/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
На помощь пришла такая технология как NLP (анализ естественного языка), которая имеет возможность разобрать и упорядочить хаос слов и эмоций человека.
Данные хранятся в некоторой сервисной системе, поэтому сначала я создал скрипт выгрузки данных. После того, как данные были выгружены из системы, я их предварительно обработал инструментами NLTK (токенизация, лемматизация, удаление стоп-слов, фильтрация по ключевым словам).
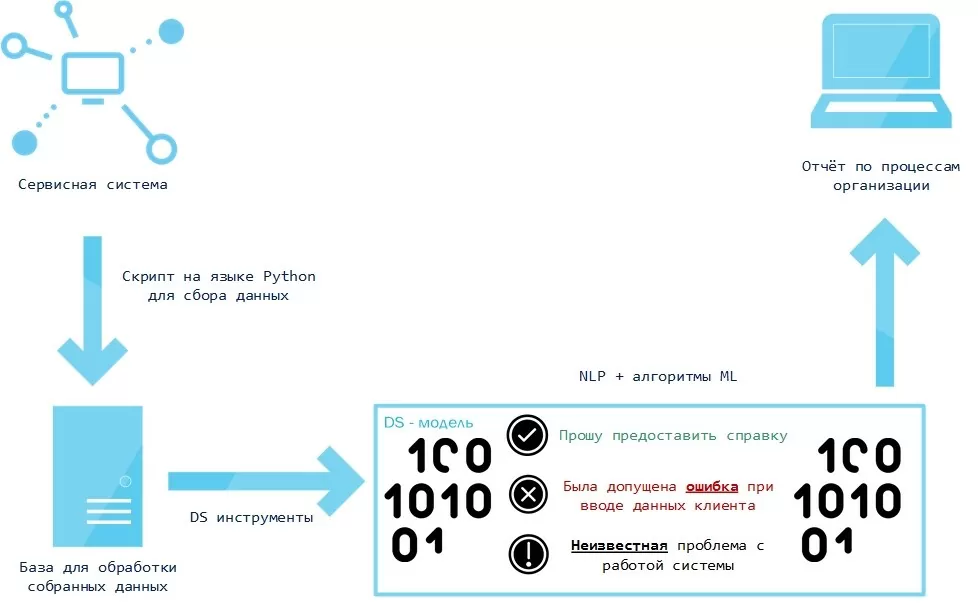
При этом, я заранее обучил алгоритм логистической регрессии на выборке, размеченной вручную (задача классификации стандартного и нестандартного). После предварительной обработки на обученную модель подаётся TfidfVectorizer (матрица частот слов) исходного набора данных. Модель показывает записи, которые по её мнению, являются необычными.
После этого найденные необычные записи подаются на вход алгоритму машинного обучения LocalOutlierFactor, как показано ниже.
In [ ]: from sklearn.feature extraction.text import TfidfTransformer, TfidfVectorizer
from sklearn.neighbors import LocaloutlierFactor
tfidf_vectorizer = Tfidfvectorizer(stop words=nltk. corpus. stopwords .words(‘ russian’),
‘tokenizer = token_and stem, use idf = True, ngram range=(2,4))
tfidf_matrix = tfidf_vectorizer. fit_transform(msg)
estimator = LocaloutlierFactor(n_neighbors=7000)
est = estimator. fit_predict(tfidf matrix)
LocalOutlierFactor (Локальный уровень выброса) является алгоритмом выявления аномальных точек данных путём измерения локального отклонения данной точки с учётом её соседних точек. Алгоритм выводит найденные отклонения бизнес-процессов.
После обучения я внедрю эту модель в работу с новыми данными, и она снова определяет, что хорошо, а что плохо и выдает отчет, с которым работает человек, но этот отчет четко структурирован и легко читается, а обработка его человеком занимает считанные минуты.
Теперь давайте представим, что данные не хранятся в удобной базе и совсем не похожи на привычные таблицы, я говорю о первоисточниках, а именно о бумажных документах. Хорошо, когда этих документов пару папок и их можно прочитать довольно быстро и выяснить для себя все что нужно. А если их тысячи? Подумайте сколько времени у вас это займет, а кроме того ведь нужно сделать какие-то выводы по ним.
В этот раз нам поможет такая технология как Computer Vision. Моей задачей было выгрузить документы, которые хранятся в файловом хранилище и к ним нельзя через скрипты обраться напрямую. В дальнейшем распознать текст со сканов документов, вычленить оттуда необходимую для анализа информацию и использовать её для некоторой аудиторской проверки.
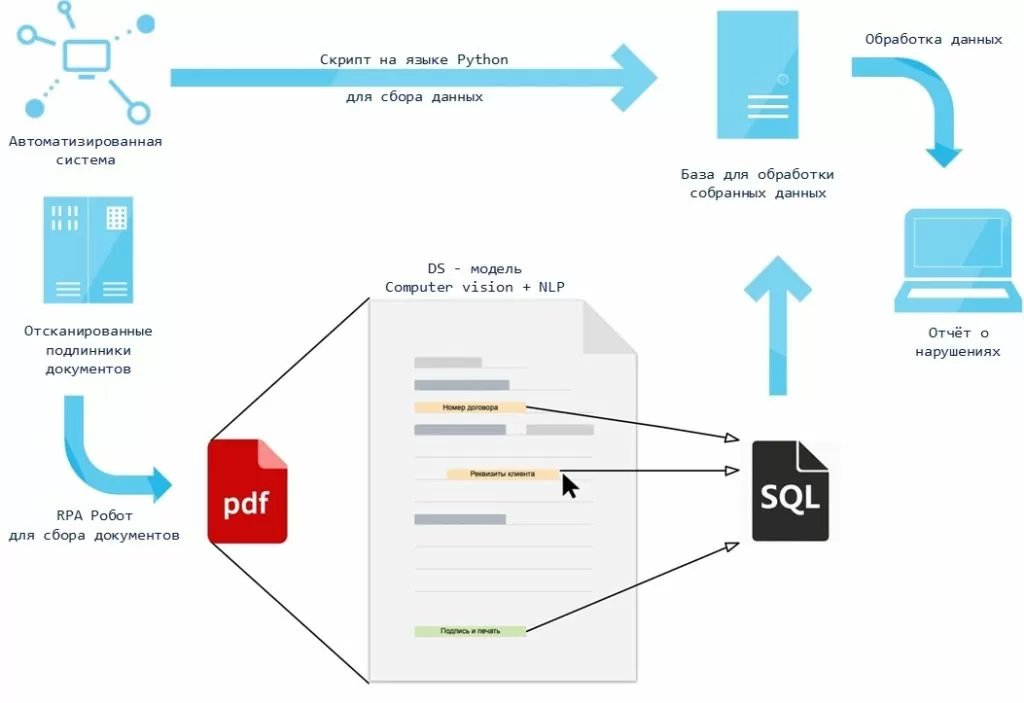
На рисунке выше представлена схема работы использованных алгоритмов и решений.
Смоделируем простой пример. Представим, что у нас есть сканы трудовых договор в pdf (например, как на рисунке ниже) и нам необходимо извлечь номер договора.

Чтобы конвертировать pdf в изображение используется библиотека pdf2img языка Python. Затем для распознавания текста с изображения используется библиотека pytesseract (оптическое распознавание символов), которая работает на основе рекуррентных нейронных сетей. Достаточно просто указать путь к изображению и вызвать метод image_to_string, указав при этом параметр языка, который будет распознаваться.
Из структуры договора видим, что после номера договора идёт перенос на новую строку. Будем это использовать для того, чтобы извлечь номер.
Пример применения описанного алгоритма к изображению, представлен ниже.
In [39]: def tesOCR(imgPath) :
img = Image. open(imgPath)
document text = image to string(img, lang="rus')
return document_text
In [40]:line = tesOCR('out.jpg')
line
Out [40]:'Трудовой договор № 11111\n\nг, Москва «01 » января 2011 г,\n\n, именуемое в дальнейшем\n«Работодатель», в лице + \nдействующего на основании с одной стороны и\n\nиванов Иван Иванович\n\nименуемый в дальнейшем «Работник», с друг ой стороны, заключили трудовой договор о нижеследующем: \n\n \n\n \n\n1. Предмет трудового договора\n1.1.По настояему трудовому договору Работник обязуется выполнять обязанности по профессии, специальности\n (должности) \n\n \n\nполное наименование профессии, специальности (должности) \n\n \n\nразряд, класс (категория квалификации) \nместо работы\nс подчинением внутреннему трудовому распорядку Работодателя, а Работодатель обязуется обеспечивать Работнику\nнеобходимые условия работы, своевременную и в полном объеме выплату заработной платы, необходимые бытовые условия в\nсоответствии с действующим законодательством, локальными нормативными актами, коллективным договором и настоящим\nтрудовым договором.
In [41]:line[line.find(‘договор №'):line.find('\n')]
Out [41]:'договор № 11111'Из рисунка видно, что библиотека pytesseract отлично справилась с распознавание текста, и наш алгоритм правильно определил номер договора. Подобным образом можно решать целое множество различных задач, которые встречаются в работе аудитора.