/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 7 мин.
Часто в нашей работе приходится сталкиваться с обработкой данных для последующего исследования и анализа. Зачастую алгоритм обработки очень прост: найти вхождения подстроки в строку, проставить флаги в исходном дата фрейме в зависимости от условий, подсчитать количественные характеристики или метрики.
Однако часто происходит так, что при первом написании алгоритм работает долго, несмотря на простоту задачи. Сегодня хотелось бы поговорить о полезных приемах для ускорения обработки. Напишем несколько подходов к решению одной задачи и сравним время выполнения.
Рассмотрим такую задачу есть 2 таблицы: в одной находится информация с запросами, где в одном столбце находится идентификатор клиента, а в другом тело запроса; в другой таблице находятся список идентификаторов запросов, которые указываются в теле запроса из предыдущей таблицы.
Пример
Первая табличка выглядит так (отобрали интересующий столбец):
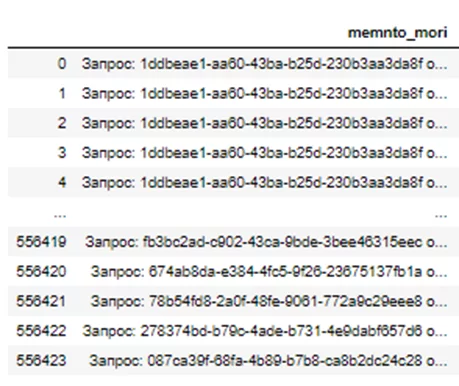
Пример содержания строки: «Запрос: 43ba-b25d -1ddbeae1-aa60-230b3aa3da8f от 1823-10-06. Нотариус: Иванов Иван Иванович», однако некоторые строки не типизированы и могут представлять из себя однострочный запрос: «H18B11zap04500057-007438459-00-071119.rtf»
Вторая табличка выглядит так (также интересующий столбец):

Задача была в том, чтобы найти вхождения строки из второй таблицы в первую. В первой таблице 556424 строк, во второй 496425 строк.
Казалось бы, задача легкая и понятная. Но так ли это? Давайте разбираться.
Для начала, как и в любой подобной обработке, необходимо импортировать нужные библиотеки, считать таблички и добавить колонку с флагами (по умолчанию равную 0).
import pandas as pd
from tqdm import tqdm
import numpy as np
#загрузка таблиц
aim_df = pd.read_excel('Таблица 1.xlsx')
search_df = pd.read_excel('Таблица 2.xlsx')
#добавление столбца с флагом (по умолчанию у всех 0)
aim_df['flag'] = 0
Теперь переходим к самому интересному – написанию алгоритма поиска. Первое что приходит на ум — написать «в лоб» алгоритм для поиска подстроки в строке, и затем, там, где совпадение было, выставить флаг 1.
find_key = search_df['GUID']
for row in tqdm(range(1, aim_df.shape[0])):
for key in find_key:
if str(key) in aim_df.iloc[row][' memnto_mori ']:
aim_df.loc[row, 'flag'] = 1
Вариант работает очень долго, приблизительно 12988 часов или 541 день.

Рассуждая можно прийти к выводу, что в нашей табличке скорее всего есть дубли, что увеличивает время перебора. Их лучше удалить.
search_list = list(set([a.strip() for a in search_df['GUID']]))Также в наших таблицах очень много информации, которая для обработки нам не нужна и для облегчения вычислений можно выделить интересующий нас столбец из первой таблицы
mem = list(set(aim_df[' memnto_mori ']))также в нашей получившейся переменной все еще много лишнего, из нее нам нужен только номер запроса, давайте и выделим его:
mem_filter = {}
for i in range(len(mem)):
if mem[i].find('Запрос: ') != -1:
mem_filter[mem[i][mem[i].find(': ') + 2: mem[i].find(' от ')]] = mem[i]
else:
mem_filter[mem[i]] = mem[i]
Получаем на выходе словарик, где ключ – очищенный номер, а значение – исходная строка. Теперь мы можем непосредственно сравнить словарик с исходным списком из второй таблицы:
Сравниваем два листа, ищем в целевом столбце вхождения target, при нахождении добавляем в словарь и ставим 1
keys = mem_filter.keys()
mem_find = {}
for s in search_list:
if s in keys:
mem_find[s] = 1
Затем сливаем наши полученные результаты таким образом, чтобы на выходе получить словарь, где ключ – исходная строка запроса, в которой нашлось вхождение, а значение – 1. Далее в результат записываем значение словаря фильтр (исходную строку) и присваиваем 1.
result = {}
for m in mem_find.keys():
result[mem_filter[m]] = mem_find[m]
Дальше логично просто пройтись по всей первой табличке и если значение есть в result – ставим 1, если нет – 0
for row in tqdm(range(1, aim_df.shape[0])):
if aim_df.iloc[row][ ' memnto_mori '] in result:
aim_df.loc[row, 'flag'] = 1
Вроде бы все хорошо, однако время работы все еще достаточно большое – около 1,5 часов.

Однако есть одна очень полезная функция, для который мы и делали именно словарик, а не просто список – map(), которая возвращает колонку с новыми значениями (в нашем случае – flag).
aim_df['flag'] = aim_df[' memnto_mori '].map(result)
#в оставшиеся места, вместо Nan вставляем 0
aim_df['flag'].fillna(0, inplace = True)
#для красоты делаем колонку int
aim_df.astype({'flag': 'int64'})
На весь код таким решением:

Выполняется данный код всего за несколько секунд. Эта функция применяется к колонке датафрейма по которому делаем фильтр, аргументом функции является словарь, где ключ – значение, которое встречается в колонке, к которой применяется функция, а значение – значение, которое будет возвращаться в новую колонку.
Код, который представлен выше выполняется быстро и понятен, однако содержит много строчек и «лишних» переменных. Есть более лаконичное и короткое решение. Нам понадобится опять словарь исходных – очищенных строк, но только теперь ключом будет строка, а значением – очищенная строка. Совсем необязательно создавать словарь, можно реализовать через лямбда функцию, только необходимо применить их с большей осторожностью, так как они являются не просто читаемыми для других. Но давайте воспользуемся лямбда функцией, а результат запишем сразу в новый столбец в первой таблице, в нем будут содержаться очищенные значения:
aim_df['GUID_from_string'] = aim_df['memnto_mori'].map(lambda x: x.split(' ')[1] if x.find('Запрос: ') != -1 else x) Затем вместо построчных сравнений вхождения подстроки и создания дополнительного словаря можно просто применить функцию merge:
res_df = pd.merge(aim_df, search_df['GUID'], how='left', left_on='GUID_from_string', right_on='GUID')
На выходе получаем res_df:
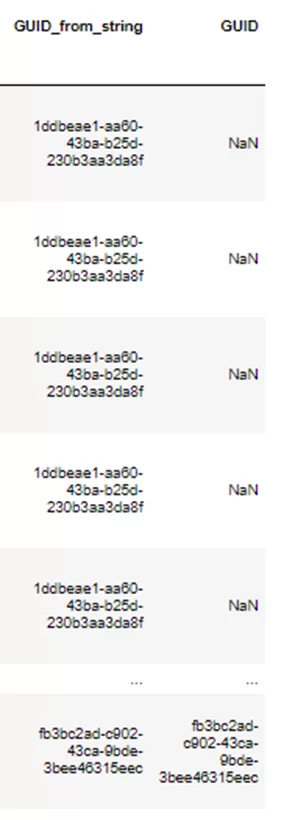
То есть напротив значений, которые нашлись во второй таблице — будут значения, а где не нашлись – Nan. Время выполнения такого кода занимает несколько секунд, а размер составляет всего 2 строки.
Pandas.merge() – базовая функция для всех слияний или объединений таблиц. Также помимо этой функции существует функция join(). Merge можно использовать двумя способами: df1.merge(right = df2) или pandas.merge(left=df1, right=df2), а join – df1.join(df2,…).
Основные различия между merge и join заключаются в следующих пунктах:
- Поиск по правой таблице — df1.join(df2) всегда осуществляется на основании индекса. В то время как df1.merge(df2) позволяет присоединить по одному или нескольким столбцам df2 или по индексу.
- Поиск по левой таблице — по умолчанию df1.join(df2) использует индекс df1.
- df1.join(df2) по умолчанию делает левое соединение в то время как merge создает внутреннее соединение (inner join) по умолчанию, этот параметр можно настроить у обеих функций.
В целом эти 2 функции взаимозаменяемы, по времени исполнения они не отличаются, главное помнить о небольших различиях и использовать их правильно.
Таким образом, зная некоторые нюансы использования памяти Python, что словари на поиск работают всегда в разы быстрее, чем поиск по списку, а также нескольких полезных функций, время выполнения нашего код сократилось более чем в 500 раз.
Некоторые шаги можно объединить для уменьшения количества кода. Мной было рассмотрено несколько вариантов решения для полного понимания процесса и наглядности.
P.S если в столбце к которому применяем функцию map() будут значения, которых не будет в словаре, то в новом столбце будет Nan. Их легко заменить на нужные значения функцией fillna.