/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 7 мин.
Введение:
Зачем вообще упрощать текст? Есть, как минимум, три кейса, почему есть вероятность столкнуться с этой задачей:
— если перед вами текст на иностранном языке, то замена «сложного» слова на синоним поможет сориентироваться в сути предложения
— если вы работаете с доменной тематикой, то также подбор синонимов может сделать текст проще для восприятия (так, например, «ирригация» можно заменить на «орошение» и наоборот, в таком случае шанс понять текст у читающего увеличивается)
— для расширения датастета: аугментация текстовых данных – это всегда вызов, важно учитывать контекст для того, чтобы подобрать синоним. Тут, конечно, важно учитывать размер корпуса, частота встречаемости слов в рамках контекста будет точнее, если корпус состоит из миллионов предложений, а не из тысяч.
Если говорить более предметно, то это задача делится на две: поиск сложного слова или словосочетания и поиска его замены, исходя из контекста. Давайте последовательно разберемся с каждой из задач.
Если кому-то интересно ознакомиться только с кодом, то welcome на github, там можно найти пошаговую реализацию.
Задача выделения сложных слов
Для англоязычного nlp-сообщества задача поиска сложного слова в тексте называется так: CWI – complex word identification. Это класс задач, который требует отдельного раскрытия и погружения. Существует датасет для решения этой задачи, но он на английском, история его сбора и разметки, а также ссылка на скачивание тут.
В этой статье основной фокус смещен на вторую часть, где производится подбор замены слова, а не его детекция, сложные слова мы определили по нескольким критериям:
— количество слогов
— частота встречаемости (определяется библиотекой wordfreq)
Итак, для примера, будем использовать новостной датасет сайта lenta.ru, этот датасет собран под другую задачу, но в качестве примера подойдет и нам, потому что многие русскоязычные аналоги западных реализаций моделей тренировались, в том числе, на срезе новостного корпуса медиа.
Каждая новость лежит под отдельным id-номером и состоит из нескольких предложений. С помощью библиотеки razdel мы провели токенизацию двух уровней: на предложения, а затем на слова. Затем мы отобрали слова, в которых больше 3-х слогов, разбивка по слогам происходила по гласным. Далее мы посмотрели, какова встречаемость сложных слов в нашем корпусе с помощью wordfreq и таким образом составили признак «сложные слова».
Задача поиска слова для упрощения
- Ru-BERT: почему работает на английском, но не работает на русском
Английская модель BERT замечательно справится с задачей подбора контекстного синонима. В сети есть множество примеров решения задачи Lexical Simplification with BERT, но использовать тот же подход для русского языка «в лоб» нельзя, так как модели на самом деле сильно отличаются.
Англоязычный BERT натренирован на текстах английского языка, его матрица embedding-ов с весами действительно, при подборе слова для решения задачи MLM (masked language modelling), будет ориентироваться на «близость» слов относительно заданного контекста.
Ru-BERT, созданный лабораторией DeepPavlov, обучался по-другому. «Под капотом» ru-BERT скрывается Multilingual-BERT, его словарь включает в себя не только русские и английские токены и сабтокены, в нем есть также и иероглифы, матрица embbeding-ов тоже не ограничена только русскими токенами/сабтокенами. Ru-BERT получен методом transfer-learning с мультиязычного аналога, а затем его веса в матрице embedding-ов были тонко настроены под задачу решения MLM на корпусе русских текстов. Поэтому, если мы будем решать задачу MLM «из коробки» с ru-BERT, результаты замены мы получим примерно такой:
Исходный текст:
Как повлияло вступление в ВТО на конкурентноспособность российской промышленности какие угрозы и преимущества несет членство в организации и как России правильно играть по ее правилам чтобы выиграть обсудили участники круглого стола Вступление России в ВТО и повышение конкурентоспособности российской промышленности в рамках петербургского форума
Замена:
{‘Hg’, ‘мужества’, ‘справа’}
Для BERT можно повторно провести Transfer-Learning и дистилляцию, сократить словарь, матрицу векторных представлений без потери качества на вашем домене текста, но «это уже совсем другая история».
а на вашем домене текста, но «это уже совсем другая история».
- Word2Vec: плюсы и минусы подхода
Первый минус, с которого можно начать рассказ о W2V – это то, что в отличие от BERT ни при какой модификации модель не учитывает контекст слов, только заданное окно, в котором можно посмотреть вероятность встречаемости слов вместе.
Важным ограничением будет следующее: модель тюнится под используемый вами корпус, и в случае, если слишком сильно ограничить модель параметрами (например, встречаемостью слова в тексте), то велика вероятность, что модель не сможет подобрать замену слову, потому что оно окажется вне используемого словаря слов.
Код для реализации:
from gensim.models import Word2Vec
sentences_w2v = exploded.drop_duplicates(subset = ['clear_sentences'])
sentecnes = sentences_w2v['words'].to_list()
w2v_model = Word2Vec(min_count=2, window=3, size=300, negative=10, alpha=0.03, min_alpha=0.0007, sample=6e-5, sg=1)
w2v_model.build_vocab(sentences)
w2v_model.train(sentences, total_examples=w2v_model.corpus_count, epochs=30)
Обратимся к уже использованному примеру:
w2v_model.wv.most_similar(positive=['промышленность'])Исходный текст:
Как повлияло вступление в ВТО на конкурентноспособность российской промышленности какие угрозы и преимущества несет членство в организации и как России правильно играть по ее правилам чтобы выиграть обсудили участники круглого стола Вступление России в ВТО и повышение конкурентоспособности российской промышленности в рамках петербургского форума
Замена:
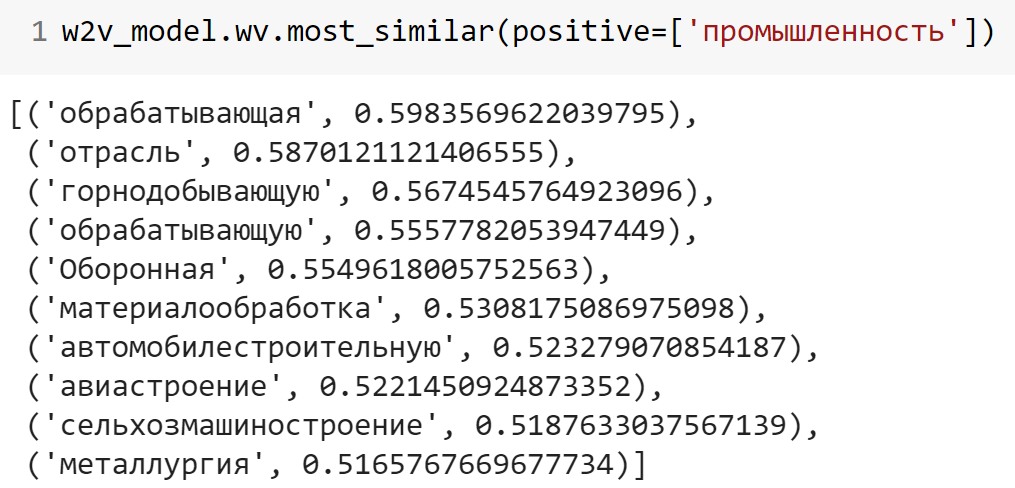
Можно настроить отбор по части речи, тогда из выдачи можно будет убрать все слова, кроме существительных и попытаться подобрать замену. Нужно сказать, что часть слов («отрасль» и «материалообработка») действительно могут претендовать на замену.
- Альтернатива: Rus-Vectores
В общем и целом, это векторные представления слов для русского языка (word2vec для русского языка на большом количестве данных), которые были обучены почти на 13 миллиардах (!) словоупотреблений. Так как метод в основе использует word2vec он перенимает все те же минусы относительно окна контекста, что есть у исходной версии.
Так как корпус текстов, на которых проводилось обучение, сильно больше, чем тот набор, который скорее всего вы можете предложить модели для решения задачи, вероятность того, что слово, которое вы укажете для замены, не найдется в словаре сильно меньше, чем если дообучать w2v. Конечно, это работает только в том случае, если вы работаете с текстами общей, а не доменной тематики.
В основе поиска, подходящего для замены слова, используется несколько моделей:
— контекстуализированные модели
— статические модели
— целые корпуса русских текстов
При задании параметров поиска «похожего слова» пользователь выбирает, на какой корпус/корпуса ориентироваться сервису: можно выбрать несколько, а также указать части речи, которые необходимо отобразить в качестве релевантной выдачи. Очень подробный туториал о препроцессинге и в принципе работе с сервисом доступен в репозитории проекта.
У сервиса есть API, по которому можно автоматизировать поиск слов для замены. API работает для решения двух задач:
— получение списка семантически близких слов для заданного слова в заданной модели
— вычисление коэффициента косинусной близости между парой слов в заданной модели В параметрах запроса нужно указать модель, которую нужно использовать для поиска замены слова, формат ответа, а также само слово с указанием части речи через нижнее подчеркивание.
import requests
MODEL = 'ruscorpora_upos_cbow_300_20_2019'
FORMAT = 'csv'
WORD = 'вашеслово_POS’
def api_neighbor(m, w, f):
neighbors = {}
url = '/'.join(['http://rusvectores.org', m, w, 'api', f]) + '/'
r = requests.get(url=url, stream=True)
for line in r.text.split('\n'):
try: # первые две строки в файле -- служебные, их мы пропустим
word, sim = re.split('\s+', line) # разбиваем строку по одному или более пробелам
neighbors[word] = sim
except:
continue
return neighbors
Как итог, мы получим список слов для замены, в котором потом самостоятельно можно отобрать нужную часть речи.
Исходный текст:
Как повлияло вступление в ВТО на конкурентноспособность российской промышленности какие угрозы и преимущества несет членство в организации и как России правильно играть по ее правилам чтобы выиграть обсудили участники круглого стола Вступление России в ВТО и повышение конкурентоспособности российской промышленности в рамках петербургского форума
Замена:
{‘отрасль_NOUN’: ‘0.7330350279808044’, ‘производство_NOUN’: ‘0.6855677366256714’, ‘машиностроение_NOUN’: ‘0.6785974502563477’, ‘индустрия_NOUN’: ‘0.6733304262161255’ … }
Вывод: Без значительных трансформаций из-за условия тренировки ru-BERT невозможно «из коробки» подобрать релевантную замену для отдельных слов в русскоязычных текстах. Если задача позволяет использовать корпус обучения, а также пожертвовать ограничением контекста и передавать некоторое окно слов, то можно использовать предобученные представления слов word2vec и искать слова по косинусной мере. В случае, когда нет ресурса на обучение (это может быть размер корпуса или ресурсов), то можно воспользоваться русскоязычной адаптацией W2V – RusVectores, которые по нашему опыту подбирают весьма неплохие варианты для замены слов в предложениях.