/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
Выбор источника и инструментов реализации
В качестве источника информации я решил использовать habr.com – коллективный блог с элементами новостного сайта (публикуются новости, аналитические статьи, статьи по информационным технологиям, бизнесу, интернету и др.). На этом ресурсе все материалы делятся на категории (хабы), из которых только основных – 416 штук. Каждый материал может принадлежать к одной или нескольким категориям.
Код для сбора информации (парсинга) написан на языке python. Среда разработки – Jupyter notebook на платформе Google Colab. Основные библиотеки:
- BeautifulSoup – парсер для синтаксического разбора файлов html / xml;
- Requests – инструмент для составления и обработки http запросов;
- Re – модуль для работы с регулярными выражениями;
- Pandas – высокоуровневый инструмент для управления данными.
Также использовал модуль tqdm для визуализации прогресса обработки и модуль ratelim для ограничения количества запросов к данным (чтобы не превысить лимит и не создавать излишнюю нагрузку на сервер).
Подробности реализации
Каждая публикация на Хабре имеет свой номер, который отражается в адресной строке. Это позволит осуществить перебор всех материалов в цикле:
mainUrl = 'https://habr.com/ru/post/'
postCount = 10000Однако следует иметь ввиду, что некоторые публикации могут быть удалены авторами, либо перенесены в черновики, поэтому доступа к ним не будет. Для обработки таких случаев удобно использовать блок try… except в связке с библиотекой requests. В общем виде процедура получения текста статьи может выглядеть так:
@ratelim.patient(1, 1)
def get_post(postNum):
currPostUrl = mainUrl + str(postNum)
try:
response = requests.get(currPostUrl)
response.raise_for_status()
response_title, response_post, response_numComment, response_rating, response_ratingUp, response_ratingDown, response_bookMark, response_views = executePost(response)
dataList = [postNum, currPostUrl, response_title, response_post, response_numComment, response_rating, response_ratingUp, response_ratingDown, response_bookMark, response_views]
habrParse_df.loc[len(habrParse_df)] = dataList
except requests.exceptions.HTTPError as err:
passПервой строкой задается лимит на максимальное количество вызовов процедуры за промежуток времени – не более одного раза в секунду. В блоке try получаю результат запроса к странице – при положительном ответе переход к разбору страницы, в случае возникновения исключений пропуск адреса и переход к следующему.
В процедуре executePost описана обработка кода интернет-страницы для получения текста статьи и других необходимых параметров.
def executePost(page):
soup = bs(page.text, 'html.parser')
# Получаем заголовок статьи
title = soup.find('meta', property='og:title')
title = str(title).split('="')[1].split('" ')[0]
# Получаем текст статьи
post = str(soup.find('div', id="post-content-body"))
post = re.sub('\n', ' ', post)
# Получаем количество комментариев
num_comment = soup.find('span', id='comments_count').text
num_comment = int(re.sub('\n', '', num_comment).strip())
# Ищем инфо-панель и передаем ее в переменную
info_panel = soup.find('ul', attrs={'class' : 'post-stats post-stats_post js-user_'})
# Получаем рейтинг поста
try:
rating = int(info_panel.find('span', attrs={'class' : 'voting-wjt__counter js-score'}).text)
except:
rating = info_panel.find('span', attrs={'class' : 'voting-wjt__counter voting-wjt__counter_positive js-score'})
if rating:
rating = int(re.sub('/+', '', rating.text))
else:
rating = info_panel.find('span', attrs={'class' : 'voting-wjt__counter voting-wjt__counter_negative js-score'}).text
rating = - int(re.sub('–', '', rating))
# Получаем количество положительных и отрицательных голосов за рейтинг статьи
vote = info_panel.find_all('span')[0].attrs['title']
rating_upVote = int(vote.split(':')[1].split('и')[0].strip().split('↑')[1])
rating_downVote = int(vote.split(':')[1].split('и')[1].strip().split('↓')[1])
# Получаем количество добавлений в закладки
bookmk = int(info_panel.find_all('span')[1].text)
# Получаем количество просмотров поста
views = info_panel.find_all('span')[3].text
return title, post, num_comment, rating, rating_upVote, rating_downVote, bookmk, viewsВ ходе обработки использовалась библиотека BeautifulSoup для получения кода страницы в текстовом виде: soup = bs(page.text, ‘html.parser’). Затем использовал функции этой библиотеки find / findall и другие для поиска определенных участков в коде (например, по имени класса или по html-тегам). Получив текст статьи обработал его регулярными выражениями для того, чтобы очистить от html-тегов, гиперссылок, лишних знаков и др.
Оформив обработку отдельной страницы можно запустить ее в цикле по всем статьям (или по необходимой выборке), размещенным на ресурсе. Например, можно взять первые 10 тысяч статей. Библиотека tqdm отобразит текущий прогресс выполнения.
for pc in tqdm(range(postCount)):
postNum = pc + 1
get_post(postNum)
Данные записывал в датафрейм pandas и сохранял в файл:
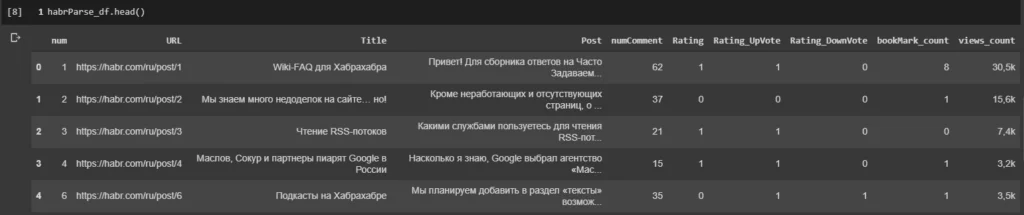
В результате получил датасет, содержащий тексты статей ресурса habr.com, а также дополнительную информацию – заголовок, ссылка на статью, количество комментариев, рейтинг, количество добавлений в закладки, количество просмотров.
В дальнейшем полученный датасет можно обогатить дополнительными данными и использовать для тренировки в построении различных языковых моделей, классификации текстов и др.