30.03.2021, Дарья Донская, г. Иркутск Что такое Spark и с чем его едят?
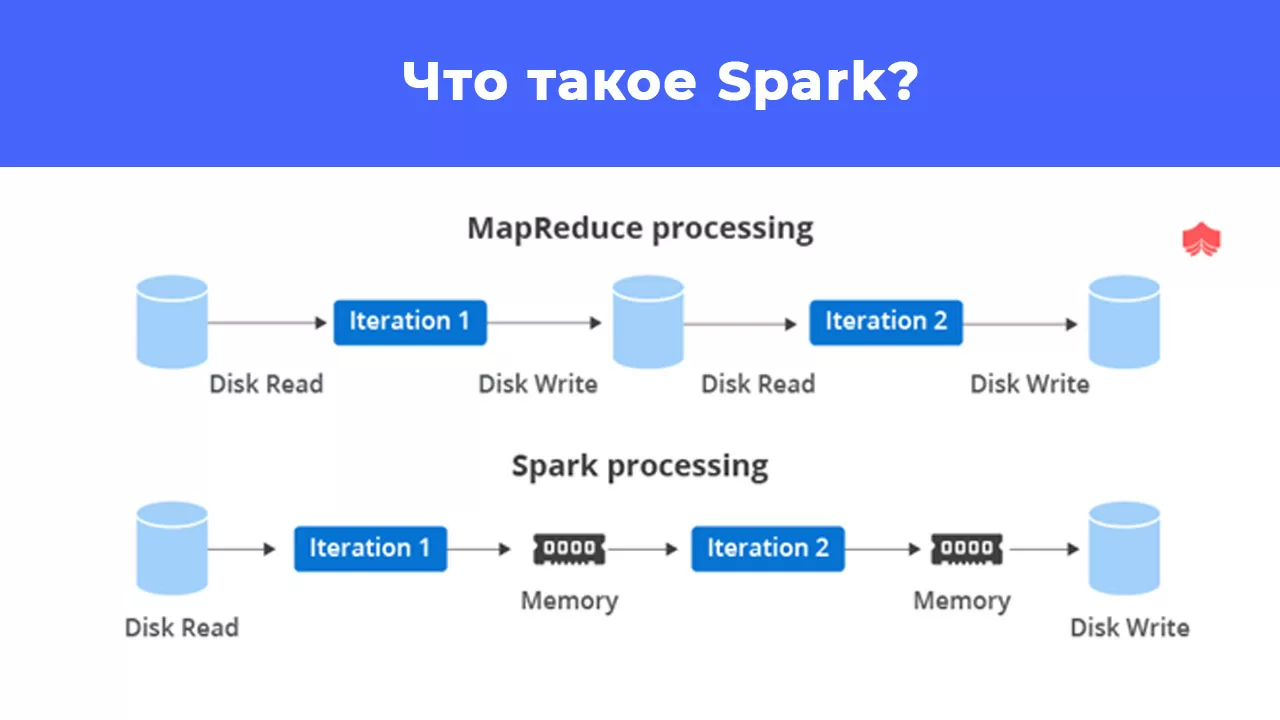
Статья больше рассчитана для новичков, кто впервые сталкивается со Spark. Сейчас кол-во информации растет, и требуются ресурсы и время для ее обработки. В связи с этим на свет появляться модель MapReduce, которая параллельно вычисляет операции на кластерах.
MapReduce отлично упрощает анализ big data на больших, но ненадежных кластерах. Стоит отметить, что с ростом популярности фреймворка пользователи хотят большего.
/img/star (2).png.webp)
/img/news (2).png.webp)












/img/event.png.webp)