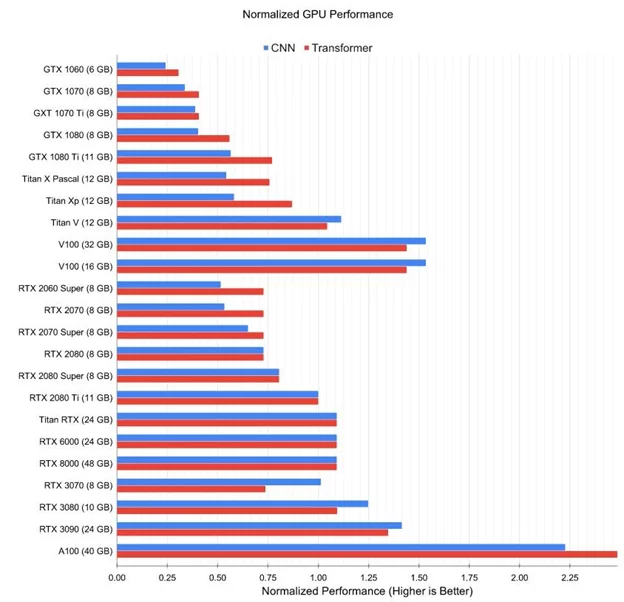
Буду признателен, если поделитесь своим опытом в комментариях