/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
Когда мы исследуем процесс, построенный из лога, нам бывает интересно посмотреть, как выглядит процесс, в котором отсутствуют лишние переходы, циклы, т.е. «идеальный» процесс. Такая возможность реализована на платформе celonis — функция happy path. Данная функция позволяет построить «идеальный (счастливый) путь», т. е. последовательность часто встречающихся активностей.
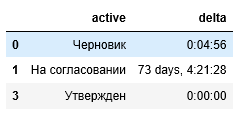
В celonis результат работы данного инструмента выглядит так:

Я предлагаю свой вариант реализации данного инструмента на Python.
Начнем с импорта Pandas и чтения данных. Записываем в датафрейм, сразу переводим столбец date в datetime и сортируем по трем столбцам.
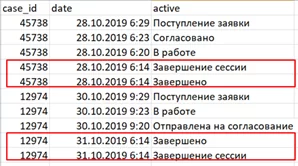
Сортируем по трем столбцам, чтобы последовательность действий всегда была одинаковая. На рисунке ниже представлены 2 заявки, действия «Завершение сессии» и «Завершено» происходят одновременно. В системе последовательность этих активностей может быть записана по-разному, как в нашем примере. Чтобы привести лог к единому виду, мы и используем фильтрацию по столбцу «active»
import pandas as pd
import datetime
happy_path = pd.read_csv('log.csv', sep = ';', encoding = 'cp1251')
happy_path['date'] = pd.to_datetime(happy_path['date'], yearfirst = True)
happy_path = happy_path.sort_values(['case_id', 'date', 'active'])
Формируем новый столбец, содержащий название следующей активности. В конце каждой заявки проставляем «end» и нумеруем активности в пределах каждой заявки.
happy_path['next_activity'] = happy_path.groupby('case_id')['active'].shift(-1)
happy_path['next_activity'].fillna('end', inplace=True)
happy_path = happy_path[happy_path['active']!=happy_path['next_activity']].reset_index(drop = True)
happy_path['cum_count'] = happy_path.groupby('case_id').cumcount()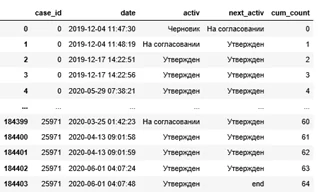
В новый датафрейм записываем все действия, с которых может начинаться и заканчиваться заявка.
start_end = happy_path[(happy_path['cum_count']==0)|(happy_path['next_activity']=='end')]
start_end.loc[start_end['cum_count']==0, 'next_activity']='start'
Выбираем top 1 активность начала и конца. Записываем в переменные start и end соответственно.
start_end_group = start_end.groupby(['active','next_activity'],as_index = False).agg({'cum_count':'count'}).reset_index(drop =True)
end = start_end_group[start_end_group['cum_count'] == start_end_group[start_end_group['next_activity']=='end']['cum_count'].max()]['active'].iloc[0]
start = start_end_group[start_end_group['cum_count'] == start_end_group[start_end_group['next_activity']=='start']['cum_count'].max()]['active'].iloc[0]

Далее нам нужно получить список case_id, которые начинаются и заканчиваются нужными нам действиями (Черновик и Утвержден).
start_end['next_activity'] = start_end.groupby('case_id')['active'].shift(-1)
start_end = start_end.drop_duplicates(subset = 'case_id', keep = 'first')[['case_id','active','next_activity']]
hp = list(start_end[(start_end['active']==start)&(start_end['next_activity']==end)]['case_id'])

Возвращаемся к нашему датафрейму happy_path и оставляем только те заявки, номера которых присутствуют в списке hp.
happy_path = happy_path.query('case_id in @hp') Дальше будем работать с датами. Столбец, содержащий следующую активность у нас есть, добавим к нему дату и рассчитаем длительность каждой активности
happy_path['next_date'] = happy_path.groupby('case_id')['date'].shift(-1)
happy_path['next_date'].fillna(happy_path['date'], inplace=True)
happy_path['delta'] = happy_path['next_date']-happy_path['date']
Считаем медиану для каждого перехода.
happy_path['delta_seconds'] = happy_path['delta'].dt.total_seconds()
start_end = happy_path.groupby(['active', 'next_activity'], as_index = False)['delta_seconds'].median()
start_end['delta'] = start_end['delta_seconds'].apply(lambda x: str(datetime.timedelta(seconds = x)))
Посчитаем сколько заявок содержат те или иные переходы. И оставляем только самые частые.
activ_step = happy_path.groupby(['active', 'next_activity','cum_count'], as_index = False)['case_id'].count()
activ_step['max'] = activ_step.groupby(['active'], as_index = False)['case_id'].transform('max')
activ_step = activ_step[activ_step['case_id']==activ_step['max']][['active','next_activity', 'cum_count']]
У нас остается всего 5 переходов (маловато, но наш лог содержит всего 4 активности: Черновик, На согласовании, Возвращено на доработку, Утверждено)
Переходим к завершающему этапу. Добавляем длительность перехода к полученному датафрейму.
activ_step = activ_step.merge(start_end, how= 'left', on = ['active','next_activity'])
activ_step = activ_step.sort_values('cum_count').reset_index(drop = True)
Осталось выстроить переходы в нужной последовательности, для этого я использую следующий цикл.
max_ind = activ_step.index.max()
s = 0
activ_step['ind_2']=0
for i in activ_step.index:
if i == 0:
s +=1
activ_step['ind_2'].loc[i]=s
if max_ind==i:
break
if activ_step['next_activity'].loc[i]==activ_step['active'].loc[i+1]:
s+=1
activ_step['ind_2'].loc[i+1]=s
else:
for j in activ_step.index[i:]:
if activ_step['next_activity'].loc[i]==activ_step['active'].loc[j]:
s+=1
activ_step['ind_2'].loc[j]=s
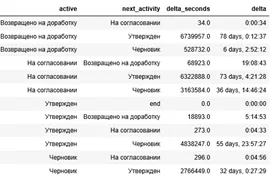
activ_step = activ_step[activ_step['ind_2']!=0].sort_values('ind_2')[['active', 'delta']]
Смотрим полученный результат. Активность «Возвращено на доработку» исключена из финального датафрейма и это правильно, т.к. в «идеальном» процессе заявки на доработку не возвращают 😊