/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 6 мин.
Python – это интерпретируемый язык. Это означает, что код Python не компилируется напрямую в машинный код, а интерпретируется в режиме реального времени другой программой, называемой интерпретатором (в большинстве случаев CPython).
Это одна из причин, почему Python обеспечивает такую большую гибкость (динамическая типизация, работает везде и т.д.) по сравнению с компилируемыми языками. Однако именно поэтому Python медленный.
На самом деле существует несколько способов разогнать код на Python. Самыми популярными из них являются:
- использование Cython;
- использование PyPy;
- расширение Python с использованием C/C++.
Cython позволяет напрямую вызывать библиотечные функции C и эффективно работать с большими данными. Но обладает и минусами, главными из которых являются «свой» синтаксис, который предполагает знание C, и сложности в отладке. Код Python можно ускорить, написав нативный код, но тогда использование Cython не даст прироста скорости близкой к известному PyPy.
PyPy использует технику, известную как мета-трассировка, которая преобразует интерпретатор в компилятор трассировки JIT (Just-in-time), т.е. выполнение кода включает в себя компиляцию. PyPy имеет высокую скорость, которая не уступает Cython, рационально обращается с памятью, но несмотря на совместимость со многими базовыми библиотеками Python, PyPy поддерживает далеко не все из них, и к тому же для выполнения Python-кода могут потребоваться его некоторые изменения.
Расширение Python с помощью C/C++ дает возможность добавлять новые встроенные модули в Python без труда, однако требует умения программировать на C. С помощью таких модулей можно реализовывать новые встроенные типы объектов и вызывать библиотечные функции C.
Вышеупомянутые методы требуют использования языка, отличного от Python, или компиляции кода для его работы с Python. Эти варианты не самые удобные и не всегда просты в настройке. Возникает вопрос, как быть тем, кто абсолютно не знаком с C/C++ и не желает такого знакомства. К счастью, выход есть всегда, и пакет Numba — прекрасное решение, которое поможет значительно ускорить код, не отказываясь от дружелюбного Python.
Numba & JIT compilation
Numba – это компилятор с открытым исходным кодом, использующий подход LLVM (Low Level Virtual Machine). Numba использует компиляцию JIT (Just-in-time) – это означает, что компиляция выполняется во время выполнения кода Python, а не раньше!
Установлю Numba с помощью pip.
pip install numbaРассмотрю простой пример с проверкой числа на простоту.
Для использования Numba нужно просто импортировать декоратор (@njit) и добавить его к функции.
import math
#Импортируем njit
from numba import njit
def isPrime(n):
for i in range(2, int(math.sqrt(n)+1)):
if n % i == 0:
return False
return n>1
def test(n):
for i in range(n):
isPrime(n)
#добавим numba декоратор, чтобы функция работала быстрее
@njit
def isPrime(n):
for i in range(2, int(math.sqrt(n)+1)):
if n % i == 0:
return False;
return n>1;
@njit
def test_with_numba(n):
for i in range(n):
isPrime(n)
Посмотрю на результаты:
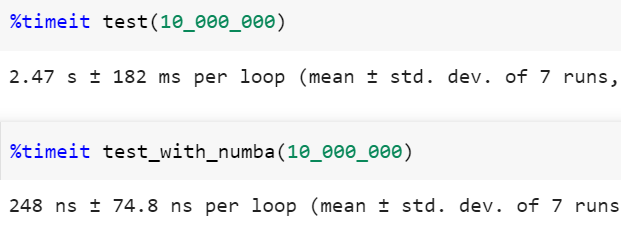
В таком представлении Numba смотрится слишком хорошим, чтобы быть правдой. Но у него наверняка есть свои недостатки.
Первый вызов функции, декорированной с использованием Numba, запускается долго. Это связано с тем, что Numba пытается выяснить типы параметров и скомпилировать функцию при первом её выполнении. Чтобы уменьшить затраты времени на компиляцию при каждом вызове программы на Python, можно записать результат компиляции функции в файловый кэш. Сделать это можно, добавив в аргументы к декоратору @njit(cache=True), и тогда последующие запуски кода будут быстрыми.
Не весь код на Python будет скомпилирован с Numba. Например, если вы используете смешанные типы для одной и той же переменной или для элементов списка, вы получите ошибку. Для контроля типов переменных в numba есть способ, позволяющий сразу определить тип функции и типы входящих переменных, например, добавив строку с нужными типами в декоратор. Проиллюстрирую типизацию на примере функции сложения с декоратором @vectorize:
import numpy as np
from numba import vectorize, int64, int32, float32, float64
@vectorize([float64(float64, float64)])
def sum_numbers(x, y):
return x + y
Передавая несколько типов, следует помнить, что порядок передачи последовательности типов должен следовать от наиболее конкретных к наименее (т. е. тип с плавающей запятой одинарной точности должен описываться раньше типа с плавающей запятой двойной точности), иначе диспетчеризация на основе типов не будет работать должным образом.
@vectorize([int32(int32, int32),
int64(int64, int64),
float32(float32, float32),
float64(float64, float64)])
def sum_numbers_multitype(x, y):
return x + y
Функция будет работать для указанных типов, однако с другими типами выдаст ошибку:

Numba создан специально с учетом Numpy и очень удобен для массивов Numpy. Как известно, Pandas основан на Numpy: поддерживает конвертацию структур данных Numpy в свои собственные структуры и наоборот. Данная особенность позволяет использовать Numba не только в паре с Numpy, но и с Pandas. Это приводит к сумасшедшей оптимизации при использовании пользовательских функций или даже при выполнении различных операций в любимой многими структуре данных pandas.DataFrame.
Рассмотрю ещё два примера:
import numpy as np
import pandas as pd
n = 1_000_000
df = pd.DataFrame({
'x': np.random.random(n),
'y': 100 * np.random.random(n)
})
Воспользуюсь декоратором @vectorize, он позволяет использовать функции Python, принимающие скалярные входные аргументы, в качестве ufuncs.
Вычислю квадрат Х в наборе данных:
from numba import vectorize
def squared_without_numba(x):
return x ** 2
@vectorize
def squared_with_numba(x):
return x ** 2
Сравню результаты:

Также посмотрю на применение Numba с методом @njit(parallel=True), который позволяет автоматически распараллелить выполнение кода в функции на разных ядрах CPU, но там, где это возможно.
from numba import njit
@njit(parallel=True)
def test_with_numba(x, y):
n = len(x)
result = np.empty(n, dtype="float64")
for i, (x, y) in enumerate(zip(x, y)):
result[i] = x**2 + y ** 2
return result
Сравню результаты:
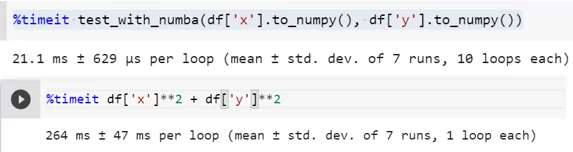
Приведенные примеры показали, что Numba позволяет сократить время выполнения кода и является простым способом сделать ваш код намного быстрее без особых усилий.
Попробуйте и убедитесь в этом лично!