/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 3 мин.
Ранее я говорил о том, как скачивали файлы из базы и распознавать их, здесь я расскажу о том, как вытаскивать информацию (для анализа данных для спринта), по ключевым словам, или фразам из документов разных форматов (.rtf, .doc, .docx, .xls, .xlsx, .pdf). Вообще эту тему можно отнести к text mining, data mining. Text Mining — это если простыми словами, то добыча информации из текстов. Data Mining – это примерно то же самое что и TM только не в тексте, а большом наборе данных для последующего анализа.
В этой задаче столкнулся с такой проблемой как отсутствие нормальных библиотек для Python для парсинга информации с файлов!
Так как файлы были разных форматов (.rtf, .doc, .docx, .xls, .xlsx, .pdf) и что бы открыть и прочитать информацию из них помощью Python нужно было найти подходящие библиотеки. В .pdf были сканы, и мы вопрос с ними уже решили (об этом я рассказывал в предыдущей статье). Для работы с форматами .xls, .xlsx есть отличная библиотека pandas, которая на ура справляется с поставленной целью и не только. Pandas это высокоуровневая Python библиотека для анализа данных. В экосистеме Python, pandas является лучшей и быстроразвивающейся библиотекой для обработки и анализа данных. Мне приходится пользоваться ею практически каждый день!
Осталось решить вопрос с .rtf, .doc, .docx.
Rich Text Format, RTF — это формат текста придуманный группой программистов из Microsoft и Adobe в 82 году.
Для работы с этим форматом использовал разные библиотеки в том числе pyth.
#RTF
import pandas as pd
from pyth.plugins.rtf15.reader import Rtf15Reader
from pyth.plugins.plaintext.writer import PlaintextWriter
import re
import glob
#from pyth.plugins.xhtml.writer import XHTMLWriter
.doc — то же является текстовым форматом, но более лучшим чем предыдущий.
Для работы с ним использовал разные библиотеки, но также, как и с форматом .rtf проблема заключалась в том, что в документах были таблицы и нормально прочитать их не получалось никакой библиотекой (ни .rtf, ни .doc), просто текст читает без проблем если там нет таблиц (.rtf и .doc)!
В связи с этим .rtf и .doc просто приходилось конвертировать в формат .docx (про него ниже) и также сделал просто .exe-шник с помощью Python который конвертирует эти форматы в .docx.
import os
import win32com.client
for all_doc in files_doc:
print(dir_name + '/' + all_doc + 'x')
word = win32com.client.Dispatch('Word.Application')
wb = word.Documents.Open(dir_name + '/' + all_doc)
wb.SaveAs2(dir_name + '/' + all_doc + 'x', FileFormat=16)
wb.Close()
Начиная с 2007 появился новый формат на основе XML — docx.
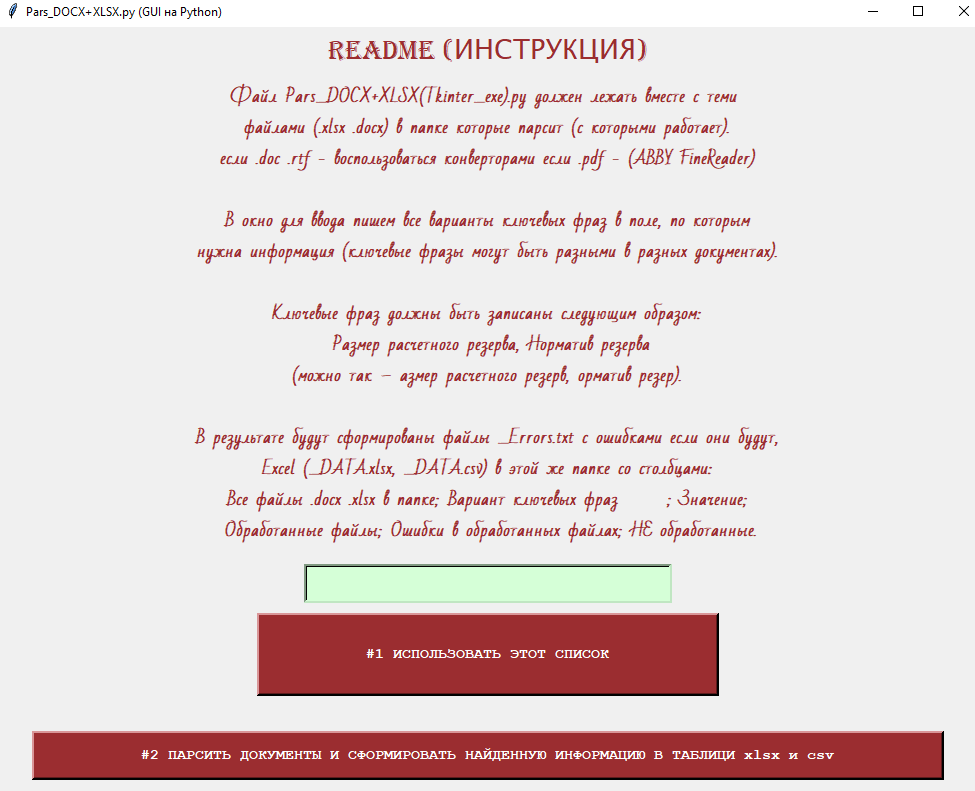
И так, с форматами .xls, .docx, проблем никаких не возникло. С помощью необходимых библиотек (docx, pandas, tkinter) работа с файлами, вытаскивание информации, по ключевым словам, или фразам была реализована! Сделан графический интерфейс (графический пользовательский интерфейс (ГПИ) (англ. graphical user interface, GUI)) также скомпилирована в .exe и добавлена инструкция.
import tkinter as tk
from docx import Document
from os import listdir
from pandas import ExcelFile
from pandas import DataFrame
my_columns = df1.columns
for col in my_columns:
my_val_ind = df1[df1[col].astype(str).apply(lambda x: any(s in x for s in spis_to_find))].index
# ищем вхождение ключевой фразы из списка spis_to_find (либо функц any) и берем индекс
# print(my_val_ind)
if len(my_val_ind ) > 0: # если индекс какой то был найден то тянем значения
for ival in df1[df1.index == my_val_ind[0]].values:
Data_xlsx.append(xlsx_name)
key_conteins.append(ival)
Что получилось: