/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 3 мин.
В процессе аудита из досье клиентов часто приходится выбирать определенные документы для дальнейшего анализа. Например, для оценки полноты выявления кредитными подразделениями банка сведений о сделках с недвижимым имуществом, подлежащих обязательному контролю в рамках ПОД/ФТ, нужны документы, удовлетворяющие следующим критериям:
- Документ является договором купли-продажи недвижимости (ДКП);
- Сумма сделки – от 3 млн. рублей и выше;
- Присутствует отметка о государственной регистрации.
В рамках данной задачи нам требовалось обработать документы более чем 3 тысяч клиентов. Задача усложнялась тем, что в электронном досье одного клиента могло находиться до ~200 папок, которые в целом могли содержать до ~1000 файлов. Естественно, что перебирать вручную эти папки с документами слишком трудозатратно.
Для решения задачи классификации документов из досье мы использовали имевшийся в нашем распоряжении инструмент на языке Python для распознавания и классификации документов, основанный на популярной библиотеке оптического распознавания символов в изображении tesserocr.
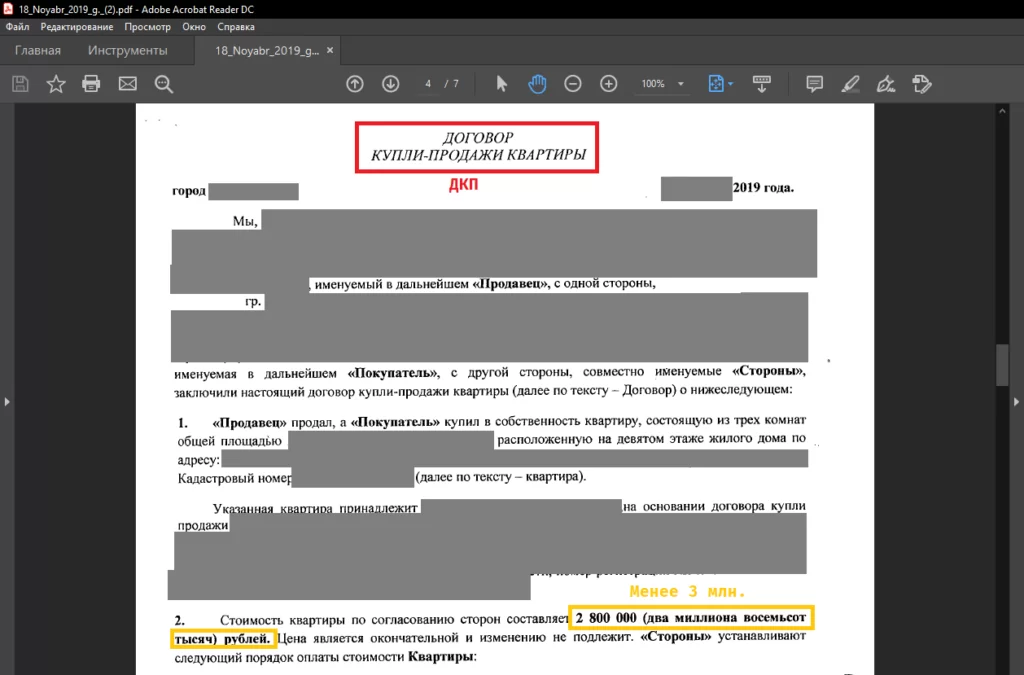
Однако, при апробации данной технологии выяснилось, что она не всегда корректно отображает результаты. Приведем пример ошибки:
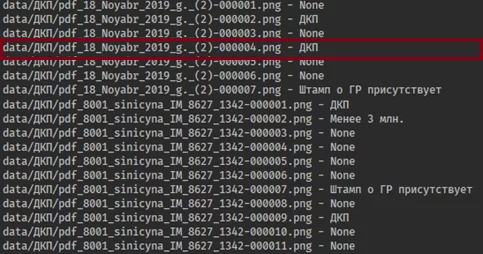
Так строка, отмеченная красной рамкой, показывает, что на странице 4 документа «18_Noyabr_2019_g._(2).pdf» обнаружены фразы, присущие договорам купли-продажи (ДКП). Вроде бы все корректно, однако при ручном рассмотрении документа было обнаружено, что на той же странице указана сумма договора (менее 3 млн. руб.), присутствие которой классификатор не отметил в результатах, хотя это было указано в словаре правил.
Т.е. при наличии на одной странице фраз, присущих двум классам, инструмент помечает всю страницу классом, фразы которого встречаются первыми в тексте, а остальные классы отбрасывает.
Таким образом, инструмент не выявит, что сумма сделки менее 3 млн. руб. и это приведет к ошибочному его отбору в итоговый формат и потребует дополнительной обработки данных.
Для решения этой проблемы мы доработали функцию, которая позволила использовать словарь принадлежности страниц к классам и помечать все найденные классы в документе:
def __classify_by_all_inclusions(variants, min_count=1):
"""
Определяем класс по самой ранней найденной строке
:param variants: Словарь с результатами поиска
:param min_count: Минимальное количество "результатов поиска" для каждого класса.
:return: Ключ выделенного класса
"""
inclusions = {x: variants[x][0].start for x in variants if len(variants[x]) >= min_count}
if len(inclusions) == 0:
return None
return ', '.join(x for x in inclusions.keys())
Результаты обработки приведенного выше договора теперь выглядят так:
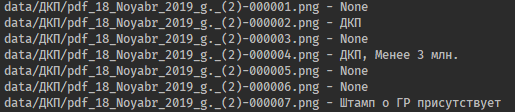
Таким образом, мы получили инструмент, который принимает на вход сканы документов в формате pdf и png, разбивает их на отдельные страницы, преобразует их с помощью Tesseract в текст и классифицирует их в соответствии с заданным набором правил, учитывая все классы страниц документа.