/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 7 мин.
Веб-скрапинг — это распространенный и эффективный способ автоматизированного сбора данных с веб-ресурсов. Это бывает необходимо для самых разных задач от АНАЛИЗА цен в магазинах конкурентов, до сбора данных для моделей машинного обучения. Для решения этой задачи существует множество библиотек, обладающих различными возможностями, со своими плюсами и минусами. При этом автоматизированный процесс обычно решает две разные задачи: осуществляет запросы для получения веб-страничек, и непосредственно разбор полученных страниц для извлечения данных.
Пожалуй, наиболее популярный подход для решения этой задачи (или во всяком случае, наиболее широко описанный) — это связка requests и BeautifulSoup. Однако, относительно недавно появился requests-html — новый проект, написанный Кеннетом Рейцем (Kenneth Reitz), автором упомянутой выше библиотеки requests. Он известен как автор легких в использовании и интуитивно понятных библиотек, таких как, например, requests и pipenv. Считаю это уже сама по себе хорошая рекомендация, для того, чтобы обратить внимание на данный инструмент. Также сразу отмечу важное преимущество requests-html — поддержку JavaScript! Также поддерживаются селекторы CSS и XPath. Возможность использования асинхронного кода. Обо всем этом ниже.
Установка
Первое что нужно сделать — установить requests-html. Самый простой способ:
pip install requests-htmlТребуется: Python >=3.6.0.
Начало работы
Рассмотрим простой пример. Если вы знакомы с requests интерфейс покажется знакомым.
from requests_html import HTMLSession
session = HTMLSession()
r = session.get('https://www.novostibankrotstva.ru/')
В случае успешного получения страницы, переменная r будет содержать <Response [200]>.
Очень часто требуется получить ссылки, имеющиеся на странице. Сделать это можно очень просто, r.html.links содержит все ссылки на странице в виде множества. Ссылки при этом сохранены в том виде, как представлены на странице. Если на странице используются относительные ссылки, получить из них абсолютные можно самому, например, воспользовавшись функцией urljoin из библиотеки urllib. (Кстати r.html.base_url содержит базовый URL). Но requests-html уже позаботился об этом, r.html.absolute_links содержит абсолютные ссылки. Таким образом r.html.links будет содержать что-то вроде (я сократил реальную выдачу):
{'http://www.bankrot.org/forums/',
'http://www.bankrot.org/pages/consultation/',
'https://www.novostibankrotstva.ru/',
'https://www.novostibankrotstva.ru/category/banki/',
'https://www.novostibankrotstva.ru/category/bankrotstvo-fizlits-2/',
'https://www.novostibankrotstva.ru/category/bankrotstvo-kompanij/',
'https://www.novostibankrotstva.ru/category/bez-rubriki/',
'https://www.novostibankrotstva.ru/category/poleznoe/',
'https://www.novostibankrotstva.ru/category/pravovye-voprosy/',
'https://www.novostibankrotstva.ru/page/1090/',
'https://www.novostibankrotstva.ru/page/2/',
'https://www.novostibankrotstva.ru/page/3/',
'https://www.novostibankrotstva.ru/page/4/'}
При необходимости можно получить исходный код страницы через r.html.html. Но обычно вся страница не требуется. Допустим, мы хотим получить что-то из шапки сайта:
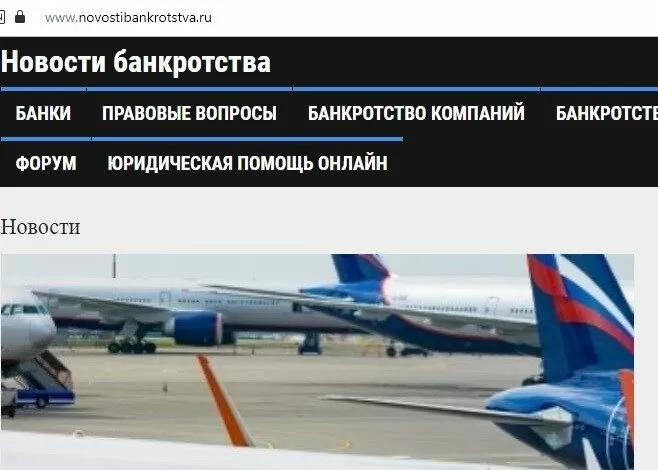
Например — заголовок сайта.
Это можно сделать, найдя интересующий элемент в исходном коде, но проще сделать, кликнув на интересующий элемент в браузере правой кнопкой мышки, и выбрав “исследовать элемент”. Это в данном случае:
<h1 id="logo" class="text-logo" itemprop="headline">\n<a href="https://www.novostibankrotstva.ru">Новости банкротства</a>\n</h1>Найти интересующий элемент можно используя XPath или CSS селекторы. В данном случае это проще всего сделать, используя id элемента. С использованием CSS селектора это можно сделать так:
logo = r.html.find('#logo', first=True)Хотя, поскольку h1 элемент на странице всего один, можно найти и по нему:
logo = r.html.find('h1', first=True)Или тоже самое с использованием XPath:
logo = r.html.xpath('//h1', first=True)Параметр first=True — указывает, что нужно вернуть только первый из найденных элементов, удовлетворяющих условию поиска.
Далее можно, например, получить текст заголовка (т.е. текст между тэгами <h1></h1>):
print(logo.text)Выведет: «Новости банкротства».
Также можно получить исходный код данного элемента через logo.html. Или его атрибуты через logo.attrs:
{'id': 'logo', 'class': ('text-logo',), 'itemprop': 'headline'}Далее, допустим, мы хотим получить все ссылки на статьи с данной страницы. Из исходного кода страницы можно понять, что интересующая нас информация содержится в конструкциях подобного вида:
<h2 class="title front-view-title"><a href="https://www.novostibankrotstva.ru/2021/01/27/otvetstvennost-za-kriminal-v-bankrotstve-sobralis-uzhestochit/" title="Ответственность за криминал в банкротстве собрались ужесточить">Ответственность за криминал в банкротстве собрались ужесточить</a></h2>Найти все такие элементы на странице можно, используя названия классов и CSS селекторы:
titles_html = r.html.find('.title.front-view-title')Теперь titles_html содержит массив подобных элементов. Преобразуем их в словарь вида: {заголовок: ссылка}.
titles = {t.text: t.links for t in titles_html}Поддержка JavaScript
Рассмотрим пример страницы содержащий JavaScript. Для примера возьмем простейший случай, но с которым BeautifulSoup, например, уже не справится.
<html>
<head>
<meta charset="utf-8">
<title>Just a JavaScript sample</title>
</head>
<body>
<h1>Просто пример страницы с JavaScript</h1>
<script type="text/javascript">
document.write("<h2>Текущая дата</h2>");
document.write("<p>" + Date() + "</p>");
</script>
</body>
</html>
Здесь просто часть текста, включая текущую дату, выводится средствами JavaScript.
Используем уже знакомый код.
from requests_html import HTMLSession
session = HTMLSession()
r = session.get('https://www.zhev.com/testjavascript.html')
print(r.html.text)
В результате получим:
Just a JavaScript sample
Просто пример страницы с JavaScript
document.write("<h2>Текущая дата</h2>"); document.write("<p>" + Date() + "</p>");
Не слишком впечатляет. Дата не видна, виден только код javascript. Чтобы это исправить и увидеть страницу так, как она отображается в браузере, используем метод render():
r.html.render()
print(r.html.html)
Данный метод перезагружает страницу в Chromium, и заменяет HTML-контент версией с выполненным JavaScript.
Первый запуск метода render() может занять много времени, т.к. скачивается Chromium. Но это происходит только один раз.
Теперь print(r.html.text) выдаст:
<html><head>
<meta charset="utf-8">
<title>Just a JavaScript sample</title>
</head>
<body>
<h1>Просто пример страницы с JavaScript</h1>
<script type="text/javascript">
document.write("<h2>Текущая дата</h2>");
document.write("<p>" + Date() + "</p>");
</script><h2>Текущая дата</h2><p>Wed Jan 27 2021 13:36:35 GMT+0300 (Moscow Standard Time)</p>
</body></html>
Т.е. мы можем видеть текст так, как он отображается в браузере.
Нужно отметить, что, к сожалению, метод render() не работает при выполнении в Jupyter notebook.
Еще пример с JavaScript.
Сайт с дизайном “кирпичная кладка”, новые посты подгружаются при прокрутке страницы вниз. Соберем заголовки постов и ссылки на них. Эти заголовки и ссылки имеют формат:
<h4 class="post-title entry-title"><a href="https://www.iwannabechef.ru/dddd/dd/dd/sometext/">Заголовок</a></h4>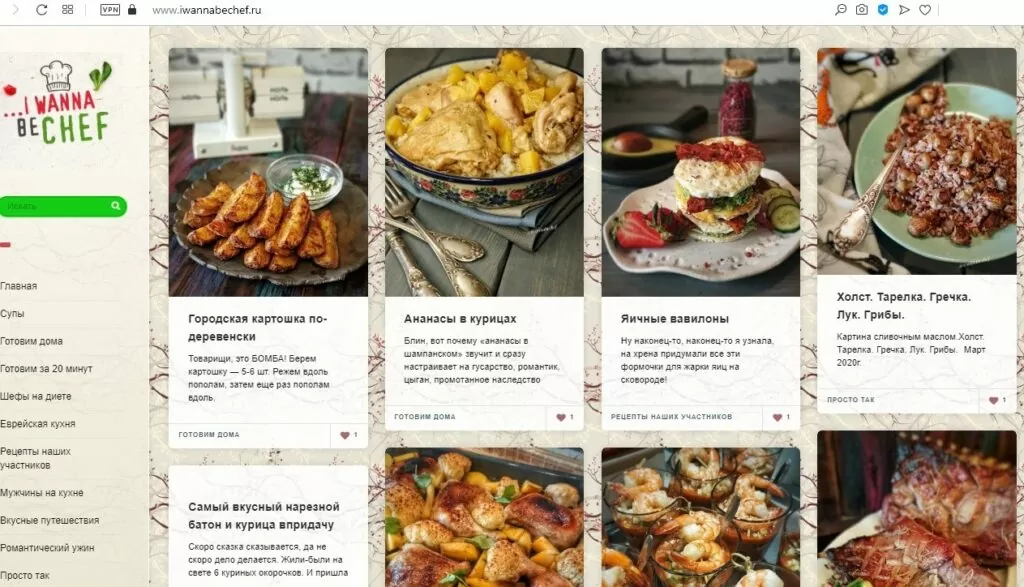
from requests_html import HTMLSession
session = HTMLSession()
r = session.get('https://www.iwannabechef.ru')
r.html.render()
titles = r.html.find('.post-title.entry-title')
for title in titles:
print(title.text, ':', title.absolute_links.pop())
Загрузили страницу, исполнили и отобразили JavaScript, нашли ссылки. Но на странице найдено только 10 ссылок.
- Городская картошка по-деревенски: https://www.iwannabechef.ru/2020/05/07/gorodskaya-kartoshka-po-derevenski-tovarishhi-eto-bomba/
- Ананасы в курицах: https://www.iwannabechef.ru/2020/05/05/ananasy-v-kuritsah/
- Яичные вавилоны: https://www.iwannabechef.ru/2020/04/01/yaichnye-vavilony/
- Холст. Тарелка. Гречка. Лук. Грибы: https://www.iwannabechef.ru/2020/03/24/holst-tarelka-grechka-luk-griby/
- Медовое каре ягненка: https://www.iwannabechef.ru/2020/03/19/medovoe-kare-yagnenka/
- Бедра на стыке культур: https://www.iwannabechef.ru/2020/03/10/bedra-na-styke-kultur/
- Гаспачо с чесночной креветкой: https://www.iwannabechef.ru/2020/02/15/gaspacho-s-chesnochnoj-krevetkoj/
- Самый вкусный нарезной батон и курица впридачу : https://www.iwannabechef.ru/2020/02/08/samyj-vkusnyj-nareznoj-baton-i-kuritsa-vpridachu/
- Классический крем-брюле: https://www.iwannabechef.ru/2020/01/22/klassicheskij-krem-bryule/
- Кабачки под шубой: https://www.iwannabechef.ru/2020/01/10/kabachki-pod-shuboj/
Для того, чтобы получить больше ссылок потребуются дополнительные параметры при вызове render().
r.html.render(sleep=1, scrolldown=20)
titles = r.html.find('.post-title.entry-title')
for title in titles:
print(title.text, ':', title.absolute_links.pop())
Теперь у нас уже 20 ссылок:
- Городская картошка по-деревенски: https://www.iwannabechef.ru/2020/05/07/gorodskaya-kartoshka-po-derevenski-tovarishhi-eto-bomba/
- Ананасы в курицах: https://www.iwannabechef.ru/2020/05/05/ananasy-v-kuritsah/
- Яичные вавилоны: https://www.iwannabechef.ru/2020/04/01/yaichnye-vavilony/
- Холст. Тарелка. Гречка. Лук. Грибы: https://www.iwannabechef.ru/2020/03/24/holst-tarelka-grechka-luk-griby/
- Медовое каре ягненка: https://www.iwannabechef.ru/2020/03/19/medovoe-kare-yagnenka/
- Бедра на стыке культур: https://www.iwannabechef.ru/2020/03/10/bedra-na-styke-kultur/
- Гаспачо с чесночной креветкой: https://www.iwannabechef.ru/2020/02/15/gaspacho-s-chesnochnoj-krevetkoj/
- Самый вкусный нарезной батон и курица впридачу: https://www.iwannabechef.ru/2020/02/08/samyj-vkusnyj-nareznoj-baton-i-kuritsa-vpridachu/
- Классический крем-брюле: https://www.iwannabechef.ru/2020/01/22/klassicheskij-krem-bryule/
- Кабачки под шубой: https://www.iwannabechef.ru/2020/01/10/kabachki-pod-shuboj/
- Cёмга в пьяной свёкле: https://www.iwannabechef.ru/2019/12/10/cyomga-v-pyanoj-svyokle/
- Курица с оливками и лимоном: https://www.iwannabechef.ru/2019/11/27/kuritsa-s-olivkami-i-limonom/
- Цимес из тыквы в красном вине: https://www.iwannabechef.ru/2019/11/06/tsimes-iz-tykvy-v-krasnom-vine/
- Жаркое в духовке: https://www.iwannabechef.ru/2019/11/01/zharkoe-v-duhovke/
- Тейглах: https://www.iwannabechef.ru/2019/09/30/tejglah/
- Курица в тыквенном соусе: https://www.iwannabechef.ru/2019/09/25/kuritsa-v-tykvennom-souse/
- Жаркое в лаваше: https://www.iwannabechef.ru/2019/09/12/zharkoe-v-lavashe/
- Ленивый рассольник: https://www.iwannabechef.ru/2019/09/05/lenivyj-rassolnik-2/
- Утиная грудка: https://www.iwannabechef.ru/2019/09/03/utinaya-grudka/
- Топор с гарниром: https://www.iwannabechef.ru/2019/08/31/topor-s-garnirom/
Параметр scrolldown указывает количество раз на которое нужно прокрутить страницу, после ожидания sleep секунд.
У метода render() есть также и другие параметры, например, параметр script позволяет добавить свой код на JavaScript, который будет исполнен после загрузки страницы.
Использование без Requests
Я начал рассматривать библиотеку с запросов к веб-страницам. Но предусмотрена возможность парсить и просто html текст, полученный как-то иначе.
from requests_html import HTML
doc = """<html><body>
<h1>Какой-то заголовок</h1><p>Первый параграф.</p>
<p>Еще один параграф со <a href='https://httpbin.org'>ссылкой</a>.</p>
</body></html>"""
html = HTML(html=doc)
html.links
Т.е. вместо HTMLSession используем просто HTML.
Сравнение с конкурентами
Отдельно следовало бы провести сравнение requests-html основными конкурентами. Особенно интересно было бы сравнить скорость работы. Пока могу только субъективно оценить, что скорость примерно на уровне lxml, и точно быстрее чем чистый BeautifulSoup и html5lib. Scrapy конечно будет быстрее, но он гораздо сложнее в использовании.
Пожалуй, в сравнении в BeautifulSoup недостает только метода prettify(), который помогает справиться с плохой разметкой.
Вывод
Думаю, для большинства задач requests-html представляется оптимальным выбором в настоящий момент. Простой и интуитивно понятный интерфейс, хорошая скорость, поддержка JavaScript, возможность использовать асинхронный код, а также ряд других возможностей позволяют заключить, что для большинства задач requests-html является оптимальным выбором в настоящий момент.