/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
Для выявления ключевых слов, для начала будет решена задача кластеризации на тематики текстов с помощью метода LDA (Latent Dirichlet Allocation). После этого будет решаться задача, непосредственно, выявления ключевых словосочетаний с помощью предобученной модели Bert. И завершающим будет метод WordToVec, служащий для решения задачи поиска наиболее семантически похожих слов в тексте.
Обучающих набор данных состоит из 110 текстов на общую тему аудит. Посмотрим, можно ли эти тексты разбить на более подробные тематики. Метод LDA предназначен для тематического моделирования, чтобы выявить абстрактные темы, на которые написан пул текстов.
Предобработка текста
Однако, сначала наши данные нужно предобработать. Итак, наш корпус – это список из списков python, где каждая отдельная статья заключена в свой список. Это необходимо, так как для реализации данной модели нужно знать количество документов. Переведем весь текст в нижний регистр
#переведем все в нижний регистр
for i in range(len(corpus)):
for j in range(len(corpus[i])):
corpus[i][j] = corpus[i][j].lower()
Далее удаляем числа.
#удалим числа
import string
def remove_chars_from_text(text, chars):
return ''.join([i for i in text if i not in chars])
for i in range(len(corpus)):
for j in range(len(corpus[i])):
corpus[i][j] = remove_chars_from_text(corpus[i][j], string.digits)
На третьем шаге удаляем пунктуацию и все символы. Для реализации данного шага можно было бы воспользоваться стандартным перечнем пунктуации, однако для более качественного результата символы лучше просмотреть самостоятельно.
replace('~', '').replace('?', '').replace("''", '').replace("'", '').replace("=", '').replace('→', '')LDA
Теперь, когда текст готов к построению модели, импортируем необходимые библиотеки:
import nltk
from sklearn import feature_extraction
import mpld3
from nltk.tokenize import word_tokenize
from nltk.tokenize import sent_tokenize
from collections import Counter
from gensim.corpora.dictionary import Dictionary
import pymorphy2
Токенизируем текст –разделяем слова между собой.
#токенизируем текст
def tokenize(texts):
tokens = [w for w in word_tokenize(texts)]
return tokens
Удаляем стоп-слова, которые также лучше самостоятельно просмотреть среди текстов, а не просто удалять стандартные. Проводим лемматизацию, то есть приведение каждого токена в начальную форму.
morph = pymorphy2.MorphAnalyzer()
for i in range(len(totalvocab_tokenized)):
k = [morph.parse(word)[0].normal_form for word in totalvocab_tokenized[i]]
Далее формируем словарь, содержащий количество раз, когда слово появляется в обучающем наборе. При этом словарь фильтруем, и выбираем токены, которые появляются не менее, чем в 1 документе, а также, которые появляются более, чем в 0,8 документах от общего объема корпуса.
from gensim import corpora
dictionary = corpora.Dictionary(l)
dictionary.filter_extremes(no_below=1, no_above=0.8)
Для каждого документа мы создаем словарь, в котором хранится информация, какое слово сколько раз встречается.
corpus_2 = [dictionary.doc2bow(text) for text in l]Строим модель LDA, и передаем в качестве аргумента словарь, который сделали на предыдущем шаге.
from gensim import corpora, models, similarities
%time lda = models.LdaModel(corpus_2, num_topics=40, id2word=dictionary)
lda.show_topics(10)
С помощью следующих команд можно вывести красивую визуализацию метода с ключевыми словами для каждой выделенной темы
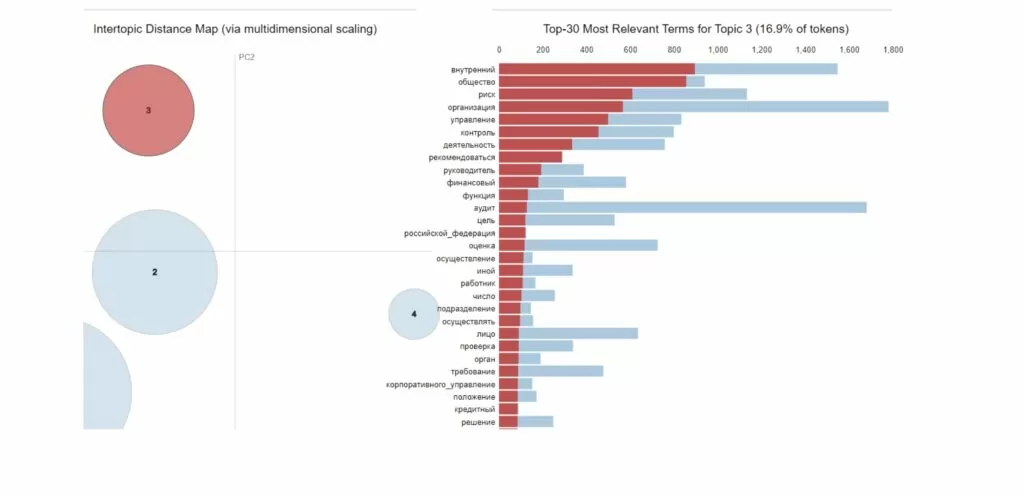
import pyLDAvis
import pyLDAvis.gensim_models as gensimvis
pyLDAvis.enable_notebook()
vis = pyLDAvis.gensim_models.prepare(lda_model, corpus, dictionary=lda_model.id2word)
vis
Bert
Bert – это модель, с помощью которой становится возможно преобразовать фразы в векторы, при этом не теряя их значения. Здесь не будет описана технология работы модели Bert, а будет просто приведен пример решения задачи выделения ключевых слов с помощью предобученной модели.
Для реализации данного метода проводится предобработка, описанная выше. Далее все тексты склеиваются в один, так как этот метод решает задачу выделения ключевых слов.
Для преобразования слов в векторную форму будем использовать CountVectorizer. Также мы установили гиперпараметр n_gram_range(2, 2,), что обозначает, что мы будем выделять словосочетания, состоящие из двух слов.
from sklearn.feature_extraction.text import CountVectorizer
c = CountVectorizer(ngram_range=(2, 2)).fit([full_list])
candidates = c.get_feature_names()
Далее используем Bert для представления ключевых слов-фраз в числовые данные.
from sentence_transformers import SentenceTransformer
bert = SentenceTransformer('distilbert-base-nli-mean-tokens')
embedding = bert.encode([full_list])
candidate = bert.encode(candidates)
Используем косинусное расстояние между векторами, с помощью которого будут искаться наиболее похожие друг на друга слова. И для вывода итогового результата можно использовать приведенный код.
from sklearn.metrics.pairwise import cosine_similarity
top_n = 10
distances = cosine_similarity(doc_embedding, candidate_embeddings)
keywords = [candidates[index] for index in distances.argsort()[0][-top_n:]]
['профессиональными бухгалтерскими',
'публично правовые компании',
'подразделений специализирующихся',
'комплаенс-рисков бизнес процессов',
'соответствующий квалификационный']
WordToVec
После 2х методов выше, можно применить модель WordToVec, которая сохраняет семантическое значение различных слов в документе.
Сначала проводится предобработка текстов. Далее с помощью библиотеки python-nltk токенизруем текст на предложения, а далее на слова.
words = [nltk.word_tokenize(sentence) for sent in all_sentences]
words = [nltk.word_tokenize(sentence) for sent in all_sentences]
Применяем модель WordToVec, и ставим гиперпараметр, отвечающий за то, чтобы в корпус слов попали только те, что попадаются 2 и более раз и формируем словарь из слов:
from gensim.models import Word2Vec
word2vec = Word2Vec(all_words, min_count=2)
vocabulary = word2vec.wv.vocab
В команду ниже можно вставлять слова, например, полученные с помощью модели LDA, и смотреть, какие слова наиболее часто употребляются вместе с этим словом.
sim_words = word2vec.wv.most_similar('отчетности')
sim_words
[('финансовой', 0.9878754615783691),
('образования', 0.9878393411636353),
('подготовки', 0.9859713315963745),
('составление', 0.9857062101364136),
('достоверности', 0.985139787197113),
('другой', 0.985068678855896),
('обзорной', 0.9845501184463501),
('применимой', 0.9845477342605591),
('проаудированной', 0.9842839241027832),
('наблюдательного', 0.9833971261978149)]
Таким образом, все методы можно использовать для выделения ключевых слов и словосочетаний, с помощью которых можно первоначально оценить тематику текстов. Метод LDA, хоть и служит для решения задачи кластеризации на тематики, но, тем не менее, является самым подробным, так как выводит ключевые слова для каждой темы. Word-to-vec служит для других целей, но также является эффективным методом решения. Bert показывает качество при работе со словосочетаниями.