/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)
Время прочтения: 5 мин.
Для визуализации данных в Python представлен ряд весьма популярных библиотек, о которых не раз упоминалось на сайте NewTechAudit – это seaborn, matplotlib, plotly. И есть еще одна библиотека, которая чаще всего используется для построения Treemap (древовидной карты) – библиотека squarify, о работе которой я расскажу в этом материале на примере небольших наборов данных.
Надо отметить, что первую Treemap, основанную на алгоритме «квадратизации», создал в 1999 году Мартин Ваттенберг (Martin M. Wattenberg, профессор Школы инженерии и прикладных наук Гарвардского университета) для визуализации данных о большом количестве компаний, присутствующих на фондовом рынке США.
Treemap отображает иерархические данные в виде набора вложенных визуализаций на основе прямоугольников. Этот способ визуализации приемлем, когда набор данных структурирован в иерархическом порядке с древовидной структурой: с корнями, ветвями и узлами, что позволяет эффективно отображать информацию о значимом объеме данных в ограниченном пространстве.
Библиотеку squarify рекомендовано использовать в следующих случаях:
- при работе со сложными иерархическими наборами данными, когда, например, гистограмма не представляет эффективную визуализацию;
- для визуализации пропорций между частями данных и целым, обозначив их метками;
- для отображения атрибутов с использованием размера и цветового кодирования;
- для визуализации шаблона распределения показателя по каждому уровню категорий в иерархии данных;
Начнем с установки библиотеки.
pip install squarifyTremmap-диаграмма со списком цветов
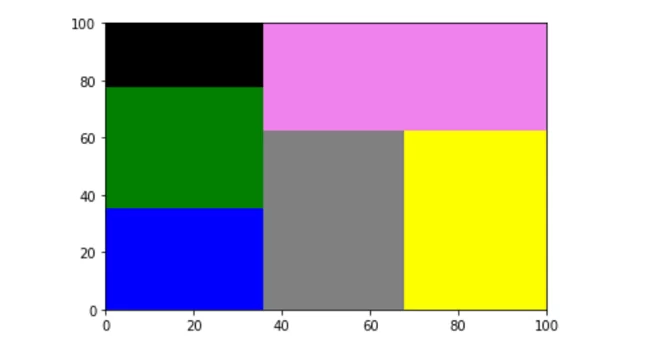
Создадим treemap-диаграмму для списка значений данных с использованием соответствующего списка цветов. Причем, длина списка цветов (не в нашем случае) может не совпадать с длиной данных, и в таком случае цвета на диаграмме повторялись бы.
Метод plot построит квадрат размером 100×100.
# treemap со списком цветов
data_value=[500, 600, 320, 790, 800, 960]
clrs=['blue','green','black','grey','yellow','violet']
squarify.plot(sizes= data_value, color=clrs)
Вот результат (по умолчанию диапазон диаграммы 100 х 100):
Tremmap-диаграмма с цветовой палитрой
Теперь, используя те же данные, импортируем модуль seaborn, для выбора цветовой палитры. Аргумент alpha – для применения прозрачности диаграммы – число в диапазоне от 0 до 1 (чем ближе к 0, тем больше прозрачность).
import seaborn as sb
# treemap-диаграмма с цветовой палитрой и
squarify.plot(sizes=data_value, color=sb.color_palette('Spectral',len(data_value))
,alpha=0.7)
# не используем в выводе отображение осей X,Y
plt.axis('off')
Результат ниже:
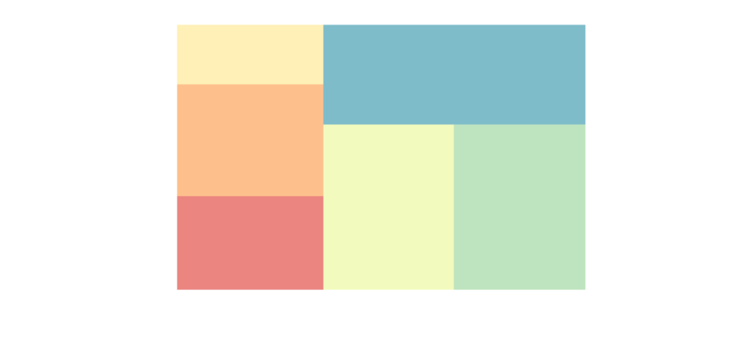
Масштабирование Treemap-диаграммы
Масштаб используется для изменения диапазона диаграммы. Используя аргументы norm_x и norm_y можно масштабировать данные по оси X и Y соответственно.
# масштабируем treemap-диаграмму
data_v = [300, 50, 70, 3000]
clrs = ['blue','yellow','green','red']
squarify.plot(sizes=data_v, norm_x=1000, norm_y=10, color=clrs)
plt.axis('off')
В итоге получаем вот такую treemap-диаграмму:

Метки и пробелы
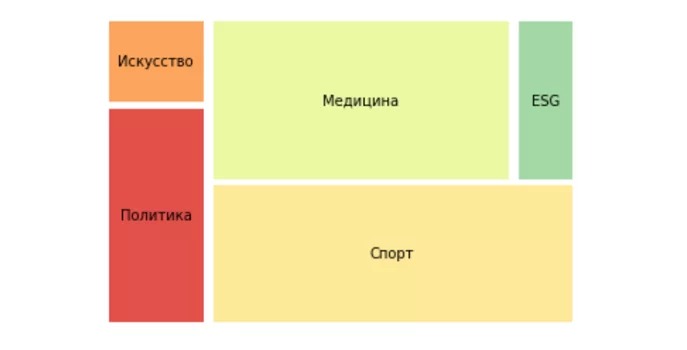
Согласитесь, что treemap-диаграмма без меток выглядит как схема из блоков, смысл которой не совсем понятен. Применение же меток поможет обозначить, что представляют собой конкретные графики. Кроме того, в следующем коде используем аргумент pad, принимающий целочисленные значения и добавляющий пробелы между элементами treemap-диаграммы для улучшения восприятия визуализации. Вот пример кода, который демонстрирует это:
# treemap-диаграмма просмотра разделов новостей
number_of_views = [205, 82, 467, 450, 92]
news = ['Политика', 'Искусство', 'Спорт', 'Медицина', 'ESG']
squarify.plot(number_of_views, label=news, pad=2, color=sb.color_palette('Spectral'))
plt.axis('off')
Сейчас результат гораздо понятнее:
Treemap-диаграмма на основе данных из файла
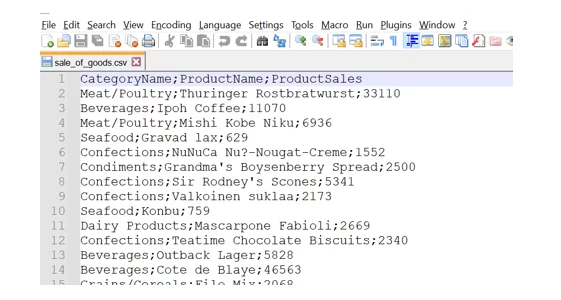
Давайте наконец посмотрим, как построить treemap-диаграмму на основе данных из загружаемого csv-файла, в котором содержится информация о продаже товаров. Фрагмент файла, открытого в Notepad++, представлен ниже.
# импортируем необходимые модули
import squarify
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sb
# создаем DataFrame
data = pd.read_csv('C:/Users/Projects/sale_of_goods.csv', sep = ';')
df = pd.DataFrame(data)
И затем построим treemap-диаграмму, отражающую популярность товаров у покупателей (дополнительный агрумент text_kwargs задает размер шрифта для меток):
# создаем treemap-диаграмму
plt.figure(figsize=(10, 5))
axis = squarify.plot(df['CategoryName'].value_counts(),label=df['CategoryName'].value_counts().index,
color=sb.color_palette("nipy_spectral",len(df['CategoryName'].value_counts())),
pad=1,text_kwargs={'fontsize': 14})
axis.set_title('Популярность товаров по категориям', fontsize=24)
plt.axis('off')
Treemap-диаграмма выглядит следующим образом:

Как видите, использование библиотеки squarify дает возможность визуализировать данные о видах товаров, предлагаемых клиентам, что позволяет наглядно оценить долю каждой категории в общем объеме и сделать выводы (в данной задаче) о потребительском интересе.
Treemap-диаграмма хорошо применима, когда данные имеют два основных измерения, которые необходимо визуализировать: это количественное значение, выраженное как площадь прямоугольника (значение должно быть положительным) и категориальное значение, которое выражается в виде цвета отдельных прямоугольников. Treemap-диаграмма не подходит для задач, где выполняется точное сравнение данных.
В аудиторской практике, например, мы использовали treemap чтобы оперативно представить, как распределены доходы сотрудников кампании по блокам/департаментам. Конечно, выбор способа визуализации зависит от многих факторов и условий, в этом материале показан лишь один из них. Вы можете самостоятельно поэкспериментировать с treemap на больших данных и сделать выбор в пользу этого или иного варианта построения диаграммы.
Дополнительный материал по squarify о построении treemap-диаграммы для подгрупп можно найти по ссылке https://github.com/laserson/squarify/pull/31.