/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)
Время прочтения: 7 мин.
QlikView (далее — QV)– это BI-платформа, разработанная шведской компанией QlikTech, в настоящее время расположенной в штате Пенсильвания, США. Включена в группу лидеров магического квадранта Gartner поставщиков платформ Business Intelligence. В Сбере QV используется более пяти лет и на его базе разработано 100+ дэшбордов.
QV представляет из себя инструмент BI-аналитики, содержит широкий набор способов визуализации данных, имеет возможность создания собственных объектов-расширений, гибок в использовании. В данной и последующих статьях я постараюсь осветить основные принципы разработки проекта в QV, предоставить описание большинства объектов визуализации, а, так же, рассказать о некоторых tip and tricks, которые применял на практике в рамках своей деятельности. Надеюсь данная информация окажется полезной как для новичков, так и для опытных разработчиков.
Начнем с описания способа организации проекта и основных методов загрузки данных в QV.
Существует множество способов организации разработки и ведения проектов. Для примера будем рассматривать структуру из двух слоев данных и четырех слоев разработки. Такой метод позволяет четко разграничить этапы формирования конечного продукта, что обеспечивает благоприятные условия для хорошего понимания структуры проекта, мониторинга ошибок и совместного сопровождения несколькими разработчиками.
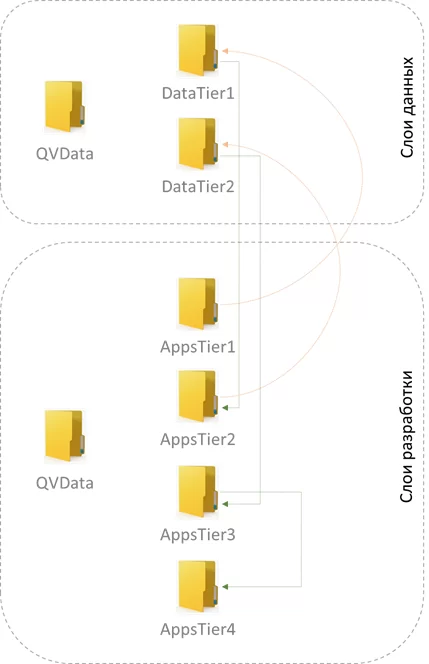
AppsTier1 – содержит файл-экстрактор формата *.qvw, который извлекает информацию из внешних источников, сохраняет ее в файлы *.qvd в папку DataTier1 по принципу один источник – один *.qvd, то есть, без их объединения.
DataTier1 – содержит *.qvd файлы – результат работы экстрактора. Так же могу быть созданы подкаталоги для локальных источников данных, например, *.csv, *.xslx, *.jpeg и другие.

В этом случае файл-экстрактор будет обрабатывать информацию из этих подкаталогов и сохранять *.qvd непосредственно в папку DataTier1.
Примечание. Вся информация в DataTier1 выгружается в неизменном виде, чтобы в случае ошибок можно было оценить корректность первоначальных данных.
AppsTier2 – содержит файл-трансформатор формата *.qvw, который осуществляет все необходимые преобразования в первоначальных данных, результат работы сохраняется в папку DataTier2 в формате *.qvd
AppsTier3 – слой для формирования модели данных, объединяет содержащиеся в папке *.qvd файлы, сохраняется в формате *.qwv. В самом файле можно создавать объекты для проверки созданной модели.
AppsTier4 – итоговая визуализация, именно этот файл выкладывается в публичный доступ на сервер. Грузится модель данных из AppsTier3, создаются объекты, если предполагается использование картинок, то они так же грузятся на этом слое.
Далее рассмотрим способы выгрузки данных из различных источников – в основном используются в AppsTier1.
Скрипт, как ни странно, пишется в редакторе скриптов — CTRL+E или:

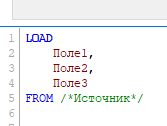
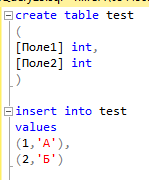
Данные в QV загружаются в виде таблиц и хранятся в самом файле *.qvw. Общий синтаксис по логике в большинстве случаев такой же как в SQL, но некоторые операторы отличаются:
Для начала попробуем способ загрузки Load Inline, фактически является аналогом SQL выражения:
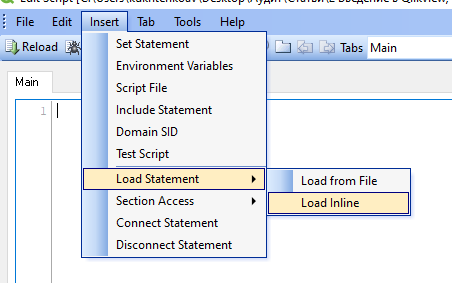
Выбираем пункт меню Insert->Load Statement->Load inline:
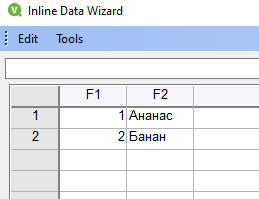
Появится таблица, в которую внесем свои данные:
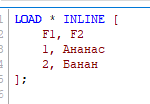
В редакторе скрипта автоматически сформируется код:
Попробуем его запустить – CTRL+R или:
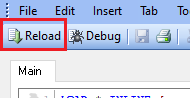
Нажимает CTRL+T для отображения структуры данных в нашем файле:
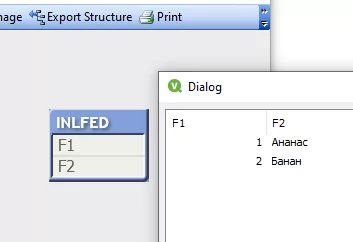
Наша таблица называется INLFED, имена полей – F1 и F2. Если нажать на ней правой кнопкой мыши и выбрать Preview, то увидим строки, которые в ней хранятся:
Мы можем отредактировать код, созданный мастером – присвоим имя таблице и поменяем названия полей:
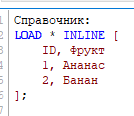
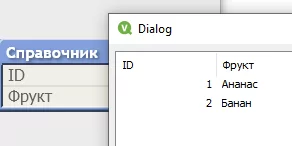
Пропишем код создания еще одной таблицы Справочник_2:
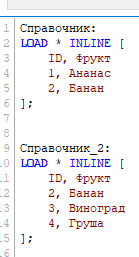
Кажется, что должно быть создано две таблицы со своим набором данных, но мы видим это:
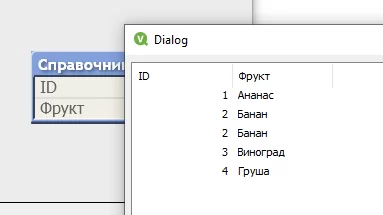
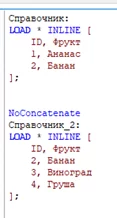
Одна таблица, пять строк, таблицы Справочник_2 не существует. Все дело в том, что QV объединяет таблицы с одинаковыми именами полей и их количеством, фактически делает автоматический Union All. В некоторых случаях нам может понадобиться отключить эту функцию, делается это выражением NoConcatenate перед загрузкой таблицы:
Немного модифицируем код, Справочник – таблица с фруктами, Справочник_цен – таблица с ценами:
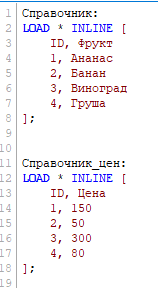
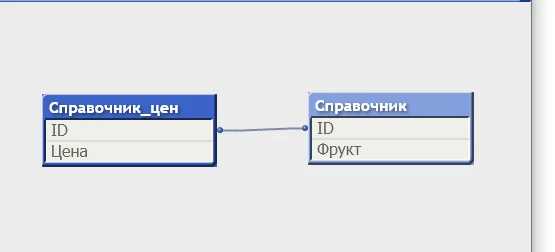
Поскольку теперь имена полей не совпадают, то созданы обе таблицы, но одно поле (ID) – общее ключ-поле. QV автоматически связывает таблицы по полям с одинаковыми именами, теперь с фруктом из справочника связана цена по соответственному номеру ID, это можно увидеть если создать объект Table Box:
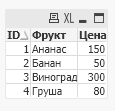
Load inline может использоваться в любом слое разработки.
Далее представлены другие способы загрузки данных в QV.
- Соединение через ODBC:
В редакторе скрипта выбираем Insert-Connect Statement
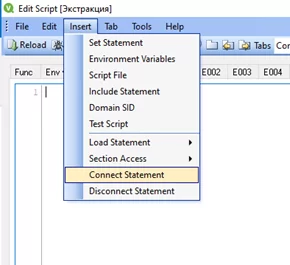
Выбираем необходимый источник данных, например, Hyperion:
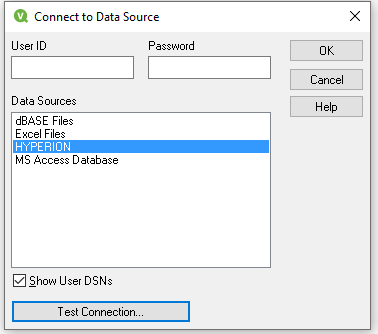
Автоматически будет создана строка подключения:
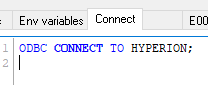
Если указать имя пользователя и пароль, то в строке подключения они будут зашифрованы:

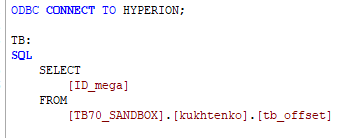
Далее пишем свой SQL запрос:
Загрузка из эксель-файла:

vXLSData – переменная, содержащая путь к xlsx файлу, если указано только имя файла, то он должен находиться в одной директории с qvw-экстрактором. В параметре «table is Лист1» указывается имя листа, из которого выгружается информация.
Так же можно загрузить данные из нескольких файлов в одну таблицу, например:

Сначала создается пустая таблица tmpData, затем в нее загружается каждый файл из директории PF.
FOR EACH vFileName in Filelist(vXLSData & ‘\PF\0*_*.xls*’) – инициализация цикла, для каждого файла в списке файлов из директории применяется код, указанный ниже.
Concatenate(tmpData) – добавление строк в таблицу tmpData (изначально пустая), своего рода, аналог Union All в SQL.
Загрузка из CSV-файла:

где embedded labels – файл содержит имена столбцов, delimiter is ‘,’ – разделитель запятая .
Способы в п.1-3 используются, как правило, в AppsTier1.
Можно использовать данные из уже загруженной в QV таблицы:
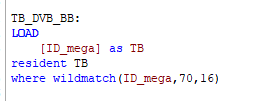
Слово resident обозначает загрузку из существующей таблицы, переименование поля необходимо, чтобы не было слияния таблиц, NoConcatenate не подходит, так как мы не хотим, образования синтетических ключей (о них напишу в следующих статьях).
Используется в любом слое разработки.
Binary загрузка:

Полностью загружает модель данных из другого *.qvw файла. В подавляющем большинстве случаев используется в AppsTier4, так как модель данных формируется на третьем слое, и ее, обычно, не нужно модифицировать.