/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)
Время прочтения: 6 мин.
Одними из главных критериев качества кода являются читаемость кода и производительность. Но как добиться большей производительности и читаемости? В этом нам помогут функции map, filter и reduce.
Преимуществом использования данных функций взамен циклов for является краткость кода, а также скорость выполнения. Внутренние оптимизации позволяют им показывать лучшие результаты в скорости выполнения.
Lambda-выражения
Перед тем, как перейти непосредственно к функциям map(), filter(), reduce(), рассмотрим такую вспомогательную конструкцию, как лямбда-выражения. Лямбда-выражения являются анонимными функциями, которые выполняют только одно логическое выражение. Ниже приведен синтаксис:
lambda [arg1, arg2, ...]: [expression]В качестве примера рассмотрим сортировку списка, который содержит кортежи с именем человека и его ростом. Отсортируем список по росту людей:
# Функция принимает на вход кортеж с именем и ростом, возвращает только рост
def get_height(human_tuple):
height = human_tuple[1]
return height
people = [('John', 155), ('Pete', 160), ('Clara', 188), ('Alex', 180)]
print(sorted(people, key=get_height))
Результат работы: [(‘John’, 155), (‘Pete’, 160), (‘Alex’, 180), (‘Clara’, 188)]
Теперь выполним ту же сортировку, но с пользованием лямбда-выражений.
people = [('John', 155), ('Pete', 160), ('Clara', 188), ('Alex', 180)]
print(sorted(people, key=lambda x: x[1]))
Результат работы: [(‘John’, 155), (‘Pete’, 160), (‘Alex’, 180), (‘Clara’, 188)]
Использование лямбда-выражений может быть полезным в нескольких случаях:
- когда есть только одно выражение для выполнения в функции;
- когда выполнить код нужно только один раз.
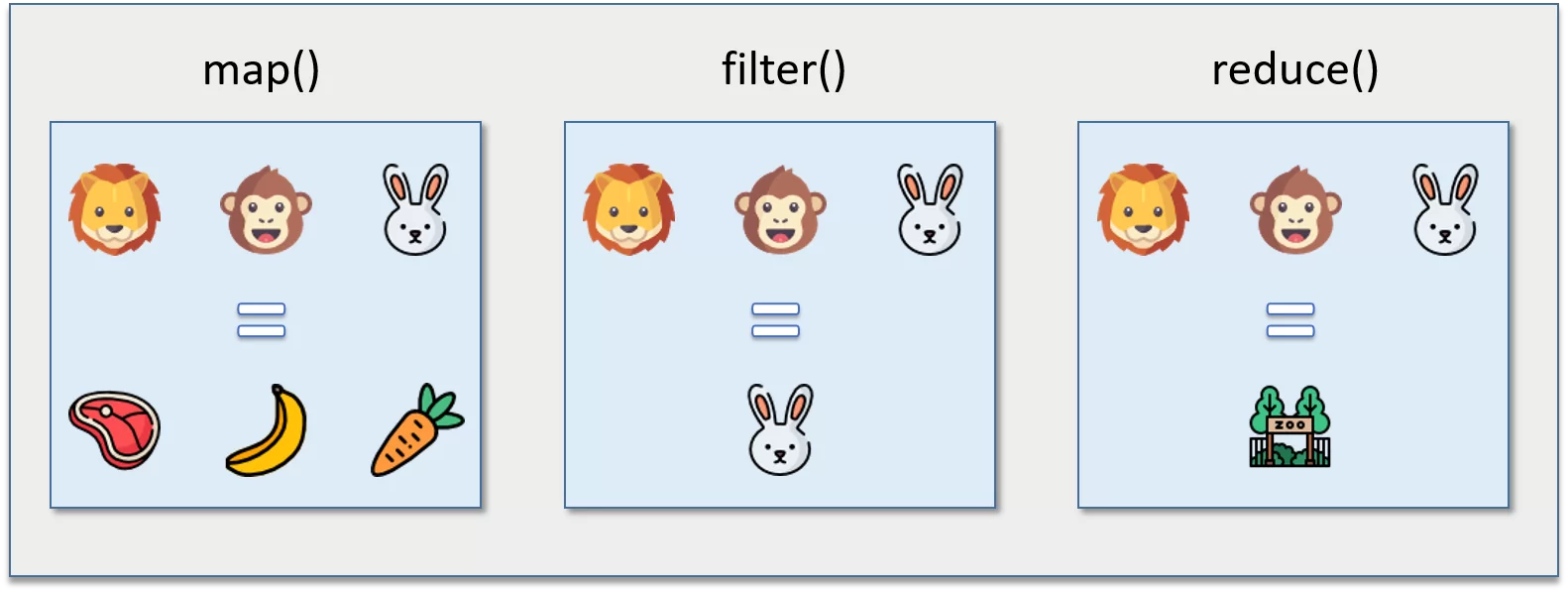
Что такое функции map(), filter() и reduce()
Функция map() принимает в качестве аргументов функцию и итерируемую последовательность. Позволяет применить переданную функцию к каждому элементу переданной итерируемой последовательности. Ниже приведен синтаксис:
map(function, iterable)Функция filter() принимает в качестве аргументов функцию и итерируемую последовательность. Позволяет создать список из элементов переданной итерируемой последовательности, для которых переданная функция вернет True. Ниже приведен синтаксис:
filter(function, iterable)Функция reduce() принимает в качестве аргументов функцию и итерируемую последовательность. Кумулятивно применяет переданную функцию к элементам итерируемой последовательности, сводя ее к единственному значению. Ниже приведен синтаксис:
reduce(function, iterable)Начиная с Python версии 3.0 данная функция была перенесена в стандартный модуль functools.
Для каждой из перечисленных функций в качестве function можно использовать лямбда-выражения. Например:
# Получение квадратов чисел из списка [1, 2, 3, 4, 5]
map(lambda x: x**2, [1, 2, 3, 4, 5])
Списковые включения и генераторы списков
Списковые включения (List comprehensions) – встроенный в Python механизм генерации списков. Списковые включения позволяют строить списки из любых итерируемых объектов. Ниже приведен синтаксис:
# Без условий
[smt for smt in iterable]
# При наличии if
[smt for smt in iterable if condition]
# При наличии if/else
[smt if condition else other for smt in iterable]
Также существую словарные включения (Dictionary comprehensions) и включения множеств (Set comrehensions), которые работают полностью аналогично.
Генераторы списков (List generators) – также, как и списковые включения, является встроенным в Python механизмом генерации списков. Главным отличием от списковых включений является то, что в результате работы генератора списков возвращается объект типа generator. Ниже приведен синтаксис:
# Без условий
(smt for smt in iterable)
# При наличии if
(smt for smt in iterable if condition)
# При наличии if/else
(smt if condition else other for smt in iterable)
Альтернатива циклов for
Рассмотрим, как можно заменить циклы for с помощью функций map(), filter() и reduce().
Возьмем матрицу, представленную в виде списков:
matrix = [[1, 2, 3],
[4, 5, 6],
[7, 8, 9]]
Для демонстрации функции map() уменьшим каждый элемент матрицы на 30%:
# С использованием цикла for
result = []
for row in matrix:
for item in row:
item *= 0.3
# С использованием map
result = map(lambda x: x * 0.3, matrix)
# С использованием спискового включения
result = [item * 0.3 for row in matrix for item in row]
Для демонстрации функции filter() получим из матрицы все строки, сумма элементов которых меньше 10:
# С использованием цикла for
result = []
summ = 0
for row in matrix:
summ = sum(row)
if summ < 10:
result.append(row)
# С использованием filter
result = filter(lambda x: sum(x) < 10, matrix)
# С использованием спискового включения
result = [row for row in matrix if sum(row) < 10]
Рассмотрим использование функции reduce() на примере приведение двумерной матрицы к одномерному виду:
# С использованием цикла for
result = []
for row in matrix:
for item in row:
result.append(item)
# С использованием reduce
result = reduce(lambda x, y: x + y, matrix)
# С использованием спискового включения
result = [item for row in matrix for item in row]
В данном примере списковое включение работает на порядок быстрее функции reduce(), однако также является и гораздо более сложным для понимания.
Использование генераторов для больших наборов данных
Списковые включения и циклы for загружают все входные данные в память. Для списков небольшого или среднего размера это нормально. Однако, если размер входных данных слишком велик, компьютеру может не хватить ресурсов, для создания такого большого списка и хранения его в памяти. В таком случае следует использовать генераторы.
Генераторы не хранят в памяти сразу все значения, вместо этого они хранят в памяти способ, по которому может быть получен следующий элемент последовательности, а также текущее состояние переменных генератора.
Рассмотренные в данной статье map(), filter() и генераторы списков в результате работы возвращают объект типа generator.
Сравнение производительности
Замерять время выполнения будем с использованием стандартной библиотеки timeit.
Пусть у нас есть список, который содержит миллион транзакций, произведенных в кафе за год. Посчитаем прибыль кафе, если с каждой транзакции берется налог в 30%.
TAX = .3
transactions = [random.randrange(10000) for _ in range(1000000)]
# map с выносной функцией
np.mean(timeit.repeat(map_func, repeat=1000, number=1))
# map с лямбда-выражением
np.mean(timeit.repeat(map_lambda, repeat=1000, number=1))
# генератор списков
np.mean(timeit.repeat(list_gen, repeat=1000, number=1))
# списковое включение
np.mean(timeit.repeat(list_comp, repeat=1000, number=1))
# генератор списков, приведенный к списку
np.mean(timeit.repeat(list_gen_to_list, repeat=1000, number=1))
# map с выносной функцией, пиведенный к списку
np.mean(timeit.repeat(map_func_to_list, repeat=1000, number=1))
# map с лямбда-выражением, приведенный к списку
np.mean(timeit.repeat(map_lambda_to_list, repeat=1000, number=1))
# цикл for
np.mean(timeit.repeat(for_loop, repeat=1000, number=1))
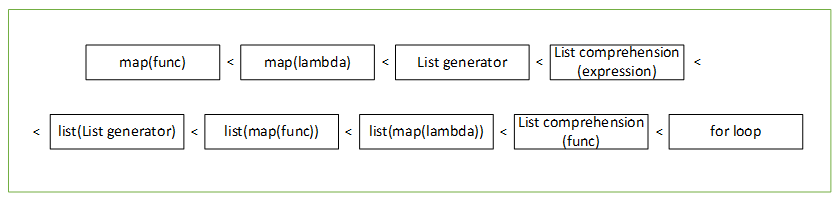
Результаты времени работы представлены в таблице:
| Подход | Время выполнения, мс |
| map/filter(func) | 2.25e-05 |
| map/filter(lambda) | 2.40e-05 |
| List generator | 3.25e-05 |
| List comprehension(выражение) | 1.0795371 |
| list(List generator) | 1.3387516 |
| list(map/filter(func)) | 1.5762654 |
| list(map/filter(lambda)) | 1.6126549 |
| List comprehension(func) | 1.7002037 |
| Цикл for | 2.172257 |
Как видно из таблицы, использование функций map(), filter() и reduce() значительно ускоряет выполнение кода по сравнению с использованием обычных циклов for, однако, если все действия над последовательностью можно выполнить в виде одного логического выражения, быстрее и лаконичнее будет использовать списковые включения.
Если же размер входных данных очень велик, рекомендуется использовать функции map() и filter(), так как они не хранят все значения в памяти и работают быстрее, чем генераторы списков.
Ниже приведено изображение, результирующее сравнение производительности рассмотренных подходов: