/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 3 мин.
Владение языком — важнейшая человеческая способность, которая отличает его от обезьяны. Способность понимать человеческий язык является одной из главных составляющих искусственного интеллекта. За последние несколько лет, мы наблюдаем стремительный рост технологий, связанных с машинной обработкой естественного языка. Google, Microsoft и Яндекс являются лидерами в данной области. Обладая базовым уровнем знаний Python, возможно реализовать проект по машинной обработке речи.
Как машинная обработка речи может быть связанна с работой финансовой организации?
Телефонный звонок до настоящего времени остается основным способом коммуникации клиента и финансовой организации. Практически все звонки для контроля записываются, а это миллионы звонков в год (МИЛЛИОНЫ, КАРЛ!). Например, база переговоров брокеров и клиентов за период чуть больше полугода составляет около 200 тысяч аудиофайлов общей продолжительностью порядка 7 тысяч часов или 300 дней! И это лишь небольшая часть от общего количества звонков.
Как обработать такой объем данных?
Обрабатывать такой объем информации прослушиванием – нерационально. Поэтому командами аудиторов был создан инструмент с использованием библиотек Python, позволяющий обрабатывать общение брокеров с клиентами.
Как проводить контроль выполнения правил и стандартов в финансовой организации? При анализе диалога клиента и брокера контролируется наличие поручений клиента по покупке/продаже и наличие запроса пароля от брокера. Например, ищем ключевые слова в аудиозаписи – «покупка», «продажа», «пароль». Ключевые слова позволят нам оценивать выполнение стандартов общения с клиентом, правильность выполнения операций и соблюдения требований по безопасности.

На рис.1. показана разметка двух аудиозаписей, где были найдены ключевые слова:
— в первом аудиофайле было найдено слово «Покупка» на 47 секунде.
— во втором аудиофайле были найдены слова «Продажа», «Покупка» и «Пароль».
Также с использованием аудиоданных из переговоров клиента и брокера возможно сопоставить данные позвонившего клиента, полученные с помощью инструмента с данными клиента из анкеты. Для этого проводим диаризацию аудиофайла переговоров с помощью модуля librosa языка Python. Модуль осуществляет определение речи в аудио и выделение участников диалога на основе извлечения признаков речи. Определив участников диалога, мы можем: 1) выявить заявки, по которым пол позвонившего и пол клиента не совпадают,
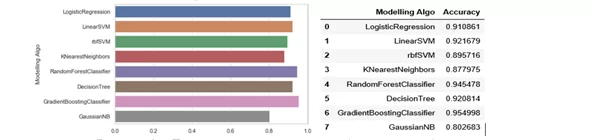
Рисунок 2 – Точность реализованных моделей по определению пола
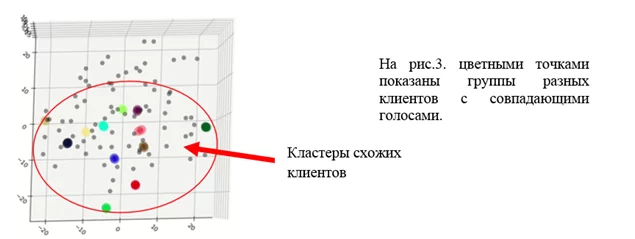
2) выявить разных клиентов, заявки которых поданы одним и тем же голосом.
Реализуя в коде вышеприведенную последовательность действий, Вы убедитесь, что любой, обладающий базовыми знаниями языка Python, а также навыком чтения документации для использования готовых библиотек, способен реализовать продукт по машинной обработке речи, сопоставимый по качеству с решениями лидеров рынка.