/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 7 мин.
Сегодня я рассмотрю процесс получения эмбеддингов текстов с помощью BERT для их дальнейшего тематического моделирования.
Обработка естественного языка одно из востребованных направлений машинного обучения, которое постоянно развивается. В 2018 году компания Google представила новую модель — BERT, сделавшую прорыв в области обработки естественного языка. Несмотря на то, что сейчас у BERT много конкурентов, включая модификации классической модели (RoBERTa, DistilBERT и др.) так и совершенно новые (например, XLNet), BERT всё ещё остается в топе nlp-моделей.
Данная модель применяется во многих задачах: классификация текстов, генерация текста, суммаризация текста и т.д. Но ее также можно использовать для получения векторных представлений текста — эмбеддингов. Они могут использоваться, например, для последующей кластеризации или в качестве исходных данных для других моделей.
Сейчас я попытаюсь выделить подтемы внутри большого набора статей про науку и технику в новостном сайте. В начале я получу эмбеддинги с помощью предобученной модели BERT. Для этого буду использовать python-библиотеки transformers и pytorch. Затем полученные эмбеддинги буду использовать в качестве признаков в кластеризации. После того как получу метку принадлежности к определенному кластеру, сожму эмбеддинги до двух признаков, чтобы визуализировать результат.
В качестве источника данных буду использовать архив с новостями Lenta.ru. Весь код будет выполняться в облачном сервисе Google Colaboratory.
Скачаем и распакуем архив с новостями и предобученную на русских текстах модель BERT с проекта deeppavlov. Весь код будет выполняться в облачном сервисе Google Colaboratory.
!gdown https://github.com/yutkin/Lenta.Ru-News-Dataset/releases/download/v1.1/lenta-ru-news.csv.bz2
!gdown http://files.deeppavlov.ai/deeppavlov_data/bert/rubert_cased_L-12_H-768_A-12_pt.tar.gz
!bzip2 -d lenta-ru-news.csv.bz2
!tar -xzf /content/rubert_cased_L-12_H-768_A-12_pt.tar.gz
Импортируем нужные библиотеки
!pip install transformers
!pip install pyyaml==5.4.1
import numpy as np
import pandas as pd
import torch
import os
import json
from tqdm import tqdm
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_auc_score
from sklearn.decomposition import PCA
from sklearn.cluster import AgglomerativeClustering
from torch.utils.data import Dataset, DataLoader
from transformers import BertModel, BertTokenizer
В распакованном архиве хранится csv-файл с информацией о статьях. Почти для каждой статьи указан заголовок, тематика, тег и дата публикации.
Посмотрим список тем:
df = pd.read_csv('/content/lenta-ru-news.csv', low_memory=False)
df['topic'].unique()
# 'Библиотека', 'Россия', 'Мир', 'Экономика', 'Интернет и СМИ',
# 'Спорт', 'Культура', 'Из жизни', 'Силовые структуры',
# 'Наука и техника', 'Бывший СССР', nan, 'Дом', 'Сочи', 'ЧМ-2014',
# 'Путешествия', 'Ценности', 'Легпром', 'Бизнес', 'МедНовости',
# 'Оружие', '69-я параллель', 'Культпросвет ', 'Крым'
Выберем десять тысяч статей из темы «Наука и техника».
corpus = df.loc[df['topic']=='Наука и техника', 'text'].to_numpy()
corpus = corpus[:10000]
Посмотрим пример текста:
corpus[0]
# Американские ученые в ближайшее время отправят на орбиту спутник,
# который проверит два фундаментальных предположения, выдвинутых Альбертом Эйнштейном...
В распакованной папке с моделью есть файл bert_config.json. Но метод from_pretrained ожидает наличие в папке файла config.json, а не bert_config.json, добавим недостающий файл. Если бы мы использовали обобщенные классы AutoModel и AutoTokenize, то пришлось бы в файл config.json добавлять строчку «model_type»: «bert», т.к изначально эти классы ничего не знают о типе используемой модели.
with open("/content/rubert_cased_L-12_H-768_A-12_pt/bert_config.json", "r") as read_file, open("/content/rubert_cased_L-12_H-768_A-12_pt/config.json", "w") as conf:
file = json.load(read_file)
conf.write(json.dumps(file))
!rm /content/rubert_cased_L-12_H-768_A-12_pt/bert_config.json
В BERT подается на вход не сам текст, а токены. Поэтому вместе со скачанной моделью в папке идет готовый токенизатор.
Подгрузим модель и токенизатор из распакованной папки с помощью метода from_pretrained. Для этого нужно просто указать путь к папке. При инициализации модели укажем, чтобы выводились промежуточные состояния.
На самом деле модель можно подгрузить с сайта Hugging Face, просто указав ее корректное название в методе from_pretrained. Но вариант с предварительным скачиванием пригодится, например, когда отсутствует доступ к интернету.
tokenizer = BertTokenizer.from_pretrained('rubert_cased_L-12_H-768_A-12_pt')
model = BertModel.from_pretrained('rubert_cased_L-12_H-768_A-12_pt', output_hidden_states = True)
Далее воспользуюсь вспомогательными классами Dataset и Dataloader из torch.utils. Создам класс CustomDataset на основе импортированного класса Dataset. Для корректной работы переопределю в нем методы __len__ и __getitem__.
Добавим метод tokenize, внутри которого к тексту будет применяться инициализированный ранее tokenizer. Формат выходных данных будет torch.tensor. Поставим максимальную длину токенизированного текста на 150 токенов.
class CustomDataset(Dataset):
def __init__(self, X):
self.text = X
def tokenize(self, text):
return tokenizer(text, return_tensors='pt', padding='max_length', truncation=True, max_length=150)
def __len__(self):
return self.text.shape[0]
def __getitem__(self, index):
output = self.text[index]
output = self.tokenize(output)
return {k: v.reshape(-1) for k, v in output.items()}
eval_ds = CustomDataset(corpus)
eval_dataloader = DataLoader(eval_ds, batch_size=10)
Для получения эмбеддингов, воспользуемся функцией из этой статьи. В ней берется выход из последнего слоя и усредняется по каждому значению. Про значения, получаемые на выходе из BERT, можно почитать здесь.
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output['last_hidden_state']
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
sum_embeddings = torch.sum(token_embeddings * input_mask_expanded, 1)
sum_mask = torch.clamp(input_mask_expanded.sum(1), min=1e-9)
return sum_embeddings / sum_mask
Переводим модель в состояние валидации и отключаем подсчет градиента, а также переносим на графический ускоритель, если он доступен:
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
model.to(device)
model.eval()
embeddings = torch.Tensor().to(device)
with torch.no_grad():
for n_batch, batch in enumerate(tqdm(eval_dataloader)):
batch = {k: v.to(device) for k, v in batch.items()}
outputs = model(**batch)
embeddings = torch.cat([embeddings, mean_pooling(outputs, batch['attention_mask'])])
embeddings = embeddings.cpu().numpy()
Алгоритмы кластеризации времязатратны, поэтому, чтобы сократить длительность расчетов, уменьшим размерность эмбеддингов с 768 до 15. Для этого применим классический метод уменьшения размерности — «Метод главных компонент», реализованный в sklearn.
pca = PCA(n_components=15, random_state=42)
emb_15d = pca.fit_transform(embeddings)
Далее запускаем алгоритм кластеризации. Данный алгоритм позволяет определить автоматически число кластеров. Для этого надо указать в параметрах n_clusters=None, но тогда нужно обязательно указать параметр distance_threshold. Он отвечает за пороговое расстояние. Если расстояние между наблюдением и кластером меньше порога, то это наблюдение причисляется к этому кластеру. Параметр linkage отвечает за то, как считается координата кластера. В моём случае координата считается, как среднее координат всех наблюдений, принадлежащих к этому кластеру. Параметр affinity отвечает за метрику, которая будет использоваться для вычисления расстояния между наблюдениями. Мы выберем косинусное расстояние.
clustering = AgglomerativeClustering(n_clusters=None, distance_threshold=0.6, affinity='cosine', linkage='average').fit(emb_15d)Чтобы визуализировать результат на графике, уменьшу размерность до двух.
pca = PCA(n_components=2, random_state=42)
emb_2d = pd.DataFrame(pca.fit_transform(embeddings), columns=['x1', 'x2'])
emb_2d['label'] = clustering.labels_
emb_2d['label'].nunique() # 40
У меня получилось 40 разных кластеров. Количество кластеров может быть другим. Всё зависит от выбранных гиперпараметров при кластеризации, о которых я говорил ранее.
Построю интерактивный график с помощью библиотеки plotly для быстрой навигации по получившимся кластерам.
import plotly.express as px
fig = px.scatter(emb_2d, x='x1', y='x2', color='label', width=800, height=600)
fig.show()
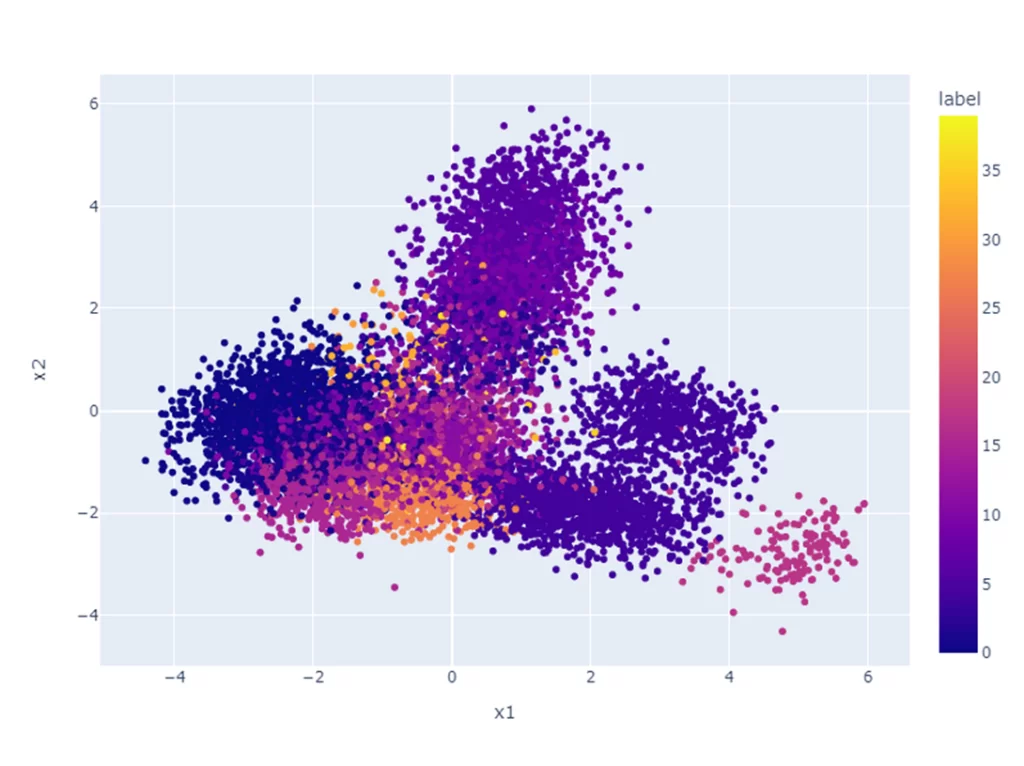
Данный график иллюстрирует распределение кластеров на двумерном пространстве. Для интерпретации получившихся результатов необходимо более детально рассмотреть каждый кластер. Это можно осуществить, рассчитав TF-IDF для каждого слова из текста. С помощью этого метода можно получить ключевые слова каждой темы. Важность слов в этом методе оценивается по частоте встречаемости их в конкретном тексте и редкости в других текстах. Более подробно о реализации этого можно почитать здесь.
Я лишь посмотрим несколько первых предложений внутри кластеров и оценим их схожесть. Рассмотрим кластер слева под номером 0:
def show_examples(cluster, n):
for i in range(n):
print(i, corpus[emb_2d['label'] == cluster][i].split('.')[0])
show_examples(cluster=0, n=3)
# 0 Доплеровский радар в армии США будет использоваться не только для составления метеорологических карт,
# но и для раннего предупреждения о биологической или химической атаке с воздуха
# 1 Военно-космические силы США приняли на вооружение новую систему,
# предназначенную для глушения космических спутников, сообщает агентство Reuters
# 2 На авиабазе ВВС США "Эдвардс" в Калифорнии проведены первые успешные испытания боевого лазера воздушного базирования
Вероятнее всего, в этом кластере говорится о военных достижениях США.
Для сравнения посмотрим кластер 6 сверху:
show_examples(cluster=6, n=3)
# 0 Используя преимущества технологии Blu-ray (синий лазер, в отличие от красного, применяемого в CD и DVD-приводах),
# позволяющей создавать сверхтонкие носители информации, корпорация Sony и компания Toppan Printing разработали "бумажный" диск,
# на который можно записать 25 гигабайт видео
# 1 Американская компания Microvision создала лазерную технологию,
# которая позволит человеку видеть дополнительное изображение - помимо той картинки, которую он получает при помощи обычного зрения
# 2 Автор операционной системы Linux Линус Торвальдс (Linus Torvalds) предлагает создать новую систему # регистрации изменений, вносимых в операционную системы, с целью предотвращения любых обвинений в нарушении авторских прав, сообщает Siliconvalley
В этом кластере, вероятнее всего, говорится о средствах передачи информации.
Таким образом, я рассмотрел все основные этапы тематического моделирования, кроме подробного анализа получившихся кластеров. Не исключено, что в наших кластерах найдутся темы, которые дублируют друг друга. Есть несколько способов это исправить. Первый – это поэкспериментировать с параметрами кластеризации или указать вручную число кластеров, а также можно вовсе использовать другой метод кластеризации. Второй – уменьшить количество тем с помощью поиска похожих кластеров и объединения их в один. Данный подход можно осуществить с помощью TF-IDF и подобных методов.