/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
В целях повышения эффективности мониторинга кредитного портфеля компании, мы предложили создать инструмент, который позволил бы выявлять заемщиков, уровень вероятности дефолта которых превышает уровень, определенный действующими риск-метриками. Средой программирования мы выбрали Python, так как в качестве исследуемых параметров заемщика использовались динамические данные, представленные в виде числовых рядов.
Данные для создания модели представляют из себя числовые ряды пяти параметров объекта — заемщика.
В процессе разработки требовалось определить наиболее эффективный метод обработки числовых рядов с целью его преобразования в метрику, дающую адекватную оценку объекта.
Существуют различные методы замены числового ряда значением, наиболее полно отражающим свойства ряда. Нами были выбраны три метода, наиболее подходящих для описываемой задачи: метод бета-коэффициента, использование функции «polyfit» библиотеки numpy языка Python, а также применения функции вычисления медианы «median» библиотеки numpy Python числового ряда.
В процессе разработки мы провели оценку эффективности применения каждого из данных методов:
1. Метод бета-коэффициентов.
Бета-коэффициент представляет из себя число, отражающее наклон линии тренда числового ряда. Функция вычисления Бета-коэффициента:
x = range(1,len(y)+1)
def var(X):
S = 0.0
SS = 0.0
for x in X:
S += x
SS += x*x
xbar = S/float(len(X))
return (SS - len(X) * xbar * xbar) / (len(X) -1.0)
def cov(X,Y):
n = len(X)
xbar = sum(X) / n
ybar = sum(Y) / n
return sum([(x-xbar)*(y-ybar) for x,y in zip(X,Y)])/(n-1)
def beta(x,y):
return cov(x,y)/var(x)
Применение алгоритма вычисления бета-коэффициента, позволило избавиться от числовых рядов. Данные выборки преобразованы в формат, приемлемый для создания модели. В качестве модели был выбран метод градиентного бустинга для обучения с учителем. В качестве учителя выступали случаи дефолтов в течение года, прошедшего после периода выгрузки данных для обучающей выборки. Оценка качества модели производилась с помощью метрики ROC_AUC.
Результат оценки качества модели метрикой ROC_AUC, созданной на выборке с обработкой числовых рядов с применением бета-коэффициента.
ROC_AUC = 0.85 — не плохой результат для решения задачи. График зависимости значения метрики ROC_AUC от количества объектов в обучающей выборке, созданной на выборке с обработкой числовых рядов с помощью алгоритма вычисления бета-коэффициента:
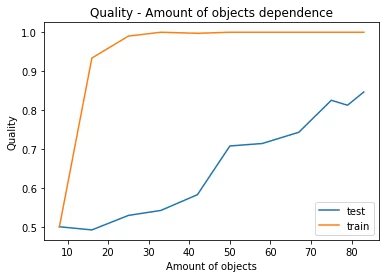
2. Использование функции polyfit() библиотеки numpy языка Python. Описание функции polyfit():
numpy.polyfit(x, y, deg, rcond=None, full=False, w=None, cov=False)Функцию можно использовать следующим образом:
def trenddetector(list_of_index,array_of_data, order=1):
result = np.polyfit(list_of_index, list(data), order)
slope = result[-1]
return float(slope)
Функция возвращает значение, которое указывает на Тренд ваших данных. Значения, возвращаемые данной функцией, являются коэффициентами полинома. Путем подбора можно легко определить оптимальный порог смещения, наиболее подходящий к обучающей выборке, и задать его в качестве параметра.
Значения метрики ROC_AUC в зависимости от параметра функции:
| Значение параметра смещения | 0 | -1 | -2 |
| Значение ROC_AUC | 0,83 | 0,88 | 0,83 |
Значение метрики ROC_AUC с применением функции polyfit оказалось выше значения метрики ROC_AUC с применением алгоритма вычисления бета-коэффициента, следовательно, для обработки числовых рядов исходной выборки на данном этапе лучше использовать функцию polyfit. График зависимости значения метрики ROC_AUC от количества объектов в обучающей выборке, созданной на выборке с обработкой числовых рядов функцией polyfit:
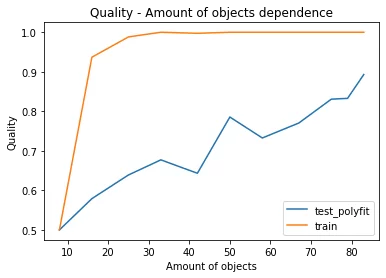
3. Применение метода вычислений медианы числового ряда.
В предыдущих примерах использовался довольно сложный функционал для обработки числовых рядов, основанный на определении линии тренда, являющейся векторной величиной, с помощью вычисления бета-коэффициентов и коэффициентов полинома числового ряда. Попробуем изменить подходы к обработке числового ряда, воспользуемся простейшей функцией из библиотеки numpy median, которая рассчитывает скалярное значение медианы числового ряда.
Для корректного применения функции median, предварительно вычтем среднее значение числового ряда из всех значений ряда
md= np.median(data)-data.mean()
При расчете медианы получаем скалярное значение, которое определяет тренд числового ряда. Если значение медианы положительное – тренд восходящий, отрицательное – тренд нисходящий, равное нулю – тренд отсутствует. В дальнейшем проводилась нормализация значений данного параметра.
Результат оценки качества модели метрикой ROC_AUC, созданной на выборке с обработкой числовых рядов функцией median.
ROC_AUC = 0.93 График зависимости значения метрики ROC_AUC модели от количества объектов в обучающей выборке, созданной на выборке с обработкой числовых рядов функцией median:
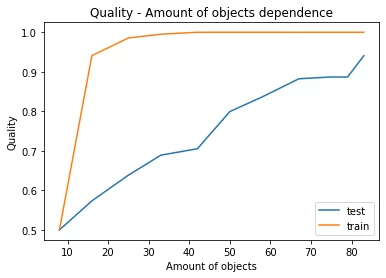
Выводы: Результат проведенных исследований методов обработки числовых рядов:
| Метод обработки числового ряда | Бета-коэффициент | Функция polyfit | Функция median |
| Значение метрики ROC_AUC модели | 0,85 | 0,88 | 0,93 |
Обобщенный график зависимостей значений метрик ROC_AUC моделей от количества объектов в обучающей выборке, созданной на выборках с обработкой числовых рядов вышеописанными методами.
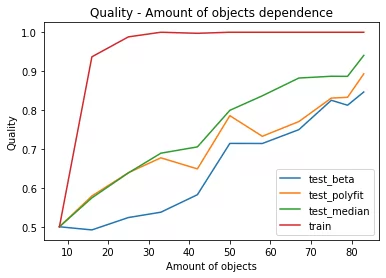
Наилучшим методом обработки числовых рядов для решения поставленной задачи оказался метод с использованием функции median. Значение метрики ROC_AUC = 0.93, полученной с его использованием, является очень хорошим результатом.
При подготовке обучающих выборок были использованы методы их балансировки, в т.ч. метод undersampling. Однако, обращаем внимание, что при достаточно сильной разбалансированности обучающей выборки метод undersampling следует исключить, так как высока вероятность переобучения модели, что приведет к ошибкам оценки риска дефолта заемщиков на этапе эксплуатации модели. Результатом проделанной нами работы стала модель, позволяющая существенно повысить уровень рискориентированности и оперативно готовить информацию о необходимости принятия срочных мер по снижению рисков кредитного портфеля.